pandas如何保存在excel里面_Python之Pandas使用系列(八):读写Excel文件的各种技巧

介绍:
我们将学习如何使用Python操作Excel文件。我们将概述如何使用Pandas加载xlsx文件以及将电子表格写入Excel。
如何将Excel文件读取到Pandas DataFrame:
和前面的章节一样,在使用Pandas时,我们必须从导入模块开始:
import pandas as pd使用read_excel的最简单方法是将文件名作为字符串传递。如果我们不传递任何其他参数(例如工作表名称),它将读取索引中的第一张sheet。在第一个示例中,我们将不使用任何参数:

在这里,Pandas的read_excel方法将数据从Excel文件读取到Pandas DataFrame对象中。然后,我们将此 DataFrame存储到名为df的变量中。
默认情况下,当使用read_excel时,Pandas将为 DataFrame分配一个数字索引或行标签,并且当int出现在Python中时,Pandas通常会从零开始。
例如,如果您的数据没有包含唯一值的列,则可以用作更好的索引。如果有一列可以用作更好的索引,我们可以覆盖默认行为。
可以通过将index_col参数来创建一个索引。
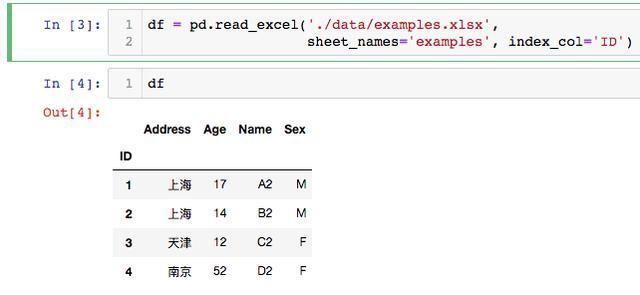
使用read_excel读取特定列
使用Pandas read_excel时,我们将自动从Excel文件中获取所有列。如果由于某种原因我们不想解析Excel文件中的所有列,则可以使用参数 usecols。假设我们只想创建一个具有ID, Address, Name列的 DataFrame 。我们可以如下文成:
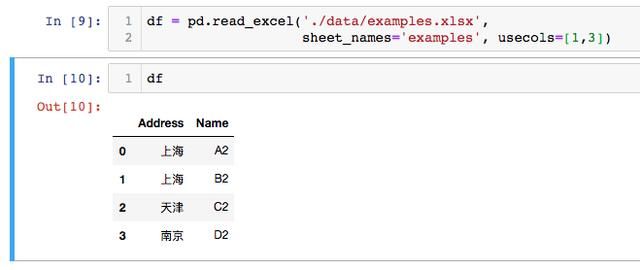
根据read_excel文档,我们应该可以放入一个字符串。例如,cols =‘Address:Name‘应该给我们与上面相同的结果。
读取Excel文件时如何跳过行
现在,我们将学习在使用Pandas加载Excel文件时如何跳过行。读取的excel示例如下:
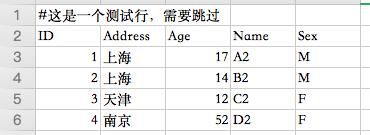
在下面的Pandas read_excel示例中,我们加载工作表" examples",其中包含我们需要跳过的行。
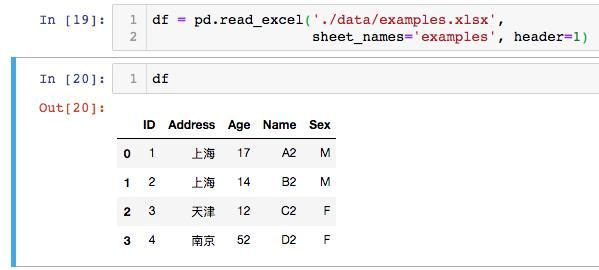
我们将使用参数sheet_name =' examples'读取名为' examples''的工作表。请注意,如果我们不使用sheet_name参数,则会读取第一张sheet。在此示例中,重要的部分是参数 skiprow = 2。我们使用它跳过前两行:
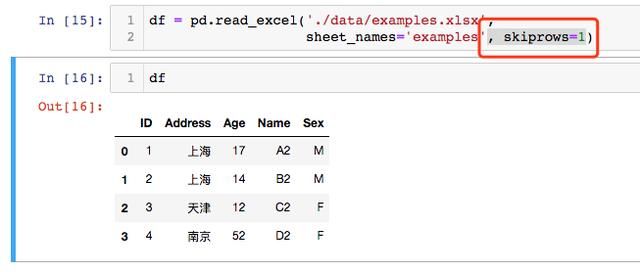
我们可以使用header 参数获得与上述相同的结果 。将使用参数 header = 1告诉Pandas read_excel我们的标题在第二行。
将多个Excel工作表读取到Pandas DataFrame
在Pandas read_excel中,我们将学习如何阅读多个sheets。我们的Excel文件example_sheets1.xlsx'具有两张表:" Sheet1"和" Sheet2"。我们将读入" Sheet1"和" Sheet2"这两个sheet:
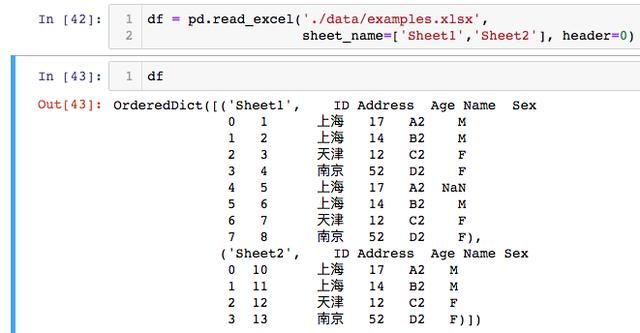
或者可以将参数sheet_name设置为 None。
合并Dataframe
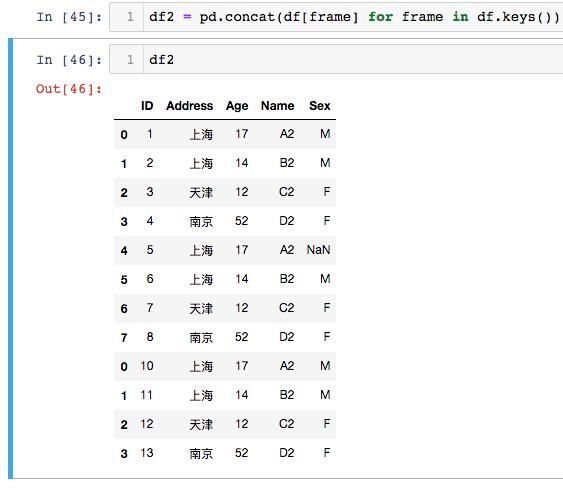
使用Pandas read_excel时,可能希望合并所有工作表中的数据。合并DataFrame非常容易。我们只使用concat函数并遍历工作表:
读取许多Excel文件
在某些情况下,我们可能有很多Excel文件包含来自不同实验的数据。在Python中,我们可以使用模块os和fnmatch来读取目录中的所有文件。最后,我们使用列表推导对找到的所有文件使用read_excel:
import os, fnmatchxlsx_files = fnmatch.filter(os.listdir('.'), '*concat*.xlsx')dfs = [pd.read_excel(xlsx_file) for xlsx_file in xlsx_files]如果没有问题,我们可以再次使用concat函数合并 DataFrame:
