关于2018-learning-based video magnification 的GitHub上复现代码的调试记录
题记:关于2018-learning-based video magnification 的GitHub上的复现代码的调试记录
GitHub上的复现的代码:GitHub - ZhengPeng7/motion_magnification_learning-based: An unofficial implementation of "Learning-based Video Motion Magnification" in Pytorch.
注意:本人只对测试程序进行了调试,不涉及模型训练(不涉及训练数据集)。
调试代码可查阅:关于2018-learning-basedvideomagnification的GitHub上复现代码的调试记录及调试代码-互联网文档类资源-CSDN下载
####################################
1 调试2018-learning-VM的过程记录:
0 所使用的pytorch环境是已有的anaconda创建的环境的复制重命名环境,然后在该新环境中进行的代码调试。
(PS:使用的是anaconda的命令行窗口以及pycharm软件)
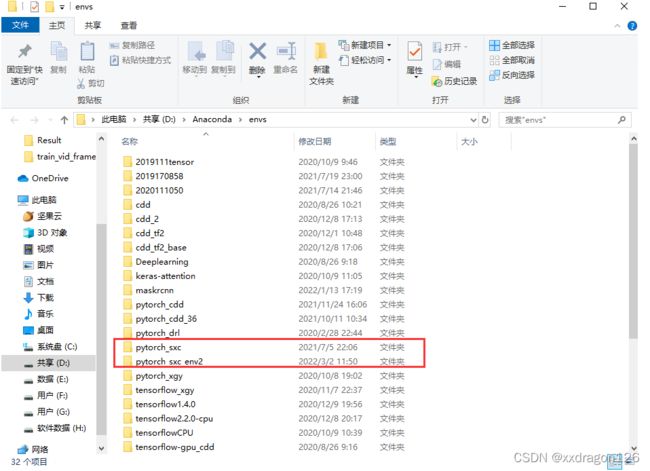
PS:在命令行窗口中跳转到自己的环境中:conda activate pytorch_sxc_env2
PS:利用命令行跳转文件目录,包括G:、cd LRF、cd./Exa_20220302、等
0.1 查看该环境中pip list,是否包含了requirements.txt所需的包;如果不包含,则使用pip install *包名 进行安装
PS: pip list查看已安装的包
0.2 配置一些镜像文件的地址
1.1 网址资料:https://github.com/ZhengPeng7/motion_magnification_learning-based
(参考上述资料中的说明文件,进行调试)
1.2 由于打算直接使用作者已经训练好的网络进行视频测试,因此跳过了网页中“Data preparation”中的前两步,而直接调试第3部。
(注意:代码中的main.py是训练模型用的代码,即常见的train.py的文件;
此外,test_video.py是测试文件;
使用“bash run.sh”命令可同时执行上述两个文件;不过在我的此次调试过程中,不考虑对网络进行训练,因此后期只考虑执行test_video.py是测试文件。)
