Huggingface-transformers项目源码剖析及Bert命名实体识别实战
文章目录
- 一、Huggingface-transformers介绍
- 二、文件组成
- 三、config
- 四、Tokenizer
- 五、基本模型BertModel
- 六、序列标注任务实战(命名实体识别)
-
- 1.加载各类包(略)
- 2.载入训练参数
- 3.模型初始化
- 4.BertForTokenClassification
- 5.处理数据
- 6.开始训练
-
- 1)将训练、验证、测试数据集传入DataLoader
- 2)设置优化函数
- 3) 设置fp16精度、多gpu并行、分布式训练
- 4)是否冻结训练参数
- 5)学习率退火
- 6)训练参数可视化
- 7)轮次训练迭代
- 7.测试评估和预测
- 参考文献
一、Huggingface-transformers介绍
transformers(以前称为pytorch-transformers和pytorch-pretrained-bert)提供用于自然语言理解(NLU)和自然语言生成(NLG)的BERT家族通用结构(BERT,GPT-2,RoBERTa,XLM,DistilBert,XLNet等),包含超过32种、涵盖100多种语言的预训练模型。同时提供TensorFlow 2.0和PyTorch之间的高互通性。项目安装非常便捷,使用pip命令即可。使用transformers前需要下载好pytorch(版本>=1.0)或者tensorflow2.0。下面以pytorch为例,来演示使用方法
pip install transformers
github:https://github.com/huggingface/transformers
通过此次源码分享,你将了解:
- transformers加载bert的方法,及相关类的源码
- 以命名实体识别和阅读理解为例,展示如何使用transformers实现下游任务
transformer项目组成介绍
examples中是项目提供的各种任务的例子。src/transformers/文件夹是项目涉及各类函数的地址。

token-classification是序列标注例子所在的文件夹,其中run_ner.py是此次分享的命名实体识别程序文件。

二、文件组成
pytroch 版本的bert主要有三个文件组成:
- 词表文件(Tokenizer) —— vocab.txt
- 配置文件 —— bert_config.json
- 模型文件 —— *.bin

三、config
bert_config.json为Bert配置文件,存放了BertModel的配置,控制模型的名称、最终输出的样式、隐藏层宽度和深度、激活函数的类别等。将Config类导出时文件格式为 json格式,就像下面这样:
{
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"type_vocab_size": 2,
"vocab_size": 21128
}
具体含义可以参考:https://huggingface.co/transformers/v2.1.1/model_doc/bert.html#bertconfig
具体加载config的代码如下所示:
from transformers import BertConfig
#在v2.10.0中使用的自动识别的类,但在此次源码分享中仅以Bert模型为例
#from transformers import AutoConfig,
config = BertConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
num_labels=num_labels,
id2label=label_map,
label2id={label: i for i, label in enumerate(labels)},
cache_dir=model_args.cache_dir,
)
BertConfig 父类 PretrainedConfig 中的from_pretrained函数如下:
def from_pretrained(cls, pretrained_model_name_or_path, **kwargs) ->
r"""
Args:
pretrained_model_name_or_path (:obj:`string`) 名称
cache_dir (:obj:`string`, `optional`) 缓存文件夹
kwargs (:obj:`Dict[str, any]`, `optional`) 其他参数用 `Dict[str, any]`的形式
force_download (:obj:`bool`, `optional`, defaults to :obj:`False`) 覆盖文件夹中之前下载文件
resume_download (:obj:`bool`, `optional`, defaults to :obj:`False`) 是否继续下载
proxies (:obj:`Dict`, `optional`) 代理服务器地址
Returns:
:class:`PretrainedConfig`: An instance of a configuration object
Examples::
config 文件可以采取三种方式,bert名称、bert文件夹地址、config文件地址
config = BertConfig.from_pretrained('bert-base-uncased') # Download configuration from S3 and cache.
