基于噪声伪标签和对抗学习的医学图像分割标注高效学习
目录
背景:
面临问题:
解决方案:
一 没有图像标注对的学习
二 为训练图像生成伪标签
2.1 为训练图像生成伪标签
2.2 VAE-Based鉴别器
2.3 鉴别器引导的发生器信道校准
这里有不太理解 (未写完)
三 从嘈杂的伪标签学习
四 讨论与总结:
五 本次论文学习的问题与不理解之处:
背景:
医学图像分割对于脏器建模、肿瘤准确诊断、定量测量、手术规划等广泛的临床应用具有重要意义。目前,基于卷积神经网络(Convolutional Neural Networks, CNNs)的深度学习在医学图像分割任务上取得了很大的成功,它们的成功在很大程度上依赖于大量训练图像的可用性,以及专家给出的手工注释。
面临问题:
医学图像分割中难以获得大量的人工标注,因为对分割任务进行像素级标注费时且需要具有领域知识的专家来实现。因此,获取高质量的人工标注进行训练成本高、劳动强度大,成为开发用于医学图像分割任务的深度学习模型的主要障碍。
解决方案:
已有的一些解决方案:无监督、每周监督和基于域适应的方法,但这些方法仍有不足之处,仍需要大量的人工进行标注。
这篇文章从三个方面去尽量解决这个问题
1 一种新的深度学习框架
出了一种新的高效标注的深度学习框架用于医学图像分割,其中模型从一组辅助掩码学习,这些辅助掩码很容易获得,并且与我们的训练图像不配对,因此不需要对每个训练图像进行人工标注。该框架由伪标签生成模块和迭代学习模块组成,前者为每个训练图像获取初始伪分割标签,后者对初始伪标签中的噪声具有鲁棒性
2 VAE鉴别器与 生成器通道校准(DGCC)模块
了获得高质量的伪标签,我们提出了一种基于vae的鉴别器,鼓励对伪标签进行高水平的形状约束,并提出了一个鉴别器引导的生成器通道校准(DGCC)模块,利用鉴别器的反馈对伪标签生成器的通道信息进行校准。
3 新的迭代噪声鲁棒训练方法
提出了一种新的迭代噪声鲁棒训练方法来学习伪标签,该方法通过基于标签质量的样本选择(LQSS)模块拒绝低质量的伪标签,并提出噪声加权骰子损失来提高最终分割模型的性能。
总体结构示意图:
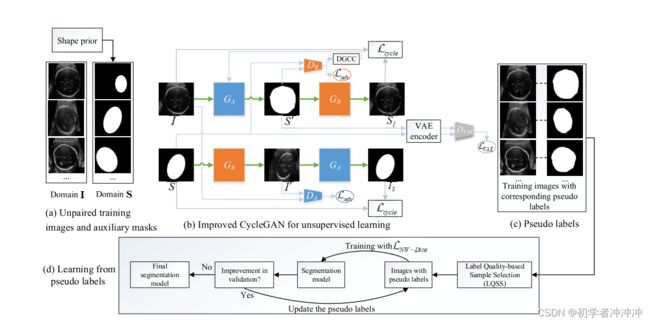
上图 综述了我们提出的用于医学图像分割的高效标注深度学习方法。a)我们使用一组与训练图像不配对的辅助面具(例如,从胎儿头部分割的形状先验模型中获得)进行训练。(b)改进的CycleGAN从未配对的图像和辅助掩模中学习,获得每个训练图像对应的伪标签,其中提出了基于vaes的鉴别器和DGCC模块,以获得更好的性能。(c)训练集的伪标签。(d)采用噪声鲁棒迭代学习方法,利用伪标签训练最终的分割模型。
下面来分别看看这3个方面:
一 没有图像标注对的学习
I和S分别表示医学图像域和分割掩码域。不同于标准的基于cnn的图像分割方法,需要手动提供来自S的样本,以便它们与来自I的图像配对,我们从I和S的两个未配对集合中得知,它可以有效地从第三方源生成或收集一组辅助掩码,而不是从i中标注训练图像。
首先,考虑到在某些应用中,分割面具具有较强的形状先验(如胎儿头部),我们利用形状模型从分割面具域生成一组随机样本。具体来说,在我们的胎儿头部和视盘分割任务中,分割目标是一个椭圆。该随机生成的样本和形状并不对应于任何真实的训练图像,即我们得到的是未配对的训练图像和随机版。图1(a)显示了我们为胎儿头部生成的随机面具的一些例子。
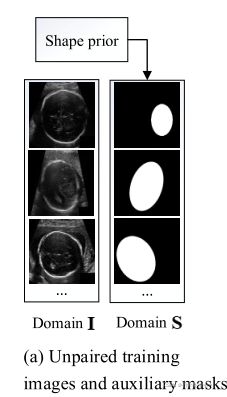
其次,对于更复杂的难以建模的分割结构(如肺和肝脏),当这种辅助掩模样本可以从其他来源(如公共数据集)获得时,我们可以直接使用一组来自掩模域的样本(与训练图像不配对)进行训练。请注意,一旦从S域获得了一组与训练图像未配对的辅助掩码,下面的训练过程对于这两种情况是相同的。
总结就是:
1. 对于简单的形状我们可以使用形状模型进行生成
2. 对于复杂的模型我们则使用其他的来源,例如(公共数据集)
二 为训练图像生成伪标签
2.1 为训练图像生成伪标签
对于未与我们的未标注训练图像配对的辅助遮罩,我们通过对抗训练利用它们的高级形状信息来约束生成器Ga,以便Ga为具有与辅助遮罩相同的形状分布的训练图像生成伪标签。如图1(b)所示

