第1章: 知识图谱概述
知识图谱概述
知识图谱发展背景
知识图谱(Knowledge Graph)的概念由Google公司在2012年提出[1],是指其用于提升搜索引擎性能的知识库。
知识图谱以结构化的形式描述客观世界中的概念、实体及其之间的关系。如下图所示:
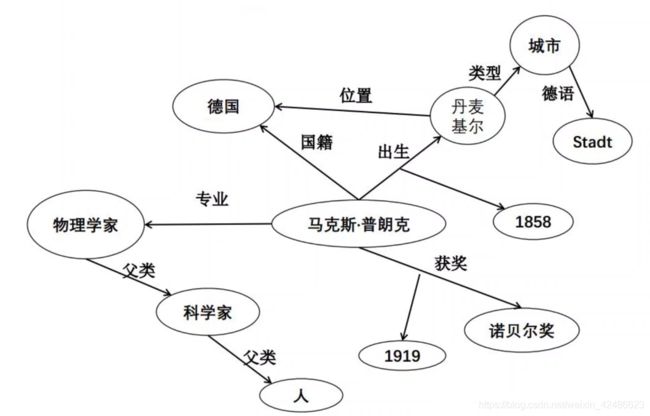 知识图谱涉及专家系统、语言学、语义网、数据库,以及信息抽取等众多领域
知识图谱涉及专家系统、语言学、语义网、数据库,以及信息抽取等众多领域
知识图的表现形式
包括:实体、属性、关系
节点是实体
节点有属性标签(可以包含类型)
两个节点的边是实体间关系
强调实体,但也可以描述概念

人工智能过去10年的标志性事件
- 2011年, IBM Watson在益智类节目《危险边缘》(Jeopardy)中战胜人类选手获得冠军。认知智能时代的到来(1.计算智能,2 感知智能, 3. 认知智能)
- 2011年,美军借助Palantir公司的技术成功定位本拉登藏身地。情报大数据分析(大数据+人工智能)
- 2016年Google的AlphaGo完胜人类围棋顶尖选手。2017年,进化版ALphaAero已经无敌手。(人工智能)
- 2017年,CMU研制的Libratus(冷扑大师)在20天德州扑克人机大战,战胜四位顶尖人类玩家。(计算能力的提升)

发展阶段–人工智能
- 1950-1970
- 后期人工智能发展遭遇瓶颈
- 马文阅斯基对感知器的激烈批评,联结主义(即神经网络)销声匿迹了10年
- 1970-1990
- 费根能姆提出“知识工程”
- 提出一阶谓词逻辑、框架、语义网络等知识表示方法
- 本体引入到人工智能领域来刻画知识
- CYC、WordNet
- 1990开始
- 统计机器学习逐渐占据主流
- 能较好的解决感知智能任务
知识图谱本质
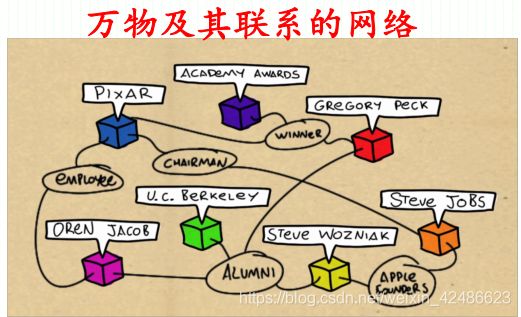
知识表示–语义网络
语义网络:表示概念间语义关系的网络
- 1956年提出,最初目的用于语言翻译和自然语言处理
- 1960s 1980s 2020s得到不断发展
- 经典语义网络项目: WordNet
 知识表示–框架(Frame)
知识表示–框架(Frame)