config = BertConfig.from_pretrained('./test/saved_model/') # E.g. config (or model) was saved using `save_pretrained('./test/saved_model/')`
config = BertConfig.from_pretrained('./test/saved_model/my_configuration.json')
config = BertConfig.from_pretrained('bert-base-uncased', output_attention=True, foo=False)
assert config.output_attention == True
config, unused_kwargs = BertConfig.from_pretrained('bert-base-uncased', output_attention=True,
foo=False, return_unused_kwargs=True)
assert config.output_attention == True
assert unused_kwargs == {'foo': False}
"""
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
return cls.from_dict(config_dict, **kwargs)
BertConfig源码如下所示,就是一个包含各种参数的类。虽然模型显示可以自加参数(**kwargs),但我的模型加载参数总出错,所以我的代码采用笨方法加载自己参数,效果是一样的。
class BertConfig(PretrainedConfig):
pretrained_config_archive_map = BERT_PRETRAINED_CONFIG_ARCHIVE_MAP
model_type = "bert"
def __init__(
self,
vocab_size=30522,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=2,
initializer_range=0.02,
layer_norm_eps=1e-12,
pad_token_id=0,
**kwargs
):
super().__init__(pad_token_id=pad_token_id, **kwargs)
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.hidden_act = hidden_act
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.initializer_range = initializer_range
self.layer_norm_eps = layer_norm_eps
#此处可以添加自己模型需要的额外参数
self.trigger_label = None
self.device = None
config.device = device
四、Tokenizer
这是一个将纯文本转换为编码的过程。注意,Tokenizer并不涉及将词转化为词向量的过程,仅仅是将纯文本分词,添加[MASK]标记、[SEP]、[CLS]标记,并转换为字典索引。Tokenizer类导出时将分为三个文件,也就是:
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=model_args.use_fast,
do_lower_case=args.do_lower_case
)
其父类PreTrainedTokenizer的from_pretrained方法与config类似。使用时,先利用tokenize将文本进行标准化转化,再利用convert_tokens_to_ids进行lookup操作转化为input_ids
利用Tokenizer处理文本
- 利用Tokenizer对单句进行分词和(标准化)编码
In[1]:text = '我爱北京天安门,吢吣吤吥吧吩'
In[2]:tokens = tokenizer.tokenize(text)
In[3]:input_ids = tokenizer.convert_tokens_to_ids(tokens)#使用tokenizer.encode也可以达成同样效果,encode是其父类定义的方法,分别调用以上两步。利用convert_ids_to_tokens函数即可达成ids转换成token。
In[4]:print(tokens,'\n',input_ids)
Out:['我', '爱', '北', '京', '天', '安', '门', ',', '[UNK]', '[UNK]', '[UNK]', '[UNK]', '吧', '吩']
[2769, 4263, 1266, 776, 1921, 2128, 7305, 8024, 100, 100, 100, 100, 1416, 1418]
- 利用Tokenizer对多句进行分词和(标准化)编码
# encode_plus返回所有编码信息
In:sen_code = tokenizer.encode_plus("i like you", "but not him")
Out :
{'input_ids': [101, 1045, 2066, 2017, 102, 2021, 2025, 2032, 102],
'token_type_ids': [0, 0, 0, 0, 0, 1, 1, 1, 1],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
- 模型的所有分词器都是在PreTrainedTokenizer中实现的,分词的结果主要有以下内容:
{
input_ids: list[int],
token_type_ids: list[int] if return_token_type_ids is True (default)
attention_mask: list[int] if return_attention_mask is True (default)
overflowing_tokens: list[int] if a max_length is specified and return_overflowing_tokens is True
num_truncated_tokens: int if a max_length is specified and return_overflowing_tokens is True
special_tokens_mask: list[int] if add_special_tokens if set to True and return_special_tokens_mask is True
}
-
编码解释:
- ‘input_ids’:顾名思义,是单词在词典中的编码
