Delta Lake调研:Delta Lake是什么【2】Lakehouse和data warehouse、data lake的区别

Delta Lake是一个基于云对象存储的表存储工具,它实现了lakehouse的构想。Delta Lake可以解决工业领域数据产生,获取,分析等涵盖企业数据分析场景下,数据生命周期内的所有问题,因而有着广阔的使用前景。
在之前的博客Delta Lake调研:Delta Lake是什么
中介绍了Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores中对于Delta Lake工具的介绍。Delta Lake部分实现了Lakehouse构想。本篇博客将对比Lakehouse和data warehouse以及data lake的区别进一步介绍Delta Lake。通过对比Lakehouse和二者的关系,可以了解Delta Lake有什么优势。
目录
- Data Warehouse
-
- Data Warehouse的四层结构
- Data Lake
- Lakehouse
- 对比DataBase和DataWarehouse
-
- 图书馆例子
- 对比DataWarehouse和DataLake
-
- 例子
- 参考材料
Data Warehouse
数据仓库的提出晚于大部分人所熟知的数据库,它同样是数据存储的地方。只不过与数据库面向业务的特性相比,数据仓库存储的数据面向比业务更粗粒度的主题,处理的任务偏向数据分析而并非数据操作。解决问题不同是数据库与数据仓库之间最大的区别。
例如当用户登陆淘宝时,用户输入的用户账号和密码会与后台数据库存储的数据进行比对,当结果匹配时,则用户可以正常登录淘宝,否则就不能。这里举的例子就是数据库的经典使用场景。数据库大多针对OLTP提出。
数据仓库的使用者大多是分析数据的BI users,多用于对大量数据进行数据分析这是与数据库的一个重要区别。
数据仓库的数据分四层存储,分别是ODS层(Operational Data Store),PDW层(Personal Data Warehouse),DM层(Data Marts)和APP层(Application)。其中ODS层负责存储未经处理的原始数据
Data Warehouse的四层结构
ODS
ODS层存储细节数据,是datawarehouse中最接近数据源的一层。数据源中的数据经过ETL操作(Extract抽取、Transform转换、Load加载)后进入本层。ODS层的数据是定义统一的,可以体现历史的,被长期保存的。这一层的数据一般不做过多去躁处理,且数据的分类多基于业务逻辑。
PDW
PDW层是基础指标层,经过初步处理生成的ODS层数据在PDW层进行主题汇总。这一层同时创建各个主题包含哪些属性。
PDW中的数据需要定期进行质量审核,保证权威准确;DW中的数据只允许增加,不允许删除和修改。这一层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了清洗(去除了杂质)后的数据。这一层的数据一般是遵循数据库第三范式的,其数据粒度通常和ODS的粒度相同。在PDW层会保存BI系统中所有的历史数据,例如保存10年的数据。
DM
DM层以某个业务应用为出发点而建设的局部PDW。DM只关心自己需要的数据,不会全量考虑企业整体数据架构和应用,每个应用有自己的DM。 数据集市就是满足特定的部门或者用户的需求,按照多维的方式
进行存储,包括定义维度、需要计算的指标、维度的层次等,生成面向决策分析需求的数据立方体(data cube)。
这层数据是面向主题来组织数据的,通常是星形或雪花结构的数据。从数据粒度来说,这层的数据是轻度汇总级的数据,已经不存在明细数据了。从数据的时间跨度来说,通常是 DW 层的一部分,主要的目的是为
了满足用户分析的需求,而从分析的角度来说,用户通常只需要分析近几年(如近三年的数据)的即可。
从数据的广度来说,仍然覆盖了所有业务数据。一个星型结构包含两个基本部分:一个事实表和各种支持维表。
APP
APP层直接面对数据分析者,因而需要着一层的数据是干净且高度结构化的。这一层的数据最终可以导入到数据库中以备分析使用。
Data Lake
数据湖与数据仓库不同,它可以存储来自业务线应用的关系数据以及来自移动应用程序、loT设备和社交媒体的非关系数据。数据湖可以存储的数据种类相较于数据仓库会更为丰富。在向数据湖存入数据时,无需定义数据结构和数据模式,因而也无需对未来用这份数据处理什么问题有着明确了解。
数据湖事实上很多地方与数据仓库较为相近,不同的是数据湖比数据仓库拥有更高的灵活性,数据仓库的数据存入PDW层需要预先确定数据存储的模式(Schema)但是在数据湖这里,数据存入数据湖并不需要预先知道要解决的问题是什么,因而也无需确定模式。而当用户遇到具体问题时,可以按照需要将原始数据转成需要的形式。
数据湖的出现也是为了解决数据仓库的一些问题,诸如数据存储成本高等。数据湖提供了廉价的存储系统,并且自带文件API,其数据存储通常以开放的文件格式保存,例如Parquet和ORC格式。数据湖的灵活带来的问题是很难保证数据的质量,并且在数据湖中治理数据一直是数据湖使用时所面临的挑战。数据湖中只有一小部分数据会经过ETL过程运送到下游的数据仓库中供研究人员进一步数据分析。
最初实践数据湖构想的工具是Apache Hadoop movement,它使用了Hadoop File System(HDFS)用于存储。
正如上一篇博客Delta Lake调研:Delta Lake是什么提到的那样,云对象存储是未来数据存储方式的趋势,越来越多的公司倾向于将数据存在云上并将数据存储与计算的开销分开以减小成本。在数据湖产生之后,很多企业开始将数据先存入数据湖中,再将数据湖中的部分有价值数据处理后放入数据仓库之中。这种架构被称为两层数据湖+仓库架构(two-tier data lake+warehouse architecture)。
但是这种两层架构并非没有缺点。首先,数据先进入数据湖再进入数据仓库的复杂流程使得数据的分析变得更加复杂困难。其次,现代企业开始在它们的数据中使用机器学习技术,但无论是数据湖还是数据仓库都不支持机器学习。最后,数据在两层构架中无法保证数据的质量和实时性。
基于以上提到的两层架构的问题,databrick公司提出Lakehouse设想,并在Delta Lake, Delta Engine和Databricks ML flow。
Lakehouse

