机器学习-LDA--景区评论分析 ipython
#导入所需基本包
import pandas as pd
import numpy as np
# 导入扩展库
import re # 正则表达式库
import jieba # 结巴分词
import jieba.posseg # 词性获取
import collections # 词频统计库
import csv #文件读写
import os
import pandas as pd
# 打开文件
path = 'A:\jupyter_code\模式识别期末论文\评论数据'
dirs = os.listdir( path ) #os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。
# 输出所有表格文件
excels=[]
i=0
for fname in dirs:
if 'xlsx' in fname: #搜索带有xlsx的文件,即读取所有.xlsx文件
print ('%-22s'%fname,'\t','标签取为:',i)
df = pd.read_excel('评论数据/'+fname)
df['标签']=str(i) #添加标签
excels.append(df)
i+=1
a = pd.concat(excels) #纵向合并
#评论内容去重
a = a.dropna(subset=['评分']) #删除评分为空值的行
print('去重之前:',a.shape[0])
a=a.drop_duplicates(subset=['评论内容'])
print('去重之后:',a.shape[0])
a.to_excel('景区评论.xlsx',index=False) #保存文件
丽江古城.xlsx 标签取为: 0
九寨沟.xlsx 标签取为: 1
伦敦眼.xlsx 标签取为: 2
卢浮宫博物馆.xlsx 标签取为: 3
张家界.xlsx 标签取为: 4
杭州西湖.xlsx 标签取为: 5
洱海.xlsx 标签取为: 6
都江堰景区.xlsx 标签取为: 7
雅典卫城.xlsx 标签取为: 8
鼓浪屿.xlsx 标签取为: 9
去重之前: 25789
去重之后: 23811
import pandas as pd
data = pd.read_excel('景区评论.xlsx')
去重之前: 23811
去重之后: 23811
词频统计
import jieba # 结巴分词
import jieba.posseg # 词性获取
import collections # 词频统计库
import re # 正则表达式
import csv #文件读写
import pandas as pd
data = pd.read_excel('景区评论.xlsx')
stopWords = pd.read_csv('stopword.txt',encoding='utf-8', sep='lipingliping', header=None)
custom_stopWords = pd.read_csv('自定义停用词.txt',encoding='utf-8', sep='lipingliping',header=None)
adverbWords = pd.read_csv('程度副词.txt',encoding='utf-8', sep='lipingliping',header=None)
stop = list(stopWords.iloc[:, 0])+list(custom_stopWords.iloc[:, 0])+list(adverbWords.iloc[:, 0])#将停用词写入列表
#景区热词表名
name=['丽江古城热词','九寨沟热词','伦敦眼热词','卢浮宫博物馆热词','张家界热词','杭州西湖热词','洱海热词','都江堰景区热词','雅典卫城热词','鼓浪屿热词']
j=0
for labels in range(0,10):
data01=(''.join(str(i) for i in data.loc[data["标签"]==labels,"评论内容"]))
#预处理
pattern = re.compile(u'\t|\n|\.|-|:|;|\)|\(|\?|\ |"\|~·@¥……*|“”|‘’|()|{}|') # 定义正则表达式匹配模式(空格等)
data02 = re.sub(pattern, '', data01) # 将符合模式的字符去除
data_cut = jieba.cut(data02,cut_all=False,HMM=True)
data_stop = []
#去除停用词(目的是去掉一些意义不大的词)
for word in data_cut: # 循环读出每个分词
if word not in stop: # 如果不在去除词库中
data_stop.append(word) # 分词追加到列表
word_counts = collections.Counter(data_stop) # 对分词做词频统计
word_counts_top = word_counts.most_common(20) # 获取前20个最高频的词
print(word_counts_top)
words_cloud_A = open('A:/jupyter_code/模式识别期末论文/景区热词表/'+name[j]+'.csv', 'w', newline = '') #打开景区热词表格文件,若表格文件不存在则创建
write = csv.writer(words_cloud_A) #创建一个csv的writer对象用于写每一行内容
write.writerow(['评论热词','热度']) #写表格表头
item = list(word_counts.items()) #将字典转化为列表格式
item.sort(key = lambda x: x[1], reverse = True) #对列表按照第二列进行排序
for k in range(20):
write.writerow(item[k])#把前20词语写入表格
words_cloud_A.close()
j+=1
:10: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.
stopWords = pd.read_csv('stopword.txt',encoding='utf-8', sep='lipingliping', header=None)
:11: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.
custom_stopWords = pd.read_csv('自定义停用词.txt',encoding='utf-8', sep='lipingliping',header=None)
:12: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.
adverbWords = pd.read_csv('程度副词.txt',encoding='utf-8', sep='lipingliping',header=None)
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\28138\AppData\Local\Temp\jieba.cache
Loading model cost 0.663 seconds.