- ‘token_type_ids’, 区分两个句子的编码
- ‘attention_mask’, 指定对哪些词进行self-Attention操作,意味pad部分为0
- ‘overflowing_tokens’, 当指定最大长度时,溢出的单词
- ‘num_truncated_tokens’, 溢出的token数量
- ‘return_special_tokens_mask’,如果添加特殊标记,则这是[0,1]的列表,其中0指定特殊添加的标记,而1指定序列标记
-
special_tokens_map.json 特殊标记的定义方式:
{"unk_token": "[UNK]", "sep_token": "[SEP]", "pad_token": "[PAD]",
"cls_token": "[CLS]", "mask_token": "[MASK]"}
五、基本模型BertModel
基本模型,可以将其理解为将输入转化为bert向量的模型。项目在基本模型(如Berrt、GPT等)基础上,针对下游任务,还定义了诸如BertForQuestionAnswering、BertForTokenClassification等下游任务模型。从构造函数可以看到用到了embeddings,encoder和pooler。
模型导出时将生成config.json和pytorch_model.bin参数文件。前者就是1中的配置文件,这和我们的直觉相同,即config和model应该是紧密联系在一起的两个类。后者其实和torch.save()存储得到的文件是相同的,这是因为Model都直接或者间接继承了Pytorch的Module类。从这里可以看出,HuggingFace在实现时很好地尊重了Pytorch的原生API。
- 模型输入
下面是允许输入到模型中的参数,模型至少需要有1个输入: input_ids 或 input_embeds。
input_ids 就是一连串 token 在字典中的对应id。形状为 (batch_size, sequence_length)。
token_type_ids 可选。就是 token 对应的句子id,值为0或1(0表示对应的token属于第一句,1表示属于第二句)。形状为(batch_size, sequence_length)。
input_ids 就是一连串 token 在字典中的对应id。形状为 (batch_size, sequence_length)。Bert 的输入需要用 [CLS] 和 [SEP] 进行标记,开头用 [CLS],句子结尾用 [SEP],各类bert模型对应的输入格式如下所示:
bert: [CLS] + tokens + [SEP] + padding
roberta: [CLS] + prefix_space + tokens + [SEP] + padding
distilbert: [CLS] + tokens + [SEP] + padding
xlm: [CLS] + tokens + [SEP] + padding
xlnet: padding + tokens + [SEP] + [CLS]
token_type_ids 可选。就是 token 对应的句子id,值为0或1(0表示对应的token属于第一句,1表示属于第二句)。形状为(batch_size, sequence_length)。如为None则BertModel会默认全为0(即a句)。
两个句子:
tokens:[CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]
token_type_ids:0 0 0 0 0 0 0 0 1 1 1 1 1 1
一个句子:
tokens:[CLS] the dog is hairy . [SEP]
token_type_ids:0 0 0 0 0 0 0
attention_mask 可选。各元素的值为 0 或 1 ,避免在 padding 的 token 上计算 attention(1不进行masked,0则masked)。形状为(batch_size, sequence_length)。如为None则BertModel默认全为1。
position_ids 可选。表示 token 在句子中的位置id。形状为(batch_size, sequence_length)。形状为(batch_size, sequence_length)。如为None则BertModel会自动生成。
形如[0,1,2,......,seq_length - 1],
head_mask 可选。各元素的值为 0 或 1 ,1 表示 head 有效,0无效。形状为(num_heads,)或(num_layers, num_heads)。
input_embeds 可选。替代 input_ids,我们可以直接输入 Embedding 后的 Tensor。形状为(batch_size, sequence_length, embedding_dim)。
encoder_hidden_states 可选。encoder 最后一层输出的隐藏状态序列,模型配置为 decoder 时使用。形状为(batch_size, sequence_length, hidden_size)。
encoder_attention_mask 可选。避免在 padding 的 token 上计算 attention,模型配置为 decoder 时使用。形状为(batch_size, sequence_length)。
以下部分参考Bert代码详解(一)
- 构造函数__init__
def __init__(self, config):
super().__init__(config)
self.config = config
self.embeddings = BertEmbeddings(config)
self.encoder = BertEncoder(config)
self.pooler = BertPooler(config)
self.init_weights()
- BertEmbeddings(config)
只看最后它的输出,返回拼接inputs_embeds、position_embeddings、token_type_embeddings
embeddings = inputs_embeds + position_embeddings + token_type_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
- BertEncoder(config)
BertEncoder层建立了12个BertLayer层(large为24),然后将这12个层的输出以list形式进行输出。BertLayer层架构请见Bert代码详解(一)
#BertEncoder层建立了整个transformer构架
#Transformer构架参考:https://zhuanlan.zhihu.com/p/39034683 (BE CAUTIOUS!)
#现在我假设大家都知道了这个架构,我这里沿袭了上面知乎中某些专有名词的称呼
#........................................................................
#Transformer中包含若干层(论文中base为12层,large为24层)encoder,每层encoder在代码中就是一个BertLayer。
#所以下面的代码首先声明了一层layer,然后构造了num_hidden_layers(12 or 24)层相同的layer放在一个列表中,既是self.layer
layer = BertLayer(config)
self.layer = nn.ModuleList([copy.deepcopy(layer) for _ in range(config.num_hidden_layers)])
#........................................................................
#........................................................................
#下面看其forward函数
def forward(self, hidden_states, attention_mask, output_all_encoded_layers=True):
#看其输入:
#hidden_states:根据上面所讲,hidden_states就是embedding_output,其维度为[batch_size, seq_lenght, word_dimension],embedding出来后,多了一个dimension
#attention_mask:维度[batch_size, 1, 1, seq_length]
#(to be completed)
#output_all_encoder_layers:此函数的输出模式,下面会详细讲解
#这个函数到底做了什么了?其实很简单,就是做了一个循环,将每一个encoder的输出作为输入输给下一层的encoder,直到12(or24)层循环完毕
all_encoder_layers = []
#遍历所有的encoder,总共有12层或者24层
for layer_module in self.layer:
#每一层的输出hidden_states也是下一层layer_moudle(BertLayer)的输入,这样就连接起来了各层encoder。第一层的输入是embedding_output
hidden_states = layer_module(hidden_states, attention_mask)
#如果output_all_encoded_layers == True:则将每一层的结果添加到all_encoder_layers中
if output_all_encoded_layers:
all_encoder_layers.append(hidden_states)
#如果output_all_encoded_layers == False, 则只将最后一层的输出加到all_encoded_layers中
if not output_all_encoded_layers:
all_encoder_layers.append(hidden_states)
return all_encoder_layers
#所以output_all_encoded_layers是用来控制输出模式的。
#这样整个transformer的框架就出来了,下面将讲述框架中的每一层encoder(即BertLayer)是怎么构造的
#........................................................................
- BertPooler层
取出每一句的第一个单词,做全连接和激活。得到的输出可以用来分类等下游任务(即将每个句子的第一个单词的表示作为整个句子的表示)
#pooler层的输入是transformer最后一层的输出,[batch_size, seq_length, hidden_size]
def forward(self, hidden_states):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
#取出每一句的第一个单词,做全连接和激活。得到的输出可以用来分类等下游任务(即将每个句子的第一个单词的表示作为整个句子的表示)
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
- BertModel中forward函数
依次调用BertEmbeddings、BertEncoder、BertPooler,最后返回的是encoder_outputs第1层(?不太确定,但从代码看是如此)+ pooled_output(即用一个词[cls]代表整句话)+ encoder_outputs其他层的输出 + attentions
embedding_output = self.embeddings(
input_ids=input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds
)
encoder_outputs = self.encoder(
embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
)
sequence_output = encoder_outputs[0]
pooled_output = self.pooler(sequence_output)
outputs = (sequence_output, pooled_output,) + encoder_outputs[
1:
] # add hidden_states and attentions if they are here
return outputs # sequence_output, pooled_output, (hidden_states), (attentions)
六、序列标注任务实战(命名实体识别)
以序列标注模型为例,各级bert模型继承关系
1.加载各类包(略)
2.载入训练参数
新版本的transformers中的ner没有采用传统的parser模块,利用HfArgumentParser方法,将参数类转化为argparse参数,以便于在命令行中指定他们。这样按用途划分可以更好查找关注,或设置相关参数。
#run_ner.py中97行
#ModelArguments类为model/config/tokenizer涉及的参数
#DataTrainingArguments类为数据涉及到的参数
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# 训练时输入python run_ner.py *******.json,即从.json中读取参数。
# 当sys.argv参数为2时,此时sys.argv[0]为自己本身,即"run_ner.py",sys.argv[1]为json文件
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
3.模型初始化
参照三、四、五节内容。
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
num_labels=num_labels,
id2label=label_map,
label2id={label: i for i, label in enumerate(labels)},
cache_dir=model_args.cache_dir,
)
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=model_args.use_fast,
)
model = AutoModelForTokenClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
)
- 导入模型的方法
主要如下图所示三种导入方法,具体可参照博客HuggingFace-Transformers系列的介绍以及在下游任务中的使用,这里只展示下载到本地后加载bert模型
当前transformers使用 AutoModelForTokenClassification(以序列标注任务为例)实现模型的自动加载(可以使自己程序显得高端、大气、上档次)。实现原理:利用该函数的’ from_pretrained() ‘方法负责返回正确的模型类实例,基于config对象的’ model_type ‘属性,当前输入并无此属性时,返回到在’ pretrained_model_name_or_path '字符串上使用模式匹配。在实现了自己的序列标注模型后,可以通过修改modeling_auto.py中MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING关键字段来匹配自己的模型。
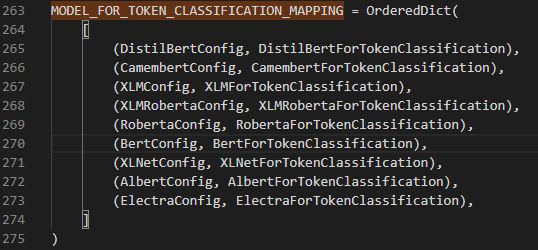
不过自动加载的方法在调试模型时并不适用,所以还是直接加载来的划算:
from transformers import BertForTokenClassification #可以修改成自己的模型
#from transformers.modeling_bert import BertForTokenClassification 序列标注bert模型原始位置
model = BertForTokenClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
)
4.BertForTokenClassification
BertForSequenceClassification(modeling_bert.py)是一个已经实现好的在 token 级别上进行文本分类的类,一般用来进行序列标注任务(在进行自己的命名实体识别任务时,可以新建子类继承该方法,进行其他任务也类似),相关类继承关系如下:
BertForTokenClassification构造函数如下所示:
def __init__(self, config):
super(BertForTokenClassification, self).__init__(config)
self.num_labels = config.num_labels #假设有10个标签
self.bert = BertModel(config) #hidden_size维度为768
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)#该线性层为768*10
self.init_weights()
下面是 BertForTokenClassification 的中 forward() 函数的部分代码,它用到的是全部 token 上的输出。返回 loss + scores(即logits) + hidden_states + attentions
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
):
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
)#原则上用到前四个参数即可,也可直接取第几层输入,有论文表示第3层输出用于命名实体识别效果最好
sequence_output = outputs[0] #假设输入为64*128*768
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output) # (64*128*768) * (768*10) = 64*128*10
