《C++ Primer Plus》学习笔记 — C++11
《C++ Primer Plus》学习笔记 — C++11
- 一、扩展前面学过的C++11
-
- 1、初始化列表
- 2、类内成员初始化
- 3、foreach
- 4、右值引用
- 5、delete
- 二、移动语义和右值引用
-
- 1、移动语义
- 2、移动构造函数使用及注意事项
- 3、强制移动
- 三、Lambda函数
-
- 1、语法
- 2、为何选择 Lambda 表达式
- 四、function 包装器
-
- 1、函数模板带来的代码膨胀
- 2、基于function 包装器的解决方案
- 五、可变参数
-
- 1、可变参数函数
- 2、可变参数模板
- 六、tuple
-
- 1、make_tuple 和 std::get
- 2、std::tie 和 std::ignore
- 3、结构绑定
- 七、其他特性
-
- 1、正则表达式
- 2、随机数库
- 3、alignof 和 alignas
一、扩展前面学过的C++11
1、初始化列表
C++11中支持使用初始化列表初始化各种变量。除此之外,该标准中也支持使用模板类std::initializer_list作为构造函数参数。这种做法只支持同类型元素或者可转换为同类型元素的初始化:
#include & list)" << endl;
if (iList.size() < 2)
{
cout << "too few arguments" << endl;
}
auto iter = iList.begin();
m_iX = *iter++;
m_iY = *iter++;
}
};
int main(int argc, char* argv[])
{
CLS_Test test1 = { 1 , 2 };
}
![]()
这里注意构造函数中不能传递initializer_list的左值引用,因为这里的参数并非左值。那样定义将会导致调用第一个构造函数。
2、类内成员初始化
现在我们可以在声明类时对类内的变量初始化。当然,空间的分配还是发生在实例化过程:
class CLS_Test
{
private:
int m_iX = 5;
int m_iY = 10;
};
查看其汇编,我们可以知道编译器在构造函数中增加了初始化代码。这也就表示编译器同样会替我们在用户定义的构造函数前加上相应代码。
00901074 mov dword ptr [this],ecx
00901077 mov eax,dword ptr [this]
0090107A mov dword ptr [eax],5
00901080 mov ecx,dword ptr [this]
00901083 mov dword ptr [ecx+4],0Ah
0090108A mov eax,dword ptr [this]
3、foreach
我们可以使用基于范围的for循环遍历数组及STL容器。我们需要注意如果想修改数值,需要设置循环变量为引用。
#include 
4、右值引用
右值引用可以用来关联到右值,即可出现在赋值表达式左侧,但不能对其应用地址运算符的值。然而,如果我们将右值关联到右值引用上,则可以对其进行取址操作。
#include 这种操作本身没有什么作用,其主要作用还是和移动语义的配合使用。
5、delete
delete是C++11引入的用于禁用某个函数的关键字。其工作方式为:函数被声明,因此在查找符号时可以找到;然而它们却是被删除的,因此尝试寻找定义时会报错。
二、移动语义和右值引用
1、移动语义
什么是移动语义?如果我们在某个函数中构建了一个vector,并将其返回。那么函数中的vector就是一个临时变量。默认情况下,当我们将vector赋值给另一个变量时,调用的是复制构造函数。此过程执行的是深拷贝。然而,针对上面提到的临时vector。我们无须执行深拷贝,我们只需将临时vector的数据指针赋值给返回值变量的数据指针,并将原指针置空即可。对比计算机中链接文件:链接文件本身并不存储数据,而是存储指向数据的指针。因此我们对链接文件进行剪切时只需拷贝其指向数据的指针而不需要把真正的文件进行剪切和移动。
为了实现移动语义,我们需要得到针对拷贝语义和移动语义的不同构造函数:
vector(const vector& _Right) : _Mybase(_Right) {}
vector(vector&& _Right) noexcept(is_nothrow_move_constructible_v<_Mybase>) // strengthened
: _Mybase(_STD move(_Right)) {
this->_Swap_proxy_and_iterators(_Right);
}
我们需要注意,以vector为例,在其析构时,可能会释放数据指针所存储的数据。因此我们在移动时有可能需要修改右值引用数据的值。所以我们没有使用const:
vector(const vector&& _Right)
2、移动构造函数使用及注意事项
#include 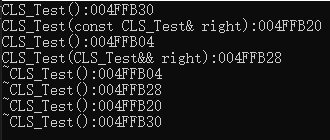
正如书中所说,如果把这段代码放到 g++ 中编译(我本地的版本为11.1.0)。结果却不太一样:
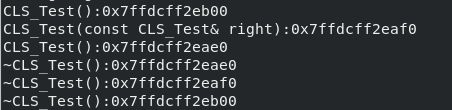
这或许是更进一步的 NRV 把。这也告诉我们,有时编译器的优化会让你的一些准备工作无法执行。
除此之外,适用于移动构造函数的规则也基本都适用于移动赋值操作符。
3、强制移动
有的时候我们创建了一个数组,只是为了从其中进行数据筛选,而后该数组便将被丢弃。
CLS_Test test[10];
CLS_Test best;
// pick
...