Prefix dict has been built successfully.
[('地方', 649), ('晚上', 485), ('酒吧', 469), ('不错', 459), ('客栈', 434), ('喜欢', 434), ('值得', 408), ('感觉', 353), ('里', 334), ('特色', 328), ('景色', 306), ('住', 299), ('吃', 290), ('商业化', 284), ('走', 275), ('热闹', 275), ('大研', 268), ('四方街', 265), ('美', 255), ('木府', 230)]
[('景色', 882), ('不错', 653), ('值得', 498), ('九寨', 477), ('美', 459), ('风景', 346), ('瀑布', 243), ('地方', 228), ('推荐', 223), ('看水', 213), ('水', 213), ('总体', 206), ('归来', 205), ('好玩', 193), ('有趣', 186), ('性价比', 182), ('体验', 179), ('超赞', 178), ('高', 177), ('海', 167)]
[('摩天轮', 528), ('排队', 456), ('泰晤士河', 314), ('不错', 260), ('俯瞰', 227), ('景色', 222), ('时间', 217), ('晚上', 201), ('值得', 200), ('地标', 196), ('坐', 182), ('快速通道', 179), ('世界', 167), ('建筑', 167), ('夜景', 163), ('美', 142), ('乘坐', 138), ('地方', 135), ('携程', 134), ('英国', 133)]
[('艺术', 738), ('蒙娜丽莎', 665), ('时间', 594), ('巴黎', 578), ('世界', 534), ('排队', 532), ('法国', 466), ('维纳斯', 398), ('值得', 377), ('参观', 375), ('金字塔', 335), ('建筑', 330), ('胜利', 305), ('雕塑', 304), ('女神', 297), ('著名', 295), ('地方', 284), ('三宝', 274), ('讲解', 271), ('小时', 262)]
[('景色', 1060), ('不错', 842), ('值得', 584), ('走', 510), ('索道', 490), ('天子山', 479), ('玩', 464), ('袁家界', 459), ('门票', 444), ('风景', 413), ('坐', 407), ('时间', 390), ('森林公园', 378), ('杨家', 358), ('界', 342), ('溪', 324), ('金鞭', 323), ('十里', 322), ('画廊', 320), ('国家森林公园', 313)]
[('景色', 522), ('不错', 431), ('美', 398), ('美景', 385), ('走', 298), ('风景', 291), ('地方', 287), ('断桥', 264), ('雷峰塔', 238), ('值得', 233), ('感觉', 224), ('苏堤', 192), ('喜欢', 173), ('美丽', 159), ('坐', 151), ('十景', 151), ('中', 143), ('三潭印月', 141), ('时间', 139), ('荷花', 138)]
[('地方', 587), ('美', 580), ('苍山', 558), ('景色', 477), ('双廊', 444), ('不错', 432), ('风景', 404), ('环海', 332), ('值得', 318), ('住', 312), ('感觉', 305), ('环', 260), ('骑行', 247), ('租', 247), ('云南', 242), ('时间', 213), ('拍照', 212), ('电动车', 203), ('海', 201), ('建议', 185)]
[('不错', 642), ('水利工程', 626), ('景色', 566), ('值得', 499), ('智慧', 475), ('古人', 368), ('讲解', 251), ('地方', 241), ('走', 234), ('历史', 223), ('李冰', 214), ('导游', 208), ('风景', 199), ('性价比', 176), ('推荐', 169), ('总体', 169), ('宝瓶口', 163), ('好好', 163), ('时间', 162), ('高', 162)]
[('神庙', 260), ('希腊', 243), ('建筑', 189), ('历史', 176), ('古希腊', 124), ('地方', 108), ('雅典娜', 106), ('值得', 94), ('城市', 90), ('中', 87), ('帕特农', 81), ('文明', 81), ('神殿', 67), ('壮观', 65), ('感觉', 64), ('世界', 63), ('震撼', 59), ('古老', 57), ('遗迹', 54), ('文化', 52)]
[('岛上', 839), ('厦门', 789), ('不错', 785), ('地方', 514), ('景色', 487), ('值得', 470), ('日光岩', 418), ('码头', 390), ('建筑', 347), ('吃', 294), ('时间', 258), ('风景', 251), ('住', 246), ('适合', 244), ('感觉', 233), ('岛', 231), ('走', 231), ('推荐', 213), ('钢琴', 208), ('菽庄花园', 208)]
LDA主题分析
import jieba # 结巴分词
import jieba.posseg # 词性获取
import collections # 词频统计库
import re # 正则表达式
import csv #文件读写
import pandas as pd
data = pd.read_excel('景区评论.xlsx')
stopWords = pd.read_csv('stopword.txt',encoding='utf-8', sep='lipingliping', header=None)
custom_stopWords = pd.read_csv('自定义停用词.txt',encoding='utf-8', sep='lipingliping',header=None)
adverbWords = pd.read_csv('程度副词.txt',encoding='utf-8', sep='lipingliping',header=None)
stop = list(stopWords.iloc[:, 0])+list(custom_stopWords.iloc[:, 0])+list(adverbWords.iloc[:, 0])+[' ','\n','\t']#将停用词写入列表
:9: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.
