零售行业交易数据分析(2)——RFM模型分类及可视化(Python实现)
内容简介
接上一篇文章《客户终身价值(CLTV)计算和回归预测模型》,本文继续分析一年的零售交易数据,从用户的角度,使用RFM模型对用户进行打分归类,并对结果进行可视化展示。
数据集介绍
数据集包含一家在英国注册的在线零售公司于 01/12/2010 和 09/12/2011 之间发生的所有交易。该公司主要销售各种场合的礼品,公司的许多客户都是批发商。
数据集一共包含8列:
- InvoiceNo:发票编号。标称,为每笔交易唯一分配的 6 位整数。如果此代码以字母“c”开头,则表示取消。
- StockCode:商品(商品)代码。标称,为每个不同的产品唯一分配的 5 位整数。
- Description: 描述。 产品(项目)名称。
- Quantity:数量。每笔交易每个产品(项目)的数量。
- InvoiceDate:发票日期和时间,每笔交易产生的日期和时间。
- UnitPrice:单价,单位产品价格(以英镑为单位)。
- CustomerID:客户编号,一个唯一分配给每个客户的 5 位整数。
- Country:国名,每个客户所在国家/地区的名称。
数据预处理
1. 导入包和封装预处理过程
先导入要使用的包和封装好的预处理过程。
import os
import datetime
import squarify
import warnings
import pandas as pd
import numpy as np
import datetime as dt
from operator import attrgetter
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
import plotly.graph_objs as go
from plotly.offline import iplot
from sklearn.metrics import (silhouette_score,
calinski_harabasz_score,
davies_bouldin_score)
from lifetimes import BetaGeoFitter, GammaGammaFitter
from lifetimes.plotting import plot_period_transactions
%matplotlib inline
#%load_ext nb_black
warnings.filterwarnings('ignore')
sns.set_style('whitegrid')
palette = 'Set2'
def replace_with_thresholds(dataframe, variable, q1 = 0.25, q3 = 0.75):
'''
Detects outliers with IQR method and replaces with thresholds
'''
df_ = dataframe.copy()
quartile1 = df_[variable].quantile(q1)
quartile3 = df_[variable].quantile(q3)
iqr = quartile3 - quartile1
up_limit = quartile3 + 1.5 * iqr
low_limit = quartile1 - 1.5 * iqr
df_.loc[(df_[variable] < low_limit), variable] = low_limit
df_.loc[(df_[variable] > up_limit), variable] = up_limit
return df_
def ecommerce_preprocess(dataframe):
df_ = dataframe.copy()
#Missing Values
df_ = df_.dropna()
#Cancelled Orders & Quantity
df_ = df_[~df_['InvoiceNo'].str.contains('C', na = False)]
df_ = df_[df_['Quantity'] > 0]
#Replacing Outliers
df_ = replace_with_thresholds(df_, "Quantity", q1 = 0.01, q3 = 0.99)
df_ = replace_with_thresholds(df_, "UnitPrice", q1 = 0.01, q3 = 0.99)
#Total Price
df_["TotalPrice"] = df_["Quantity"] * df_["UnitPrice"]
return df_
2. 数据导入
导入的同时指定好个列的数据格式,就可以直接使用上面封装好的函数对数据进行预处理。
预处理的过程这里直接跳过,具体的处理过程在《客户终身价值(CLTV)计算和回归预测模型》这篇文章中由比较详细的解释。
#数据导入
df=pd.read_csv("data.csv",encoding="utf-8",
dtype = {'CustomerID': str,
'InvoiceID': str},
parse_dates = ['InvoiceDate'],
infer_datetime_format = True)
df = ecommerce_preprocess(df)
df.describe()
RFM模型分析
RFM模型介绍
RFM模型是客户关系管理(CRM)中被广泛使用,是衡量客户价值的重要工具。通过客户的近期交易行为、交易频率和交易金额三项指标,将客户划分为不同类型:
- R(Recency): 计算最近的一次消费时间距离2017年12月3日有多久。消费间隔越小,表示R值越小,价值越高。
- F(Frequency):消费频率,在这个时间段里,用户消费的次数。
- M(Monetary): 消费金额,用户消费的总金额。
在SQL淘宝用户数据分析文章中,也使用到了RFM分析方法,是比较常用的用户分析模型。
1.分别计算R、F、M维度的值。
today_date = dt.datetime(2011,12,11)
rfm = df.groupby('CustomerID').agg({'InvoiceDate': lambda x: (today_date - x.max()).days,
'InvoiceNo': lambda x: x.nunique(),
'TotalPrice': lambda x: x.sum()})
rfm.columns = ['recency', 'frequency', 'monetary']
rfm= rfm[rfm['monetary'] > 0]
rfm = rfm.reset_index()
rfm.head()
2.汇总RFM分数并对用户分类
将计算好的RFM的值按照各自的分位数,分成1-5等分,然后组合成最终的RFM分数。
由于三个维度分别由5个等级,用户分数类别有555=125种不同的排列组合。为了简化过程,这里我们先使用R和F两个维度对用户进行简单的分类。
def get_rfm_scores(dataframe):
df_ = dataframe.copy()
df_['recency_score'] = pd.qcut(df_['recency'],5,labels = [5, 4, 3, 2, 1])
df_['frequency_score'] = pd.qcut(df_['frequency'].rank(method = "first"), 5, labels = [1, 2, 3, 4, 5])
df_['monetary_score'] = pd.qcut(df_['monetary'], 5, labels = [1, 2, 3, 4, 5])
df_['RFM_SCORE'] = (df_['recency_score'].astype(str) + df_['frequency_score'].astype(str)+ df_['monetary_score'].astype(str))
return df_
rfm = get_rfm_scores(rfm)
seg_map = {
r'[1-2][1-2]': 'Hibernating',
r'[1-2][3-4]': 'At Risk',
r'[1-2]5': 'Can\'t Loose',
r'3[1-2]': 'About to Sleep',
r'33': 'Need Attention',
r'[3-4][4-5]': 'Loyal Customers',
r'41': 'Promising',
r'51': 'New Customers',
r'[4-5][2-3]': 'Potential Loyalists',
r'5[4-5]': 'Champions'
}
rfm['segment'] = rfm['recency_score'].astype(str) +rfm['frequency_score'].astype(str)
rfm['segment'] = rfm['segment'].replace(seg_map, regex = True)
rfm.head()