outputs = (logits,) + outputs[2:] # add hidden states and attention if they are here
if labels is not None: #给labels是训练
loss_fct = CrossEntropyLoss() #交叉熵损失函数
# Only keep active parts of the loss
if attention_mask is not None:
active_loss = attention_mask.view(-1) == 1 #先把attention_mask展开,其中等于1为True,等于0为False,维度 64*128 = 8192
active_logits = logits.view(-1, self.num_labels) #把logits展开,维度为8192*10
active_labels = torch.where(
active_loss, labels.view(-1), torch.tensor(loss_fct.ignore_index).type_as(labels)
)#where三个参数,第一个为判断条件,第二个是复合条件设置值,第三个不符合条件设置值。loss_fct.ignore_index默认为-100,可以在初始化CrossEntropyLoss(ignore_index=-1)修改
loss = loss_fct(active_logits, active_labels)
else: #不给labels是预测
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
outputs = (loss,) + outputs
return outputs # (loss), scores, (hidden_states), (attentions)
5.处理数据
利用NerDataset函数将命名实体数据集处理成第五节中提及的BertModel输入格式,如下图所示(bert),不同的bert模型需要处理成不同的格式,可以通过model_type参数进行调整。

6.开始训练
利用 Trainer.train 函数进行模型训练,Trainer 是一个简单但功能完整的PyTorch训练和eval循环方法,并针对 Transformers 进行了优化。简单介绍下流程
1)将训练、验证、测试数据集传入DataLoader
#测试集、验证集导入函数与此类似
def get_train_dataloader(self) -> DataLoader:
...
...
...
data_loader = DataLoader(
self.train_dataset,
batch_size=self.args.train_batch_size,
sampler=train_sampler,
collate_fn=self.data_collator.collate_batch,
)
return data_loader
2)设置优化函数
optimizer, scheduler = self.get_optimizers(num_training_steps=t_total)
3) 设置fp16精度、多gpu并行、分布式训练
if self.args.fp16:
if not is_apex_available():
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
model, optimizer = amp.initialize(model, optimizer, opt_level=self.args.fp16_opt_level)
# multi-gpu training (should be after apex fp16 initialization)
if self.args.n_gpu > 1:
model = torch.nn.DataParallel(model)
# Distributed training (should be after apex fp16 initialization)
if self.args.local_rank != -1:
model = torch.nn.parallel.DistributedDataParallel(
model,
device_ids=[self.args.local_rank],
output_device=self.args.local_rank,
find_unused_parameters=True,
)
transformers只加入了基本的常用操作,除此此外还可加入一些高阶训练技巧
4)是否冻结训练参数
no_decay = ["bias", "LayerNorm.weight"]
bert_param_optimizer = list(model.bert.named_parameters())
crf_param_optimizer = list(model.crf.named_parameters())
linear_param_optimizer = list(model.classifier.named_parameters())
optimizer_grouped_parameters = [
{'params': [p for n, p in bert_param_optimizer if not any(nd in n for nd in no_decay)],
'weight_decay': args.weight_decay, 'lr': args.learning_rate},
{'params': [p for n, p in bert_param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0,
'lr': args.learning_rate},
{'params': [p for n, p in crf_param_optimizer if not any(nd in n for nd in no_decay)],
'weight_decay': args.weight_decay,'lr': 0.001},
{'params': [p for n, p in crf_param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0,
'lr': 0.001},
{'params': [p for n, p in linear_param_optimizer if not any(nd in n for nd in no_decay)],
'weight_decay': args.weight_decay,'lr': 0.001},
{'params': [p for n, p in linear_param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0,
'lr': 0.001}
]
5)学习率退火
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=args.warmup_steps,
num_training_steps=t_total)
6)训练参数可视化
自己加入tensorboardX进行可视化调节训练进程
7)轮次训练迭代
7.测试评估和预测
略
参考文献
- HuggingFace-Transformers系列的介绍以及在下游任务中的使用
- 配置、使用transformers包
- bert模型简介、transformers中bert模型源码阅读、分类任务实战和难点总结
- 手把手教你用Pytorch-Transformers——部分源码解读及相关说明(一)
- Bert代码详解(一)