stopWords = pd.read_csv('stopword.txt',encoding='utf-8', sep='lipingliping', header=None)
:10: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.
custom_stopWords = pd.read_csv('自定义停用词.txt',encoding='utf-8', sep='lipingliping',header=None)
:11: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.
adverbWords = pd.read_csv('程度副词.txt',encoding='utf-8', sep='lipingliping',header=None)
data0 = data.loc[data['标签']==0, ['评分','评论内容']]
data1 = data.loc[data['标签']==1, ['评分','评论内容']]
data2 = data.loc[data['标签']==2, ['评分','评论内容']]
data3 = data.loc[data['标签']==3, ['评分','评论内容']]
data4 = data.loc[data['标签']==4, ['评分','评论内容']]
data5 = data.loc[data['标签']==5, ['评分','评论内容']]
data6 = data.loc[data['标签']==6, ['评分','评论内容']]
data7 = data.loc[data['标签']==7, ['评分','评论内容']]
data8 = data.loc[data['标签']==8, ['评分','评论内容']]
data9 = data.loc[data['标签']==9, ['评分','评论内容']]
data_pos=data9.loc[data9["评分"]>=4,"评论内容"]
data_neg=data9.loc[data9["评分"]<=2,"评论内容"]
data_pos_cut = data_pos.astype('str').apply(lambda x: jieba.lcut(x))
data_neg_cut = data_neg.astype('str').apply(lambda x: jieba.lcut(x))
pos = data_pos_cut.apply(lambda x: [i for i in x if i not in stop])
neg = data_neg_cut.apply(lambda x: [i for i in x if i not in stop])
# 导入情感评价表
feeling = pd.read_csv('BosonNLP_sentiment_score.txt', sep=' ', header=None, encoding='utf-8')
# 改变列名
feeling.columns = ['word', 'score']
#feeling
# 将felling中的word字段转化为列表
feel = list(feeling['word'])
# 自定义查分函数
def classfi(my_list):
SumScore = 0
for i in my_list:
if i in feel:
SumScore += feeling['score'][feel.index(i)]
return SumScore
# 运算时间较长
pos_score = pos.apply(lambda x: classfi(x))
neg_score = neg.apply(lambda x: classfi(x))
# 导入扩展库
import re # 正则表达式库
import jieba # 结巴分词
import gensim
from gensim import corpora, models, similarities
neg_feel = pd.concat((neg_score,neg),axis=1)
pos_feel = pd.concat((pos_score,pos), axis=1)
# 改变列名,便于查看
pos_feel.columns = ['评分', '评论']
neg_feel.columns = ['评分', '评论']
# 主题分析
# 建立词典
pos_dict = corpora.Dictionary(pos_feel['评论'])
neg_dict = corpora.Dictionary(neg_feel['评论'])
# 建立语料库
pos_corpus = [pos_dict.doc2bow(i) for i in pos_feel['评论']]
neg_corpus = [neg_dict.doc2bow(i) for i in neg_feel['评论']]
# LDA模型训练
pos_lda = models.LdaModel(pos_corpus, num_topics=3, id2word=pos_dict)
neg_lda = models.LdaModel(neg_corpus, num_topics=3, id2word=neg_dict)
