Bagging算法和决策树算法之间的区别对比以及决策树中OBB策略
决策树中的算法
集成算法中
Bagging算法和决策树算法
"""
Bagging模型算法特点==>相较于树模型来说增加大量的树
1. =首先对训练数据进行多次采样,保证每次得到的采样数据都是不同的
2. =分别训练多个模型,例如树模型,在实例化的api里指定算法,一般都直接选择树模型就可以了
3. =预测时需得到所有模型结果在进行集成
"""
##Bagging模型算法和树模型之间的对比
##引入bagging分类器
from sklearn.ensemble import BaggingClassifier
##引入决策树分类器
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
##实例化
baggingcls = BaggingClassifier(
##基本算法通常选择树模型
DecisionTreeClassifier(),
##当前建立的树的数量
n_estimators=500,
##最多传进来多少个样本
max_samples=100,
##默认为1 即为全部特征
max_features=1.0,
##是否用替换法抽取样本就是有放回的随机采样
bootstrap=True,
##多线程使用全部的CPU
n_jobs=-1,
##随机策略
random_state=42,)
baggingcls.fit(x_train,y_train)
y_pred=baggingcls.predict(x_test)
print('Bagging模型算法准确率为{accuracy_scores}'.format(accuracy_scores=accuracy_score(y_test,y_pred)))
#####树模型
tree_clf = DecisionTreeClassifier(random_state=42)
tree_clf.fit(x_train,y_train)
tree_y_pred=tree_clf.predict(x_test)
print('树模型准确率为{accuracy_scores}'.format(accuracy_scores=accuracy_score(y_test,tree_y_pred)))

树模型tree经过Bagging算法素质再教育后精度得到了明显的提升。
绘制决策边界
可视化效果展示,直接绘制出过程
def plot_decison(clf,x,y,axes=[-1.5,2.5,-1,1.5],alpha=0.5,contour=True):
##绘制棋盘
x1s = np.linspace(axes[0],axes[1],100)
x2s = np.linspace(axes[2],axes[3],100)
##合并棋盘
x1 , x2 = np.meshgrid(x1s,x2s)
##整合 拉长
x_new=np.c_[x1.ravel(),x2.ravel()]
y_pred =clf.predict(x_new).reshape(x1.shape)
##指定颜色
custom_camp1 = ListedColormap(['#7d7d58', '#4c4c7f', '#507d50'])
plt.contourf(x1,x2,y_pred,cmap=custom_camp1,alpha=0.3)
if contour:
custom_camp2=ListedColormap(['#7d7d58','#4c4c7f','#507d50'])
plt.contour(x1,x2,y_pred,cmap=custom_camp2,alpha=0.8)
plt.plot(x[:,0][y==0], x[:,1][y==0],'yo',alpha=0.6)
plt.plot(x[:,0][y==1], x[:,1][y==1],'bs',alpha=0.6)
plt.axis(axes)
plt.xlabel('x1')
plt.xlabel('x2')
完整代码
"""
Bagging模型算法特点==>相较于树模型来说增加大量的树
1. =首先对训练数据进行多次采样,保证每次得到的采样数据都是不同的
2. =分别训练多个模型,例如树模型,在实例化的api里指定算法,一般都直接选择树模型就可以了
3. =预测时需得到所有模型结果在进行集成
"""
##Bagging模型算法和树模型之间的对比
##引入bagging分类器
from sklearn.ensemble import BaggingClassifier
##引入决策树分类器
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
##实例化
baggingcls = BaggingClassifier(
##基本算法通常选择树模型
DecisionTreeClassifier(),
##当前建立的树的数量
n_estimators=500,
##最多传进来多少个样本
max_samples=100,
##默认为1 即为全部特征
max_features=1.0,
##是否用替换法抽取样本就是有放回的随机采样
bootstrap=True,
##多线程使用全部的CPU