给定I域的医学图像I和S域的辅助掩模S,我们使用伪标签生成器GA将I转换为对应于I的二进制掩码S1= GA(I)(即伪标签),S1由图像生成器GB转换回医学图像Is = GB(S1),相反,GB将S域的辅助掩码样本S转换为S对应的伪医学图像I 1= GB(S),I1被转换回二进制掩码Si = GA(I1)。循环一致性损失,阻止生成器产生与I和Is之间的输入无关的结果(S和Si也一致),计算为:
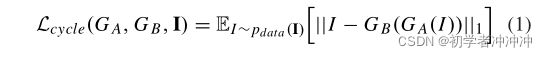
pdata(I)是域I的分布,鼓励S和S1的分配相匹配,

pdata(S)是域S的分布,DB是一个基于patch的鉴别器,它将输入的每个patch与域S区分为真实 的或假的patch。
对抗损耗是为了克服初始GAN损耗的消失梯度问题而提出的最小二乘对抗损耗,DB用来评估伪标签S的质量。类似地,我们使用另一个鉴别器DA来区分它的输入是真实的还是虚假的医学图像。原始的鉴别器在输出一个单一的标量,只指示输入掩码是真实的还是伪造的作为一个整体,没有给出非局部区域的细节。相比之下,基于patch的鉴别器可以更好地显示生成器输出中子区域的质量。因此,本文采用基于patch的鉴别器来实现DA和DB。
2.2 VAE-Based鉴别器
与常规图像不同,伪分割标签中的像素值不复杂、稀疏,可以通过潜向量将其转换为更紧凑的表示。例如,椭圆型掩模可以通过指定椭圆的大小、位置和方向的低维向量很好地表示。此外,与仅在非常高维的情况下区分原始伪分割标签相比,区分紧致的低维潜向量有可能获得更好的性能。
因此,我们提出利用VAE将二值掩码S和S1分别转换为其潜在向量表示zr和zf。然后,我们应用一个带有三个线性层和泄露ReLU的鉴别器DVAE来区分它们。VAE是一个编码器-解码器网络,其中编码器网络将输入映射为一个低维潜向量,解码器网络尝试重构输入。我们通过强制潜向量服从均值为零、方差为1的高斯分布来正则化编码器。由于V AE的作用是将二维图像空间中的分割掩模转化为一个潜向量的压缩表示,我们使用辅助掩模对V AE进行预训练。在预训练时,以一个辅助掩码作为输入,其解码器将该辅助掩码重构为输出。KL散度损失和L2损失结合Adam优化器进行训练。经过预训练后,我们固定VAE并使用其编码器获得一个输入分割掩码的紧凑表示,并发送到我们的DVAE中。DVAE的对抗损失可以写成:

其中Zf、Zr分别是Zf、Zr的集合。pdata(Zf), pdata(Zr)是Zf, Zr的分布

图 2. 我们的伪标签生成器 GA 的图示,它由鉴别器 DB 通过我们的 DGCC 模块的反馈进行校准。引入了另一个鉴别器 DVA E 来评估在高级紧凑表示中生成的伪标签的质量。
总体损失总结为:

其中,λVAE, λadv和λcycle控制三项的相对权重
2.3 鉴别器引导的发生器信道校准
在标准GAN中,鉴别器通过反向传播的损失函数反馈给发生器,只能用于训练,即间接反馈和隐式反馈。由于基于patch的鉴别器DB可以识别伪标签S的一个patch是真还是假,并且可以学习到典型的表示特征,DB的feature map有可能显式地指导Ga获得更好的结果。此外,由于鉴别器的性能明显优于生成器,因此利用DB的特征图进行校准时,生成器G可以学习得更好、更快。因此,我们提出了一个鉴别器引导的发生器信道校准(DGCC)模块来提高天线的性能,如图1(b)所示,我们使用四个DGCC模块分别在四个尺度上校准天线的特征
在我们的DGCC中,利用鉴别器的反馈导致循环连接。设T为各回路连接的总圈数,如图2所示。在第1轮,发生器GA没有从鉴别器DB反馈。在接下来的几个弯道,我们将DB在t弯道输出层前的嵌入特征图作为我们的反馈信息。
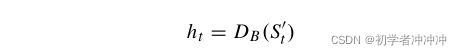
这里有不太理解 (未写完)
三 从嘈杂的伪标签学习
用上述的未配对图像和随机蒙版进行训练后,G A可以用来预测每个训练图像对应的伪分割标签。使用这些伪标签,可以使用一个监督训练管道来训练一个分割模型,比如U-Net[20],使用标准的Dice损失。然而,与标准监督训练的标签不同,我们的伪标签是有噪声的和不准确的。为了解决这个问题,我们提出了一个从GA给出的噪声伪标签学习的两步框架,如图1(d)所示

首先,我们提出了一种基于标签质量的样本选择(Label quality -based Sample Selection, LQSS)方法,自动拒绝低质量的伪标签,只保留高质量的伪标签;根据GAN一个训练良好的识别器DB可以指示其输入的是来自分割掩码域的真实样本还是假样本,我们基于patch的鉴别器DB的输出是一个N × N的矩阵,其中每个元素表示对应patch的质量。取该矩阵的平均值作为对应伪分割标签Yi的图像级质量分值Ri,具有伪标签的训练集T可以表示为T = {(I1, Y1, R1), (I2, Y2, R2),…(in, yn, rn)}。LQSS后的训练集为:
![]()
其中α是伪标签质量分数的阈值,设为T中Si的75%。
第二步:
在第二步中,从所选图像优质伪标签,我们使用迭代训练过程与K轮,每一轮包括1)更新分割模型通过学习从伪标签和2)预测培训新的伪标签使用当前的图像分割模型,当在验证集上没有提高分割性能时,他将停止轮取。在分割模型更新的步骤中,考虑到伪标签中的一些像素是有噪声的甚至是离群值,这会严重破坏分割模型,我们提出基于估计的噪声水平对每个像素进行加权。由于错误标签的样本容易造成较高的损耗值,我们将较小的权值分配给训练误差较大的像素,以减少潜在的噪声标签的影响。噪声加权骰子损失表示为:
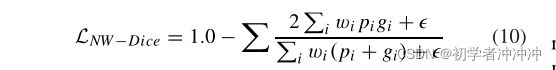
式中= 10−5为数值稳定性的小数值。PI和gi分别为像素I在分割结果和伪标签中的前景概率。权值wi定义为:

四 讨论与总结:
在医学图像分割任务中,大量高质量的人工标注是一项困难且劳动密集型的任务,这是发展深度学习方法的关键障碍。为了缓解这个问题,一些作品已经研究了高效标注的分割方法,但仍需要对训练集进行一些人工标注。虽然之前也有一些通过深度表示学习来研究无监督(即无注释)分割的工作,但它们的分割精度是有限的。本文提出了一种新的框架学习,从一组未配对的训练图像和辅助蒙版,可以很容易地通过形状先验信息或公开可获得的数据集在可能不同的领域。在辅助蒙版的帮助下,我们通过改进的CycleGAN为每个训练图像生成一个伪分割标签,并将伪标签与我们的噪声鲁棒学习过程相结合,得到最终的分割模型。
改进后的CycleGAN可以生成高质量的伪标签,原因如下:首先,辅助口罩是基于形状先验信息或公共数据集,提供目标器官的形状分布。它们被我们的敌对网络用来对伪标签施加形状约束。其次,我们的DGCC模块使用鉴别器的特征图直接校准伪标签生成器,以获得更好的性能。
我们的基于vae的鉴别器的优点是它可以自动学习紧凑的高级形状表示,并且可以很容易地基于辅助遮罩进行训练。VAE的潜向量是对物体形状的隐式建模,有助于约束发生器。尽管所切割器官的形状不同,但其超参数保持一致,即载体长度为32,λVAE值为1.0。结果表明,该方法在所有的分节器官中都是有效的和普遍的。然而,在其他应用中,如处理3D图像或分割船只,这些参数可能需要根据特定的数据集进行调整。可以用带有手动形状约束的编码器来代替VAE。而后者依赖于研究人员的经验,对于复杂的形状很难找到有效的手工约束。
分割模型可以使用我们的ga获得的伪标签进行训练,但是这些标签是有噪声的,并且不是很准确。我们通过噪声鲁棒学习过程克服了这个问题,其中伪标签和最终分割模型是迭代更新的。通过剔除低质量的伪标签,根据Dice loss函数中估计的噪声水平对像素进行加权训练,减轻了噪声标签的影响,从而得到高性能的分割模型。我们的噪声鲁棒学习方法也可以用于存在噪声标签的其他情况,如半监督学习和从非专家标注学习
我们提出的框架可以利用辅助掩码的形状信息分割医学图像,而无需为训练图像添加昂贵的注释。我们的基本假设是,不需要额外的努力,就可以获得一些与目标对象类相关的辅助掩码,而不是与训练图像对应的标注。辅助掩模提供了目标的一些形状信息,并且不与训练集配对。我们展示了这两种可能的方法来获得这样辅助面具:使用参数化形状模型生成一组辅助面具视神经盘等简单的结构和胎儿的头,和利用面具从另一个域的对象(例如,公共数据集)等复杂结构的肺和肝。对于更复杂的结构,如大脑和血管利用来自不同数据集的现有未配对标签进行形状约束可能更具挑战性。我们的方法在这种情况下的有效性将在未来进行调查。本文的方法是在二维网络上实现的,理论上也可以采用其他网络结构,并可以推广到三维图像处理中。
最后,我们提出了一种新的训练框架,利用一组辅助掩码进行医学图像分割。提出了一种改进的CycleGAN算法,用于从未配对的医学图像和辅助面具学习,对抗学习利用辅助面具对生成的训练图像的伪标签引入形状约束。为了提高伪标签发生器的性能,我们引入了基于vae的鉴别器和基于鉴别器引导的发生器信道校准(DGCC)。我们还提出了一种噪声鲁棒的迭代训练方法来从有噪声的伪标签中学习,其中引入了基于标签质量的样本选择(LQSS)模块和噪声加权的骰子损失来克服有噪声的标签。实验结果表明,我们的方法获得了准确的分割结果,与人工标注训练的相同CNN结构接近甚至可以媲美。该框架为避免人工标注训练图像提供了一种可行的解决方案,未来我们将研究其在其他结构分割中的应用。
五 本次论文学习的问题与不理解之处:

