【随机森林】深入浅出讲解随机森林算法
 本文收录于《深入浅出讲解自然语言处理》专栏,此专栏聚焦于自然语言处理领域的各大经典算法,将持续更新,欢迎大家订阅!
本文收录于《深入浅出讲解自然语言处理》专栏,此专栏聚焦于自然语言处理领域的各大经典算法,将持续更新,欢迎大家订阅! 个人主页:有梦想的程序星空
个人主页:有梦想的程序星空 个人介绍:小编是人工智能领域硕士,全栈工程师,深耕Flask后端开发、数据挖掘、NLP、Android开发、自动化等领域,有较丰富的软件系统、人工智能算法服务的研究和开发经验。
个人介绍:小编是人工智能领域硕士,全栈工程师,深耕Flask后端开发、数据挖掘、NLP、Android开发、自动化等领域,有较丰富的软件系统、人工智能算法服务的研究和开发经验。 如果文章对你有帮助,欢迎
如果文章对你有帮助,欢迎
关注、
点赞、收藏、订阅。
1、集成学习介绍
常言道:“一个篱笆三个桩,一个好汉三个帮”。集成学习模型便是综合考量多个学习器的预测结果,从而做出决策。集成学习通过训练学习出多个估计器,当需要预测时通过结合器将多个估计器的结果整合起来当作最后的结果输出。
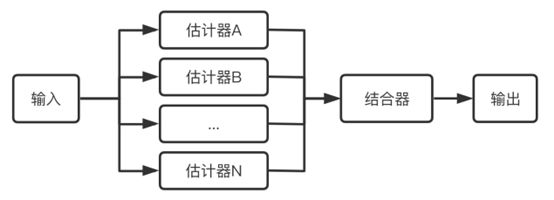
集成学习分两种:
(1)模型之间彼此存在依赖关系,按一定的次序搭建多个分类模型,一般后一个模型的加入都需要对现有的集成模型有一定贡献,进而不断提高更新过后的集成模型性能,并借助多个弱分类器搭建出强分类器。代表有Boosting(AdaBoost)算法。
(2)模型之间彼此不存在依赖关系,彼此独立。利用相同的训练数据同时搭建多个独立的分类模型,然后通过投票的方式,以少数服从多数的原则做出最终的分类决策。例如:Bagging(随机森林)。
集成学习的优势是提升了单个估计器的通用性与鲁棒性,比单个估计器拥有更好的预测性能。集成学习的另一个特点是能方便的进行并行化操作。
2、Bagging算法
Bagging 算法是一种集成学习算法,其全称为自助聚集算法(Bootstrap aggregating),顾名思义算法由 Bootstrap 与 Aggregating 两部分组成。
算法的具体步骤为:
假设有一个大小为 N 的训练数据集,每次从该数据集中有放回的取选出大小为 M 的子数据集,一共选 K 次,根据这 K 个子数据集,训练学习出 K 个模型。
当要预测的时候,使用这 K 个模型进行预测,再通过取平均值或者多数分类的方式,得到最后的预测结果。
3、决策树与随机森林
决策树算法有这几种:ID3、C4.5、CART,基于决策树的算法有:随机森林、GBDT等。
决策树是一种利用树形结构进行决策的算法,对于样本数据根据已知条件或叫特征进行分叉,最终建立一棵树,树的叶子结节标识最终决策。新来的数据便可以根据这棵树进行判断。
随机森林是在决策树的基础上衍生出来的。随机森林是一种通过多棵决策树进行优化决策的算法。决策树和随机森林的关系就是树和森林的关系。通过对原始训练样本的抽样,以及对特征节点的选择,我们可以得到许多棵不同的树。
4、随机森林的原理

随机森林由Leo Breiman(2001)提出的一种分类算法,它通过自助法(bootstrap)重采样技术,从原始训练样本集N中有放回地重复随机抽取n个样本生成新的训练样本集合训练决策树,然后按以上步骤生成m棵决策树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。其实质是对决策树算法的一种改进,将多个决策树合并在一起,每棵树的建立依赖于独立抽取的样本。
单棵树的分类能力可能很小,但在随机产生大量的决策树后,一个测试样本可以通过每一棵树的分类结果经统计后选择最可能的分类。
假设训练集 T 的大小为 N ,特征数目为 M ,随机森林的树的数量为 K ,随机森林算法的具体步骤如下:
重复下面步骤 K 次,即生成K棵决策树,形成随机森林:
第一步:从训练集 T 中有放回抽样的方式,取样N 次形成一个新子训练集 D;
第二步:随机选择 m 个特征,其中 m < M;
第三步:使用新的训练集 D 和 m 个特征,学习出一个完整的决策树(一般是CART);随机森林的随机性主要体现在两个方面:
数据集的随机选取。
每棵树所使用特征的随机选取。以上两个随机性使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
5、随机森林的优缺点
-
优点
1)实现简单,泛化能力强,可以并行实现,因为训练时树与树之间是相互独立的;
2)相比单一决策树,能学习到特征之间的相互影响,且不容易过拟合;
3)能直接特征很多的高维数据,因为在训练过程中依旧会从这些特征中随机选取部分特征用来训练;
4)相比SVM,不是很怕特征缺失,因为待选特征也是随机选取;
5)训练完成后可以给出特征重要性。当然,这个优点主要来源于决策树。因为决策树在训练过程中会计算熵或者是基尼系数,越往树的根部,特征越重要。
-
缺点
1)在噪声过大的分类和处理回归问题时还是容易过拟合;
2)相比于单一决策树,它的随机性让我们难以对模型进行解释。6、Python代码实现
scikit-learn实现随机森林分类:
from sklearn.ensemble import RandomForestClassifier
# 随机森林分类器
clf = RandomForestClassifier(n_estimators = 100, random_state = 0)
# 拟合数据集
clf = clf.fit(X, y)
关注微信公众号【有梦想的程序星空】,了解软件系统和人工智能算法领域的前沿知识,让我们一起学习、一起进步吧!