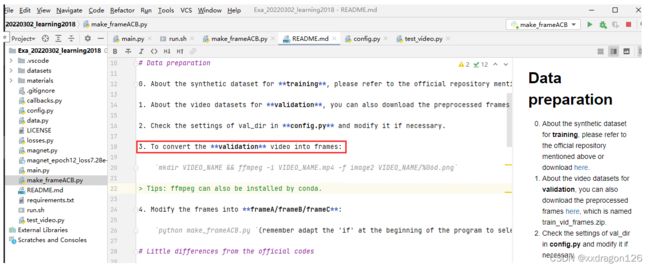
2 关于“
To convert the validation video into frames:
mkdir VIDEO_NAME && ffmpeg -i VIDEO_NAME.mp4 -f image2 VIDEO_NAME/%06d.png”的调试过程记录:
2.1 首先,按照以下两个文件中关于视频数据存放目录的指示,创建目录,以便于存放视频:
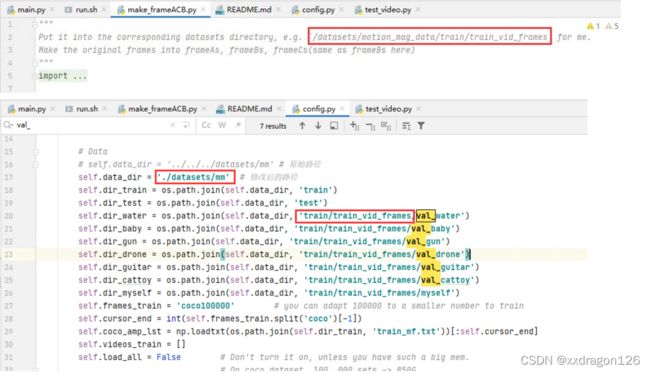
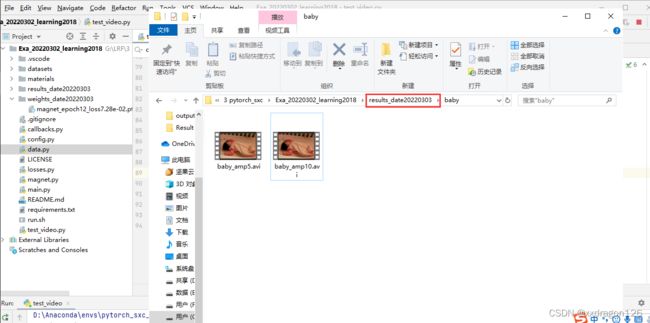
因此,目前创建的存放视频数据的目录为:
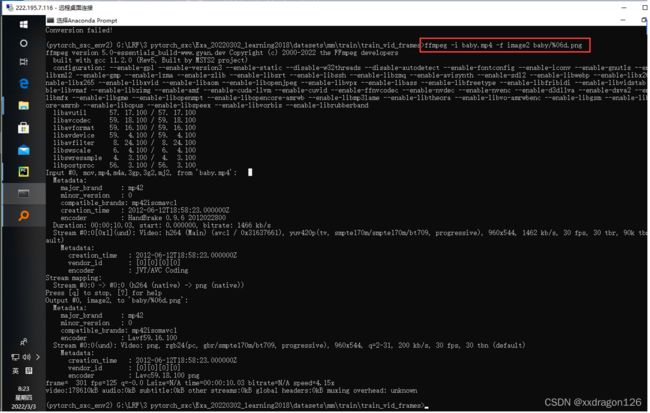
2.2 在命令行窗口中,执行 mkdir VIDEO_NAME && ffmpeg -i VIDEO_NAME.mp4 -f image2 VIDEO_NAME/%06d.png”
(&&连接了两条命令:前者为创建名为VIDEO_NAME的文件夹,后者为使用FFmpeg可执行文件(不是pip安装的包)将视频文件VIDEO_NAME.mp4的各帧图像提取出来,命名为%06d.png)
2.2.1 首先安装ffmpeg可执行文件
在网上下载该文件,并解压放置在某文件目录下,并ffmpeg.exe的路径添加到环境变量中即可。
2.2.2 使用anaconda的命令行窗口,将当前目录跳转到视频所在的目录下,执行上述命令,即可:
(PS:我已经自行创建了名为baby的文件夹,因此没有再次使用mkdir命令创建该文件夹。)
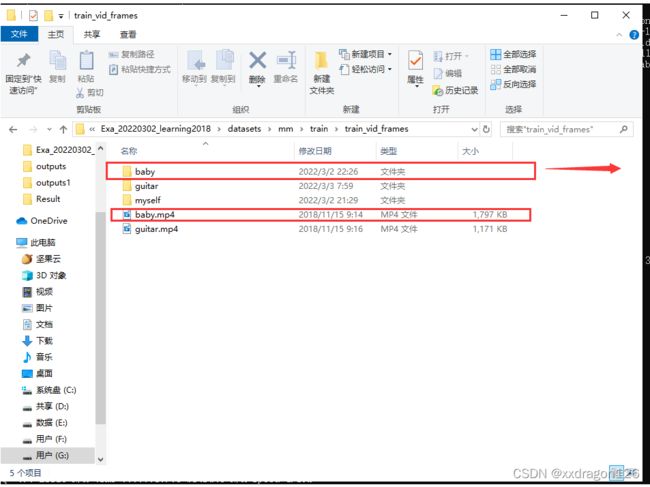
执行结果:

3. 继续调试:
3.0 执行make_frameACB.py,其功能在于:
3.0.1 首先获得待处理的视频图像序列的文件夹
3.0.2 依次对每个文件夹进行处理(类似于对每个视频文件进行处理):
1. 将原始视频图像序列复制到新文件夹fameA中,并删除最后一张图片(序号从1开始)
2. 将原始视频图像序列复制到新文件夹fameC中,并删除第一张图片(序号从2开始),再通过图像重命名,将文件名的序号更新为从1开始
3. 将fameC中的文件复制给frameB,从而得到了frameA、frameC和frameB,并发现后两者是一样的。
3.0.3 删除原始视频图像序列
3.0.4 for循环处理下一个文件夹中的视频
3.1 将文件“make_frameACB.py“存放在与视频文件相同的文件夹下