n_jobs=-1,
##随机策略
random_state=42,)
baggingcls.fit(x_train,y_train)
y_pred=baggingcls.predict(x_test)
print('Bagging模型算法准确率为{accuracy_scores}'.format(accuracy_scores=accuracy_score(y_test,y_pred)))
#####树模型
tree_clf = DecisionTreeClassifier(random_state=42)
tree_clf.fit(x_train,y_train)
tree_y_pred=tree_clf.predict(x_test)
print('树模型准确率为{accuracy_scores}'.format(accuracy_scores=accuracy_score(y_test,tree_y_pred)))
import numpy as np
from matplotlib.colors import ListedColormap
##clf(分类器)(x)(y)数值axes=[](取值范围)alpha=0.5(透明度)contour(轮廓)
def plot_decison(clf,x,y,axes=[-1.5,2.5,-1,1.5],alpha=0.5,contour=True):
##绘制棋盘
x1s = np.linspace(axes[0],axes[1],100)
x2s = np.linspace(axes[2],axes[3],100)
##合并棋盘
x1 , x2 = np.meshgrid(x1s,x2s)
##整合 拉长
x_new=np.c_[x1.ravel(),x2.ravel()]
y_pred =clf.predict(x_new).reshape(x1.shape)
##指定颜色
custom_camp1 = ListedColormap(['#7d7d58', '#4c4c7f', '#507d50'])
plt.contourf(x1,x2,y_pred,cmap=custom_camp1,alpha=0.3)
if contour:
custom_camp2=ListedColormap(['#7d7d58','#4c4c7f','#507d50'])
plt.contour(x1,x2,y_pred,cmap=custom_camp2,alpha=0.8)
plt.plot(x[:,0][y==0], x[:,1][y==0],'yo',alpha=0.6)
plt.plot(x[:,0][y==1], x[:,1][y==1],'bs',alpha=0.6)
plt.axis(axes)
plt.xlabel('x1')
plt.xlabel('x2')
plt.figure(figsize=(12,5))
plt.subplot(1,2,1)
plot_decison(tree_clf,x,y)
plt.title("tree")
plt.subplot(1,2,2)
plot_decison(baggingcls,x,y)
plt.title("tree with bagging")

很明显的可以看出经过bagging算法生长出多个树素质再教育后,效果提升的很大,明显决策树模型过拟合了。
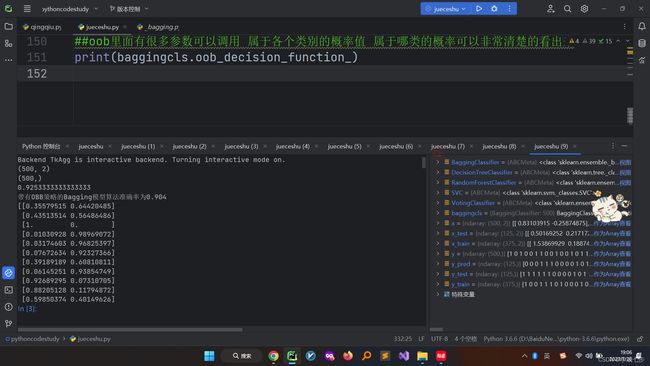
OOB策略
OBB策略就是验证集得分,里面参数调用比较方便,可以非常清楚的看出某个数值各个类别的概率值。
from sklearn.ensemble import BaggingClassifier
##引入决策树分类器
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
##实例化
baggingcls = BaggingClassifier(
##基本算法通常选择树模型
DecisionTreeClassifier(),
##当前建立的树的数量
n_estimators=500,
##最多传进来多少个样本
max_samples=100,
##默认为1 即为全部特征
max_features=1.0,
##是否用替换法抽取样本就是有放回的随机采样
bootstrap=True,
##OBB策略==>划分数据集时拿那个原始的数据集拿进去验证 直接制定一个参数即可 一般中验证集通常比测试集得分要高
oob_score=True,
##多线程使用全部的CPU
n_jobs=-1,
##随机策略
random_state=42,)
baggingcls.fit(x_train,y_train)
print(baggingcls.oob_score_)
y_pred=baggingcls.predict(x_test)
print('带有OBB策略的Bagging模型算法准确率为{accuracy_scores}'.format(accuracy_scores=accuracy_score(y_test,y_pred)))
##oob里面有很多参数可以调用 属于各个类别的概率值 属于哪类的概率可以非常清楚的看出来
print(baggingcls.oob_decision_function_)