print("\n正面评价")
# 输出每个主题
for i in range(3):
print("主题%d : " % i)
print(pos_lda.print_topic(i))
print("\n负面评价")
# 输出每个主题
for i in range(3):
print("主题%d : " % i)
print(neg_lda.print_topic(i))
正面评价
主题0 :
0.008*"地方" + 0.008*"景色" + 0.007*"值得" + 0.006*"不错" + 0.006*"美丽" + 0.005*"美" + 0.004*"走" + 0.003*"总" + 0.003*"断桥" + 0.003*"相宜"
主题1 :
0.016*"美景" + 0.010*"风景" + 0.009*"景色" + 0.007*"上有天堂" + 0.006*"下有苏杭" + 0.006*"喜欢" + 0.005*"地方" + 0.005*"喷泉" + 0.004*"美丽" + 0.004*"游船"
主题2 :
0.014*"不错" + 0.014*"美" + 0.012*"景色" + 0.009*"断桥" + 0.008*"走" + 0.008*"值得" + 0.008*"雷峰塔" + 0.006*"美景" + 0.006*"感觉" + 0.006*"地方"
负面评价
主题0 :
0.020*"小时" + 0.018*"套餐" + 0.017*"导游" + 0.016*"船上" + 0.016*"雷峰塔" + 0.013*"10" + 0.013*"坐船" + 0.013*"现场" + 0.013*"坐" + 0.013*"开水"
主题1 :
0.017*"小时" + 0.016*"号" + 0.016*"请问" + 0.016*"账" + 0.016*"消息" + 0.016*"退票" + 0.016*"回复" + 0.015*"船上" + 0.014*"导游" + 0.013*"套餐"
主题2 :
0.029*"纯净水" + 0.021*"高" + 0.020*"一瓶" + 0.018*"10" + 0.017*"小时" + 0.014*"雷峰塔" + 0.012*"游客" + 0.012*"成本" + 0.012*"交通" + 0.012*"不可思议"
data01=(''.join(str(i) for i in data.loc[data["标签"]==labels,"评论内容"]))
#预处理
pattern = re.compile(u'\t|\n|\.|-|:|;|\)|\(|\?|\ |"') # 定义正则表达式匹配模式(空格等)
data02 = re.sub(pattern, '', data01) # 将符合模式的字符去除
data_cut = jieba.cut(data02,cut_all=False,HMM=True)
stopWords = pd.read_csv('stopword.txt',encoding='utf-8', sep='lipingliping', header=None)
custom_stopWords = pd.read_csv('自定义停用词.txt',encoding='utf-8', sep='lipingliping',header=None)
adverbWords = pd.read_csv('程度副词.txt',encoding='utf-8', sep='lipingliping',header=None)
stop = list(stopWords.iloc[:, 0])+list(custom_stopWords.iloc[:, 0])+list(adverbWords.iloc[:, 0])#将停用词写入列表
data_stop = []
#去除停用词(目的是去掉一些意义不大的词)
for word in data_cut: # 循环读出每个分词
if word not in stop: # 如果不在去除词库中
data_stop.append(word) # 分词追加到列表
import os
import jieba
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
from keras import models,layers
from keras.utils.np_utils import to_categorical
from keras.preprocessing.text import Tokenizer
from sklearn import metrics
from sklearn.naive_bayes import MultinomialNB
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
from sklearn.feature_selection import SelectKBest,f_classif
# 法2:tf-idf策略
tf_idf = TfidfVectorizer()
x_trian_vec = tf_idf.fit_transform(data_stop) #将训练集文本转换为TF-IDF权重矩阵