3. RFM模型结果评估
#model evaluation
print(' RFM Model Evaluation '.center(70, '='))
X = rfm[['recency_score', 'frequency_score']]
labels = rfm['segment']
print(f'Number of Observations: {X.shape[0]}')
print(f'Number of Segments: {labels.nunique()}')
print(f'Silhouette Score: {round(silhouette_score(X, labels), 3)}')
print(f'Calinski Harabasz Score: {round(calinski_harabasz_score(X, labels), 3)}')
print(f'Davies Bouldin Score: {round(davies_bouldin_score(X, labels), 3)} \n{70*"="}')

对不同客户群体的RFM数值进行描述性分析
rfm[['recency','monetary','frequency','segment']]\
.groupby('segment')\
.agg({'mean','std','max','min'})

数据结果可视化
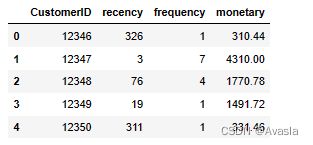
1.树状图
segments = rfm['segment'].value_counts().sort_values(ascending = False)
fig = plt.gcf()
ax = fig.add_subplot()
fig.set_size_inches(16, 10)
squarify.plot(sizes=segments,
label=[label for label in seg_map.values()],
pad = False,
bar_kwargs = {'alpha': 1},
text_kwargs = {'fontsize':15})
plt.title("Customer Segmentation Map", fontsize = 20)
plt.xlabel('Frequency', fontsize = 18)
plt.ylabel('Recency', fontsize = 18)
plt.show()
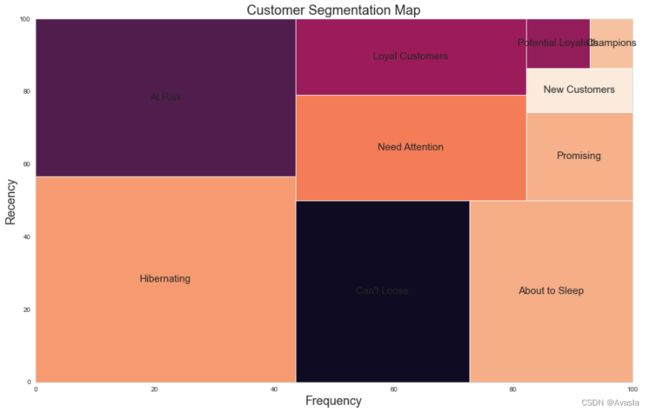
2.柱状图
plt.figure(figsize = (18, 8))
ax = sns.countplot(data = rfm,
x = 'segment',
palette = palette)
total = len(rfm.segment)
for patch in ax.patches:
percentage = '{:.1f}%'.format(100 * patch.get_height()/total)
x = patch.get_x() + patch.get_width() / 2 - 0.17
y = patch.get_y() + patch.get_height() * 1.005
ax.annotate(percentage, (x, y), size = 14)
plt.title('Number of Customers by Segments', size = 16)
plt.xlabel('Segment', size = 14)
plt.ylabel('Count', size = 14)
plt.xticks(size = 10)
plt.yticks(size = 10)
plt.show()
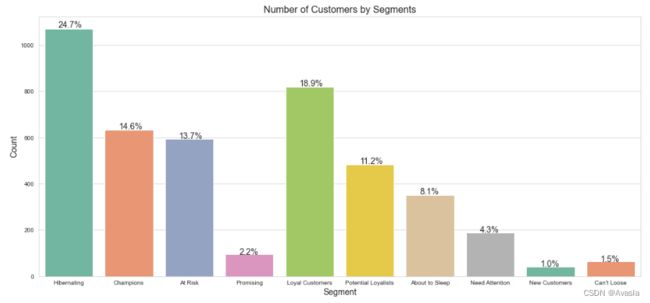
3.根据R、F、M三个维度查看客户分布情况
fig, axes = plt.subplots(3, 1, figsize=(16, 12))
fig.suptitle('RFM Segment Analysis', size = 14)
feature_list = ['recency', 'monetary', 'frequency']
for idx, col in enumerate(feature_list):
sns.histplot(ax = axes[idx], data = rfm,
hue = 'segment', x = feature_list[idx],
palette= palette)
if idx == 1:
axes[idx].set_xlim([0, 400])
if idx == 2:
axes[idx].set_xlim([0, 30])
plt.tight_layout()
plt.show()
4. R、F、M分布情况
首先,分别查看三个维度分数的分布。
# plot the distribution of customers over R and F
fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(15, 4))
for i, p in enumerate(['recency_score', 'recency_score', 'monetary_score']):
parameters = {'recency_score':'recency', 'recency_score':'frequency','monetary_score':'monetary'}
y = rfm[p].value_counts().sort_index()
x = y.index
ax = axes[i]
bars = ax.bar(x, y, color='silver')
ax.set_frame_on(False)
ax.tick_params(left=False, labelleft=False, bottom=False)
ax.set_title('Distribution of {}'.format(parameters[p]),
fontsize=14)
for bar in bars:
value = bar.get_height()
if value == y.max():
bar.set_color('firebrick')
ax.text(bar.get_x() + bar.get_width() / 2,
value - 5,
'{}\n({}%)'.format(int(value), int(value * 100 / y.sum())),
ha='center',
va='top',
color='w')
plt.show()

结果显示,整体都是比较均匀地分布,都是在19%-20%。
接下来看对于不同的R和F,M的分布情况如何。
# plot the distribution of M for RF score
fig, axes = plt.subplots(nrows=5, ncols=5,
sharex=False, sharey=True,
figsize=(10, 10))
r_range = range(1, 6)
f_range = range(1, 6)
for r in r_range:
for f in f_range:
y = rfm[(rfm['recency_score'] == r) & (rfm['frequency_score'] == f)]['monetary_score'].value_counts().sort_index()
x = y.index
ax = axes[r - 1, f - 1]
bars = ax.bar(x, y, color='silver')
if r == 5:
if f == 3:
ax.set_xlabel('{}\nF'.format(f), va='top')
else:
ax.set_xlabel('{}\n'.format(f), va='top')
if f == 1:
if r == 3:
ax.set_ylabel('R\n{}'.format(r))
else:
ax.set_ylabel(r)
ax.set_frame_on(False)
ax.tick_params(left=False, labelleft=False, bottom=False)
ax.set_xticks(x)
ax.set_xticklabels(x, fontsize=8)
for bar in bars:
value = bar.get_height()
if value == y.max():
bar.set_color('firebrick')
ax.text(bar.get_x() + bar.get_width() / 2,
value,
int(value),
ha='center',
va='bottom',
color='k')
fig.suptitle('Distribution of M for each F and R',
fontsize=14)
plt.tight_layout()
plt.show()

从上面图可以看出,数据主要集中在左上角和右下角:左上角是交易次数最少(F:1-2)并且交易金额也是集中在(M:1-2),表明有许多客户是一次性交易就离开了;右下角可见,这一年中花费最多的客户(M=5),大多是交易活动频繁的熟客(F和R都为4-5)。