best = test[pick];
然而编译器并不知道这里可以直接进行移动,而是会调用拷贝构造函数。因此我们需要强制移动的功能。这可以通过强制类型转换实现,例如static_cast
best = std::move(test[pick]);
注意,这种方法并不会导致被移动的对象析构,其析构仍发生在生命周期结束时。同时,如果我们没有针对没有定义移动构造函数的对象调用此方法,将会导致调用复制构造函数;如果连复制构造函数都没有,那就报错。
三、Lambda函数
1、语法
Lambda表达使得语法为:[作用域内变量或引用] (参数及声明) -> 返回值类型 {方法体}。当方法体完全由一句返回语句组成时,表达式可以推断返回值类型,因此可省略(前面我们写的一些Lambda表达式正利用了这种功能)。
2、为何选择 Lambda 表达式
这里主要是和函数符以及普通函数作比较:
(1)距离 相比普通函数,Lambda表达式定义和调用的地方更为接近。在拷贝和修改代码时更为方便和直观;
(2)简介 相比函数符,Lambda表达式更为简洁;
(3)效率 相比函数调用,Lambda表达式一般为内联调用;
(4)功能 Lambda表达式有更多样的功能用于访问声明表达式作用内的变量。
#include 特别地,我们使用 [=] 表示按值访问所有变量,[&] 表示按引用访问所有变量。同时,我们可以使用逗号分开不同的变量类型,如 [=, &count] 表示按值访问所有变量,按引用访问 count 变量;[&, count] 表示按引用访问所有变量,按值访问 count 变量。
四、function 包装器
C++提供了很多的包装器(适配器),例如我们前面提到的bind1st、bind2nd,我们这里来看一个有趣的包装器function。
1、函数模板带来的代码膨胀
前面我们学习了很多能够与 () 操作符相结合的类型,如函数、函数指针、函数符、Lambda表达式。一方面,我们的选择变的更加灵活;同时,这也带来了一些问题。
#include 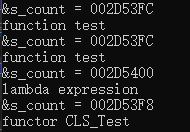
虽然从程序员的角度来看,这些调用应该都实例化相同的函数模板。然而事实上模板函数被实例化了3次。因为编译器并不认为它们的模板参数类型一样。
2、基于function 包装器的解决方案
function包装器正是用于解决这种问题的。这是一个模板类,定义在头文件functional中。该模板类的实例化对应于一种函数特征标,相同特征标(包括返回值)的模板只会被实例化一次。因此我们可以这样修改代码:
testFunc(function<void(void)>(test));
testFunc(function<void(void)>(pfTest));
testFunc(function<void(void)>([]()->void {cout << "lambda expression" << endl; }));
testFunc(function<void(void)>(CLS_Test()));
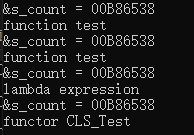
除此之外,书中提出我们可以修改函数的定义:
template<typename T>
void testFunc(function<T()> f)
{
static int s_count = 0;
cout << "&s_count = " << &s_count << endl;
return f();
}
...
testFunc<void>(test);
testFunc<void>(pfTest);
testFunc<void>([]() {cout << "lambda expression" << endl; });
testFunc<void>(CLS_Test());
与书中的例子对比,这里如果我们使用void类型,我们需要注意函数模板不能声明为:
template<typename T>
void testFunc(function<T(T)> f)
因为void类型不能作为函数的参数。相关的解释可以参考std::function
五、可变参数
C++中支持使用 … 设置可变参数和可变参数模板。
1、可变参数函数
这里我们直接使用C++手册中的例子,这是一个简单版本的printf:
#include va_list是可变参数的列表。我们使用va_start初始化可变参数列表,通过va_arg获得不同类型的参数(取出下一个并在可能的情况下转换为目标类型),va_end用于清理资源。
2、可变参数模板
其声明类似可变参数函数:
template<typename... Args>
void test(Args... args)
{
}
这里Args被称为模板参数包,args被称为函数参数包。可变参数模板可以使用递归来进行参数包展开:
#include 
这里空参的test函数作为递归基。同时我们注意递归调用时参数传递的方式为args… 而非args。用这种方式同样可以实现类似上面printf的功能。
六、tuple
tuple是C++11新增的数据类型。C++手册中写到其是pair类型的泛化使用,即一种泛化的任意类型的数据集合。
1、make_tuple 和 std::get
make_tuple用于元组构建,其模板函数声明使用了我们前面学到的可变模板。
std::get是以元组为参数的模板函数,其作用是根据指定index返回数据。C++14中新增了根据指定数据类型返回数据的功能(如果有重复类型的数据,将无法编译通过)。
#include (t) << ", " << get(t) << ", " << get(t) << ")" << endl;
auto tupleWithoutDupType = make_tuple(1, "testStr", 3.14);
cout << "(" << get<int>(tupleWithoutDupType) << ", " << get<const char*>(tupleWithoutDupType) << ", " << get<double>(tupleWithoutDupType) << ")" << endl;
}
![]()
2、std::tie 和 std::ignore
std::tie用于返回其参数左值引用所对应的元组。
std::ignore用于表示一个类似空元组的功能。这种方式可以让我们给多个数据返回值赋值。
#include ![]()
3、结构绑定
C++17中新增了结构绑定功能用于将不同的变量绑定为元组的不同值。
#include ![]()
七、其他特性
1、正则表达式
C++11中引入了正则表达式的功能。正则表达式是一种用于字符串模式匹配的表达式。相关的功能定义在regex头文件中。
2、随机数库
C++中原本使用引入自C的rand函数来计算随机数。C++11中引入了新的随机数库,位于头文件random中。该头文件中定义了许多不同的随机数生成器以及用于生成均匀分布、二项分布和正态分布等多种分布状态的引擎。
3、alignof 和 alignas
alignof用于获取机器对于不同类型数据的对其要求。
alignas用于控制对齐方式。
直接上手册上的示例:
#include 