#x_test_vec = tf_idf.transform(X_test_cut) #将测试集文本转换为TF-IDF权重矩阵
x_trian_vec.shape #查看形状
data = pd.read_excel('景区评论.xlsx')
pos_data = data.loc[data['评分']>=4,['评分','评论内容']]
neg_data = data.loc[data['评分']<=3,['评分','评论内容']]
pos_data['评分']=0
neg_data['评分']=1
data01
| 评分 | 评论内容 | |
|---|---|---|
| 0 | 0 | 这到底是怎么一回事,身边竟然好多朋友都在问我:“我在丽江 ,怎么只看到了束河古镇,可是旅游票... |
| 1 | 0 | 丽江有三大古城, #大研古镇 (又名丽江古城)是规模最大也最受欢迎的一个,来丽江就没有人能逃... |
| 2 | 0 | 春节长假的最后一天去丽江古城转了下,简直惊呆了,游客超级少,和我几年前去过丽江时完全不能比... |
| 3 | 0 | 丽江古城又名大研镇,它位于丽江坝中部,北依象山、金虹山、西枕狮子山,东南面临数十里的良田阔野... |
| 4 | 0 | 丽江古城,三个古镇中大研最大、最知名,人最多,商业化程度也最高。爱热闹,喜欢夜生活,选这里就... |
| ... | ... | ... |
| 23762 | 1 | 规模很小,表演因为天热海狮不配合。可玩性低, |
| 23763 | 1 | 吃的和其他景点美食差不多,不要排队吃东西,绝对后悔,开放的景点不多,路边的别墅衰败的厉害有些... |
| 23782 | 1 | 性价比低,可玩性低,有待改进,景色一般, |
| 23785 | 1 | 携程上订票只有一个套餐,是和岛上一个旅游景点一起的优惠门票,我觉得不实惠,我买一张成人一张儿... |
| 23786 | 1 | 中山路的轮渡那么近又方便,为什么给弄到夏鼓码头啊,又远停车又不方便,说停车4元每小时,我们停... |
23811 rows × 2 columns
data0 = pos_data.loc[pos_data['评分']==0].sample(901,random_state=123)
data1 = neg_data.loc[neg_data['评分']==1].sample(901,random_state=123)
data01 = pd.concat([data0,data1],axis=0)
data01.columns=['标签','评论内容']
data01
| 标签 | 评论内容 | |
|---|---|---|
| 11504 | 0 | 确实不错,空气清新,还有野生猕猴,值得游玩个三五天 |
| 4491 | 0 | 刚好遇到好天气,出沟的时候遇到下雪了,第一次见下雪,很美 |
| 11303 | 0 | 门票领了优惠券便宜了点 运气很好 天气不错 虽然有点晒 但是天空很美 空气很新鲜 |
| 16861 | 0 | 推荐。苍山雪,洱海月。去的那几天天气不错,坐在海边晒晒太阳吹吹风,简直惬意的不要不要的。虽然... |
| 15561 | 0 | 到大理主要就是围绕着洱海旅游,洱海很大,景点都分散在环海周边,年轻人可以选择租车或者骑行,老... |
| ... | ... | ... |
| 3661 | 1 | 景区面积很大,游客不少。空气清新,景色秀丽 |
| 10429 | 1 | 也许是来之前心理预期太高,反而没啥太大意思,景区里没什么人很悠闲,但是也正因为人少.5点半走... |
| 11330 | 1 | 可玩性低,性价比低,有待改进,怀着10多年的向往和激动的心情终于来到了张家界国家森林公园,2... |
| 11079 | 1 | 如果考虑看风景:不推荐。假如电梯人客满,不在玻璃面前就看不到任何景色\n如果考虑代步:推荐,... |
| 15760 | 1 | 路线设计不合理 |
1802 rows × 2 columns
import jieba
data_cut = data01['评论内容'].apply(jieba.lcut)
data01_cut=data_cut.apply(lambda x:' '.join(x))
data01_cut
11504 确实 不错 , 空气清新 , 还有 野生 猕猴 , 值得 游玩 个 三五天
4491 刚好 遇到 好 天气 , 出沟 的 时候 遇到 下雪 了 , 第一次 见 下雪 , 很 美
11303 门票 领了 优惠券 便宜 了 点 运气 很 好 天气 不错 虽然 有点 晒 ...
16861 推荐 。 苍山 雪 , 洱海 月 。 去 的 那 几天 天气 不错 , 坐在 海边 晒 晒太...
15561 到 大理 主要 就是 围绕 着 洱海 旅游 , 洱海 很大 , 景点 都 分散 在 环海 周...
...
3661 景区 面积 很大 , 游客 不少 。 空气清新 , 景色 秀丽
10429 也许 是 来 之前 心理 预期 太高 , 反而 没 啥 太大 意思 , 景区 里 没什么 人...
11330 可玩性 低 , 性价比 低 , 有待 改进 , 怀着 10 多年 的 向往 和 激动 的 心...
11079 如果 考虑 看 风景 : 不 推荐 。 假如 电梯 人 客满 , 不 在 玻璃 面前 就 看...