知识图谱的类型和代表性知识图谱
知识的分类
-1. 陈述性知识和过程性知识
2. 事实性(或者客观性)知识和主观性知识
3. 静态知识和动态知识
4. 百科知识、领域知识、场景知识、语言知识、常识知识等
语言知识图谱:主要是存储人类语言方面的知识
常识知识图谱:主要有Cyc和ConceptNet等
语言认知知识图谱:中文知网词库HowNet是一种典型的语言认知知识图谱
领域知识图谱:针对特定领域构建的知识图谱,专门为特定的领域服务
百科知识图谱:主要以Linked Open Data(LOD)项目支持的开放知识图谱为核心
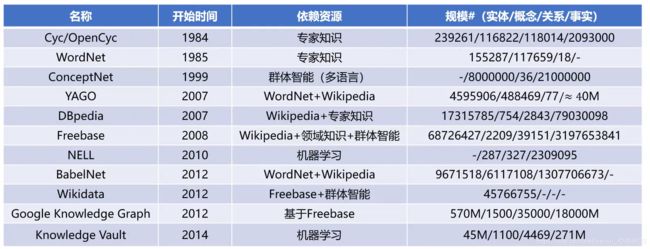
经典知识图谱
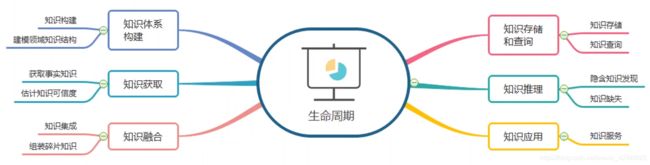
知识图谱生命周期
知识图谱构建
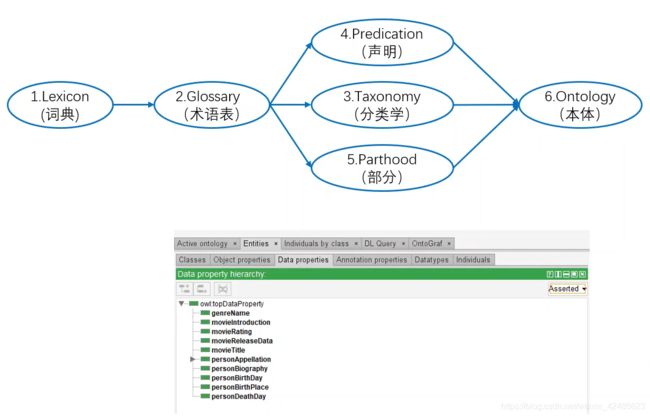
采用什么样的方式表达知识,其核心是构建一个本体对目标知识进行描述
- 在这个本体中需要定义出知识的类别体系;
- 每个类别下所属的概念和实体;
- 某类概念和实体所具有的属性以及概念之间、实体之间的语义关系;
- 同时也包括定义在这个本体上的一些推理规则。
Freebase的知识体系 - 定义了超过1.5万个概念类型和4,000个属性
- 对每个类型定义了若干关系,并制定关系的值域约束其取值。
 输入
输入
- 领域(医疗、金融)
- 应用场景
输出
- 领域实体类别体系
- 实体属性
- 领域语义关系
- 语义关系之间的关系
关键技术
- Ontology Engineering
作为语义网的应用,知识图谱的知识建模采用语义网的知识建模方式,分为概念、关系、概念关系三元组三个层次,并利用“资源描述框架(RDF)”进行描述。
RDF的基本数据模型包括了三个对象类型:
- 资源(Resource):能够使用RDF表示的对象称之为资源,包括互联网上的实体、事件和概念等;
- 谓词(Predicate):主要描述资源本身的特征和资源之间的关系;
- 陈述(Statements):一条陈述包含三个部分,通常称之为RDF
三元组<主体(subject),谓词(predicate),宾语(object)>。
知识获取

输入
- 领域知识本体
- 海量数据:文本、垂直站点、百科
输出:领域知识
- 实体集合
- 实体关系/属性
关键技术
- 信息抽取
- 文本挖掘
网络文本信息结构
 结构化数据
结构化数据
- 置信度高
- 规模小
- 缺乏个性化的属性信息
半结构化数据
- 规模较大
- 置信度较高
- 个性化的信息
- 形式多样
- 含有噪声
纯文本
- 置信度低
- 复杂多样
- 规模大
知识获取:实体识别
实体识别任务的目标是从文本中识别实体信息
- 例如,对于“姚明1981年出生于上海”,需要从中识别出“姚明”、“1981年”、“上海”三个实体,并确定实体的类别
早期有关实体识别的研究主要是针对命名实体的识别
- 命名实体指的是文本中具有特定意义的实体,一般包含三大类(实体类、时间类和数字类)、七小类(人名、地名、机构名、时间、日期、货币和百分比)
在知识图谱领域,从文本中识别实体不仅仅局限于命名实体,还包括其他类别的实体,特别是领域实体
- 例如:股票名、汽车品牌、餐馆名等
与实体识别相关的任务是实体抽取
- 目标是在给定语料的情况下,构建一个实体列表
- 例如:构建一个歌曲名列表
知识获取:实体消歧
目标是消除指定实体的歧义
- 对于“李娜于2011年获得法国网球公开赛的冠军”中的“李娜”,系统需要自动判别出这个实体指称项“李娜”指的是打网球的“李娜”,而不是其他的“李娜”
实体消歧对于知识图谱构建和应用有着重要的作用,也是建立语言表达和知识图谱联系的关键环节
从技术路线上划分,实体消歧任务可以分为实体链接和实体聚类两种类型
- 实体链接是将给定文本中的某一个实体指称项链接到已有知识图谱中的某一个实体上,因为在知识图谱中,每个实体具有唯一的编号,链接的结果就是消除了文本指称项的鼓义;
- 实体聚类的假设是已有知识图谱中并没有已经确定的实体,在给定一个语料库的前提下,通过聚类的方法消除语料中所有同一实体指称项的歧义,具有相同所指的实体指称项应该被聚为同一类别。
知识获取:关系抽取
目标是获取两个实体之间的语义关系。
- “姚明1981年出生于上海”,关系抽取需要识别出“姚明”和“上海”两个实体,并判别出它们之间具有“出生地“关系口语义关系
可以是一元关系(例如实体的类型),也可以是二元关系(例如实体的属性)甚至是更高阶的关系。
关系抽取对于构建知识图谱非常重要,是图谱中确定两个节点之间边上语义信息的关键环节。
关系抽取方法分类
- 有监督关系抽取、无监督关系抽取、弱监督关系抽取以及开放关系抽取等
知识获取:事件抽取
目标是从描述事件信息的文本中抽取出用户感兴趣的事件信息并以结构化的形式呈现出来。
事件是发生在某个特定的时间点或时间段、某个特定的地域范围内,由一个或者多个角色参与的,一个或者多个动作组成的
事情或者状态的改变。
- “成龙和林凤娇于1982年12月1日在洛杉矶举行婚礼”。
- 事件抽取的目标是识别出:
- 这个句子描述了一个“结婚事件:
- “结婚的双方”是“成龙”和“林风娇”;
- “结婚时间”是“1982年12月1日”;
- “结婚地点”是“洛杉矶”。
知识融合