df = pd.concat(dfs, sort=False)还有其他方法可以读取许多Excel文件并将其合并。例如,我们可以将模块glob与Pandas concat一起使用以读取多个xlss文件:
import globlist_of_xlsx = glob.glob('./*concat*.xlsx') df = pd.concat(list_of_xlsx)设置数据或列的数据类型
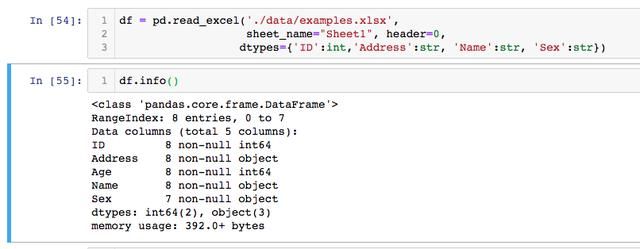
如果愿意,我们还可以设置列的数据类型。让我们使用Pandas再次读取examples.xlsx。在read_excel例子下面我们使用ID型参数来设置的某些列的数据类型。
将DataFrame写入Excel
当然,可以使用Pandas模块在Python中创建Excel文件。我们将首先创建一个带有一些变量的 DataFrame,但首先,我们将导入Pandas模块:
import pandas as pd下一步是创建 DataFrame。我们将使用字典创建 DataFrame。键将是列名,值将是包含我们的数据的列表:
df = pd. DataFrame({'Names':['Andreas', 'George', 'Steve', 'Sarah', 'Joanna', 'Hanna'], 'Age':[21, 22, 20, 19, 18, 23]})然后,我们使用" to_excel "方法将 DataFrame写入Excel文件。在下面的Pandas to_excel示例中,我们不使用任何参数。
df.to_excel(output.xlsx')如果不使用参数 sheet_name,则将 获得默认的工作表名称" Sheet1"。我们还可以看到我们在Excel文件中获得了一个包含数字的新列。这些是 DataFrame的索引。
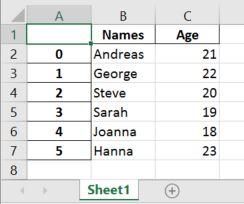
如果我们希望将工作表命名为其他名称,并且不希望索引列,则可以执行以下操作:
df.to_excel(output.xlsx', sheet_name='examples, index=False)将多个熊猫 DataFrame写入Excel文件:
如果碰巧有很多 DataFrame要存储在一个Excel文件中,但要存储在不同的工作表中,则可以轻松地做到这一点。但是,我们现在需要使用ExcelWriter:
df1 = pd. DataFrame({'Names': ['Andreas', 'George', 'Steve', 'Sarah', 'Joanna', 'Hanna'], 'Age':[21, 22, 20, 19, 18, 23]})df2 = pd. DataFrame({'Names': ['Pete', 'Jordan', 'Gustaf', 'Sophie', 'Sally', 'Simone'], 'Age':[22, 21, 19, 19, 29, 21]})df3 = pd. DataFrame({'Names': ['Ulrich', 'Donald', 'Jon', 'Jessica', 'Elisabeth', 'Diana'], 'Age':[21, 21, 20, 19, 19, 22]})dfs = {'Group1':df1, 'Group2':df2, 'Group3':df3}writer = pd.ExcelWriter('NamesAndAges.xlsx', engine='xlsxwriter')for sheet_name in dfs.keys(): dfs[sheet_name].to_excel(writer, sheet_name=sheet_name, index=False) writer.save()在上面的代码中,我们创建了3个 DataFrame,然后将它们放入Dict中。注意,key是sheet名称,单元格名称是 DataFrame。完成此操作后,我们使用xlsxwriter创建writer对象。然后,我们继续遍历键(即工作表名称)并添加每个工作表。最后,文件被保存。
总结:
当然,还有其他存储数据的方法。其中之一是使用JSON文件。后面我们会继续介绍如何使用Pandas读取和写入JSON文件。
点击关注,如果发现任何不正确的地方,或者想分享有关上述主题的更多信息,欢迎反馈。