15760 路线 设计 不合理
Name: 评论内容, Length: 1802, dtype: object
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
cv = CountVectorizer().fit(data01_cut)
cv_data=cv.transform(data01_cut)
cv_data.toarray()
array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=int64)
from sklearn.naive_bayes import MultinomialNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import LinearSVC
from sklearn.model_selection import train_test_split
from sklearn import svm
cv_train,cv_test,y_train,y_test = train_test_split(
cv_data,data01['标签'],
test_size=0.2,random_state=345)
model_nb=MultinomialNB(alpha=0.01).fit(X_train,data01['标签'])
model_nb.score(X_train,data01['标签'])
0.974472807991121
model_nb1=MultinomialNB(alpha=0.00001).fit(cv_train,y_train)
model_nb1.score(cv_test,y_test)
0.703601108033241
model_knn = KNeighborsClassifier().fit(cv_data,data01['标签'])
model_knn.score(cv_data,data01['标签'])
0.7708102108768036
model_knn1 = KNeighborsClassifier().fit(cv_train,y_train)
model_knn1.score(cv_test,y_test)
0.6537396121883656
model_svc = LinearSVC().fit(cv_data,data01['标签'])
model_svc.score(cv_data,data01['标签'])
0.9961154273029966
model_svc1 = LinearSVC().fit(cv_train,y_train)
model_svc1.score(cv_test,y_test)
0.7257617728531855
模型评估
from sklearn.metrics import classification_report,confusion_matrix
y_pre_nb1 = model_nb1.predict(cv_test)
print(classification_report(y_true=y_test,y_pred=y_pre_nb1))
print(confusion_matrix(y_true=y_test,y_pred=y_pre_nb1))
precision recall f1-score support
0 0.72 0.71 0.71 187
1 0.69 0.70 0.69 174
accuracy 0.70 361
macro avg 0.70 0.70 0.70 361
weighted avg 0.70 0.70 0.70 361
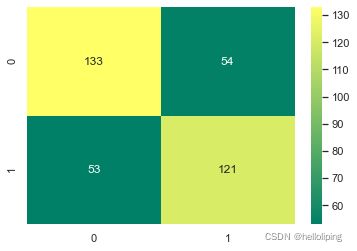
[[133 54]
[ 53 121]]
y_pre_knn1 = model_knn1.predict(cv_test)
print(classification_report(y_true=y_test,y_pred=y_pre_knn1))
print(confusion_matrix(y_true=y_test,y_pred=y_pre_knn1))
precision recall f1-score support
0 0.74 0.79 0.76 187
1 0.75 0.71 0.73 174
accuracy 0.75 361
macro avg 0.75 0.75 0.75 361
weighted avg 0.75 0.75 0.75 361
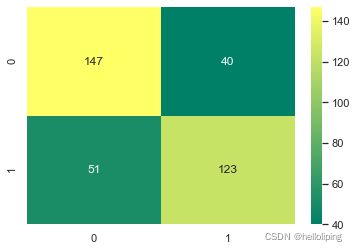
[[147 40]
[ 51 123]]
y_pre_svc1 = model_svc1.predict(cv_test)
print(classification_report(y_true=y_test,y_pred=y_pre_svc1))
print(confusion_matrix(y_true=y_test,y_pred=y_pre_svc1))
cm=confusion_matrix(y_true=y_test,y_pred=y_pre_svc1)
cm
precision recall f1-score support
0 0.72 0.74 0.73 187
1 0.71 0.69 0.70 174
accuracy 0.72 361
macro avg 0.72 0.72 0.72 361
weighted avg 0.72 0.72 0.72 361
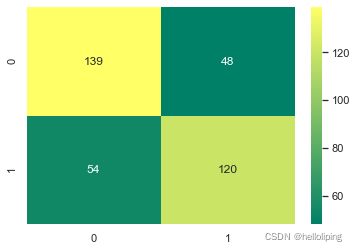
[[139 48]
[ 54 120]]
array([[139, 48],
[ 54, 120]], dtype=int64)
import seaborn as sns
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
sns.set()
C1=confusion_matrix(y_true=y_test,y_pred=y_pre_nb1)
C2=confusion_matrix(y_true=y_test,y_pred=y_pre_knn1)
C3= confusion_matrix(y_true=y_test,y_pred=y_pre_svc1)
sns.heatmap(C1,annot=True,cmap='summer',fmt='g')
sns.heatmap(C2,annot=True,cmap='summer',fmt='g')
sns.heatmap(C3,annot=True,cmap='summer',fmt='g')
具体代码和数据集请到以下链接下载
机器学习-景区文本分析