任务:对不同来源、不同语言或不同结构的知识进行融合,,从而对于已经有的知识图谱进行补充、更新和去重。
输入
- 抽取出来的知识
- 现有知识库
- 知识本体
输出
- 统一知识库·知识置信度
关键技术
- Ontology Matching(本体匹配)
- Entity Linking(实体链接)
融合方式
从融合的对象看,知识融合分为知识体系的融合和实例的融合。核心问题是计算两个知识图谱中两个节点或边之间的语义映射关系。
- 知识体系的融合:两个或多个异构知识体系进行融合,即对相同的类别、属性、关系进行映射;
- 实例的融合:对于两个不同知识图谱中的实例(实体实例、关系实例)进行融合,包括不同知识体系下的实例、不同语言的实例。
从融合的知识图谱类型看,知识融合分为:竖直方向的融合和水平方向的融合
- 竖直方向的融合:融合(较)高层通用本体与(较)底层领域本体或实例数据(融合Wordnet和Wikipedia);
- 水平方向的融合:融合同层次的知识图谱,实现实例数据的互补(融合Freebase 和DBpedia).
知识存储和查询
任务:研究采用何种方式将已有知识图谱进行存储。
因为目前知识图谱大多是基于图的数据结构,它的存储方式主要有两种形式:
- RDF 格式存储:以三元组的形式存储数据
- Google开放的Freebase知识图谱,就是以文本的形式逐行存储三元组SPO(subject,predicate,object)
- 图数据库(Graph Database)
- 比RDF 数据库更加通用,目前典型的开源图数据库是Neo4j;
- 优点:具有完善的图查询语言,支持大多数的图挖捉算法;
- 缺点:数据更新慢,大节点的处理开销大。为了解决上述问题,子图筛选、子图同构判定等技术是目前图数据库的研究热点。
 输入
输入
- 大规模知识库知识(RDF等)
输出
- 知识库存储和查询服务
主要技术
- 知识表示
- 知识查询语言
- 存储/检索引擎
知识推理

由于处理数据的不完备性,知识图谱中肯定存在知识缺失现象(包括实体缺失、关系缺失)。
目前知识推理的研究主要集中在针对知识图谱中缺失关系的补足,即挖掘两个实体之间隐含的语义关系。所采用的方法可以分为两种:
- 基于传统逻辑规则的方法进行推理:研究热点在于如何自动学习推理规则,以及如何解决推理过程中的规则冲突问题:
- 基于表示学习的推理:采用学习的方式,将传统推理过程转化为基于分布式表示的语义向量相似度计算任务。这类方法优点是容错率高、可学习,缺点也显而易见,即不可解释,缺乏语义约束。
知识图谱的应用
知识图谱应用场景
- 辅助搜索–精准回答
- 提高搜素精度
- 语义搜索
- 搜素意图理解
- 多模态搜索
知识图谱落地模式


 金融证券领域
金融证券领域
企业风险评估:基于企业的基础信息、投资关系、诉讼、失信等多维度关联数据,利用图计算等方法构建科学、严谨的企业风险评估体系,有效规避潜在的经营风险与资金风险。
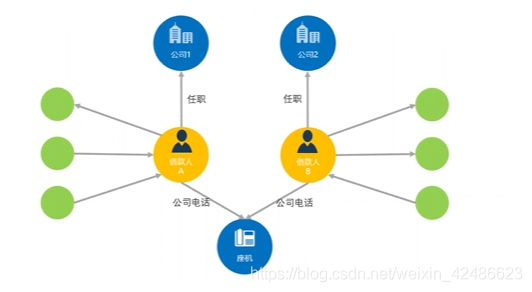
 反欺诈:不一致性验证可以用来判断一个借款人的欺诈风险,类似交叉验证。比如借款人A和借款人B填写的是同一个公司电话,但借款人A填写的公司和借款入B填写的公司完全不一样,这就成了一个风险点,需要审核人员格外的注意。
反欺诈:不一致性验证可以用来判断一个借款人的欺诈风险,类似交叉验证。比如借款人A和借款人B填写的是同一个公司电话,但借款人A填写的公司和借款入B填写的公司完全不一样,这就成了一个风险点,需要审核人员格外的注意。
参考
东南大学知识图谱课程
深蓝课程