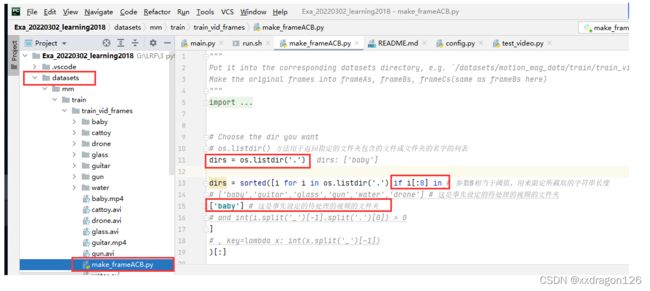
3.2 在pycharm中调试make_frameACB.py程序,查看程序的执行结果:
本段语句用来选取当前文件下的待处理的视频文件的文件夹,例如:本程序的执行结果是选取当前目录下的名为“baby”的文件夹。
即:
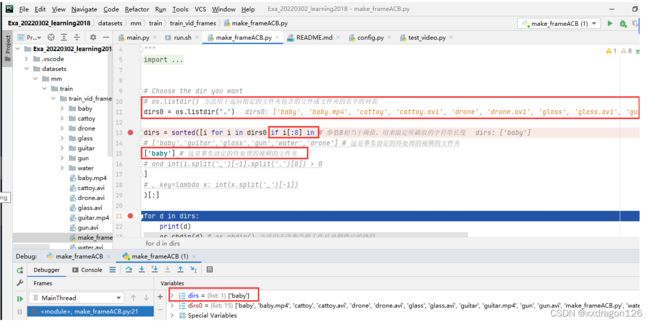
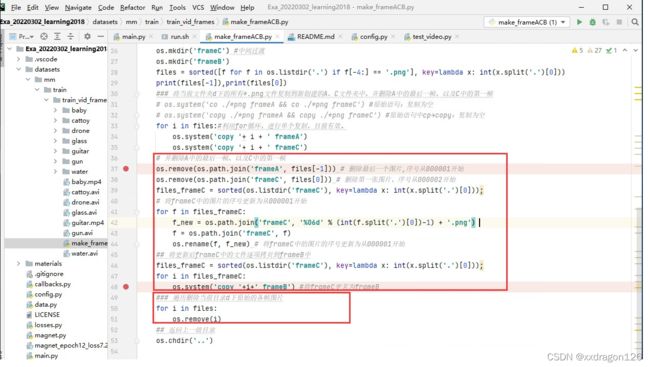
3.3 生成frameA、frameC时,对“用于实现图片复制功能”的代码,进行了调整:

PS:查阅当前路径的命令 os.getcwd()
3.4 此外,对文件复制、文件删除的语句做了更新
4 接下来调试test_video.py
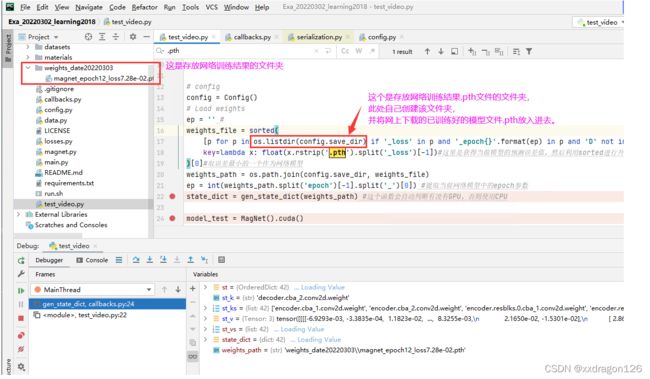
4.1 设置config文件中的参数
PS:设置存放网络训练模型的文件夹,并将已训练好的模型.pth文件存放进去。
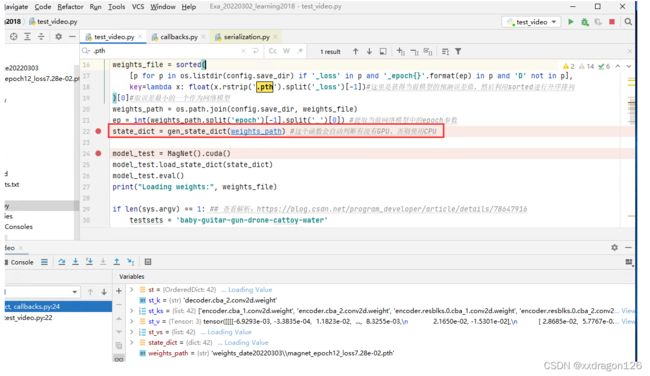
 4.2 调用gen_state_dict函数,将网络参数模型加载到GPU或者CPU
4.2 调用gen_state_dict函数,将网络参数模型加载到GPU或者CPU
PS:这里对该函数gen_state_dict()进行了修改,用来判断“
torch.cuda.is_available()
”是否为True,否则使用CPU:
def gen_state_dict(weights_path): if torch.cuda.is_available():#来判断“torch.cuda.is_available()”是否为True,否则使用CPU: st = torch.load(weights_path) else: st = torch.load(weights_path,map_location=torch.device('cpu')) st_ks = list(st.keys()) st_vs = list(st.values()) state_dict = {} for st_k, st_v in zip(st_ks, st_vs): state_dict[st_k.replace('module.', '')] = st_v return state_dict
4.4 对存在cuda()的函数,都加入了判断:,如果GPU不可用,则使用CPU。
4.5 程序跑通了,结果存储在result文件夹中。(PS:速度有点慢。)