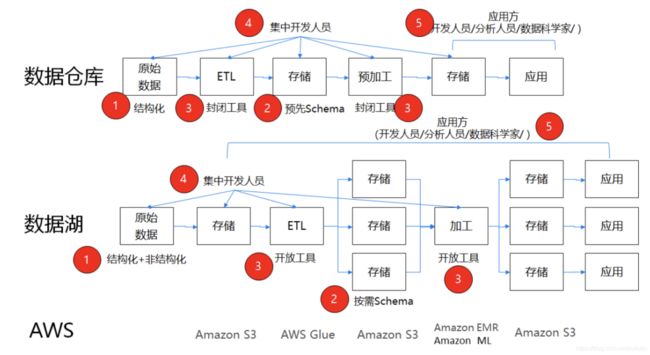
这张图介绍了Lakehouse与数据仓库,数据湖之间的关系。图(a)代表的是只使用数据仓库的数据处理流程,结构化数据经过ETL处理进入数据仓库,用户从数据仓库中获取数据进行数据分析。图(b)展示的是两层数据架构下数据的流动关系,原始数据包括结构化数据和非结构化数据进入数据湖,数据湖中的数据经过ETL操作进入数据仓库,一些用户直接从数据湖中获取数据,而另外一些用户从数据仓库中获取数据。图©展示的是Lakehouse下数据的流动关系,Lakehouse结合了数据仓库和数据湖的特性,既提供数据湖数据全面的特性,又提供数据仓库数据高管理数据性能佳的特性。

这张图总结了DataWarehouse、Data Lake、Delta Lake的区别。
对比DataBase和DataWarehouse
先看这张表格,对比了DataBase和DataWarehouse的主要区别(此图来自众多博客,是众多博客内容的总结)。

由于数据库和数据仓库本不是为了同一个目的形成的数据存储工具,二者因而也不用与同样的领域。下面举一个具体的例子来分析,以图书馆业务为例。
图书馆例子
图书馆的运营中会维护多张表,有书籍列表,表中属性为书名,书id,书的作者,出版社等等;有读者列表,其属性为读者名,读者ID,读者其他信息等;有借书表,借书表中记录谁借了哪本书。
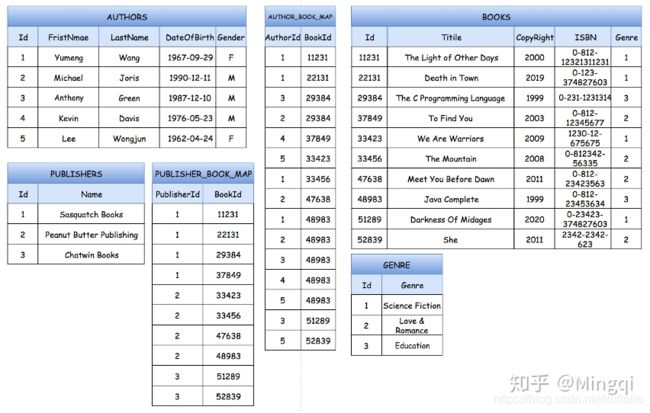
如果图书馆决定就图书借阅业务进行数据分析,并考虑使用数据仓库来进行分析,那么构建数据仓库的第一步就是先根据分析问题构建统一schema并使用denomalize从数据库中一个一个数据表生成一个大数据表。


在数据库使用环境中,用户使用api对业务中产生的数据进行读写,而在数据仓库使用环境中,用户对数据的处理则更为复杂。用户将每24个小时从数据库中抽取数据,经过denormalize形成大表存入数据仓库。
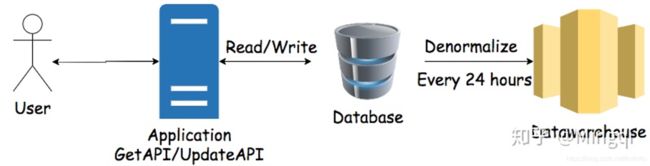
以下三个例子可以帮助大家理解数据库和数据仓库的区别:
- 想要知道一个人的身体情况,需要考虑的情况包括:身高,体重,心率,血压,血糖,视力,听力等等一系列指标的结构,但这些指标分别来自不同的检测方式(业务),这时需要使用数据仓库来集合这些业务的数据(数据库中获取),从而得到更全面的关于人体健康的分析结论。
- 想要做一道菜,需要获取多种食材。当用户想要吃鱼时,需要首先获取一条鱼,在决定了烹饪手法(红烧or清蒸)后选择相应的配料(豆豉,葱,姜等),获取全部食材后同时需要先将食材进行初步清洗(去鱼鳞,去内脏,切碎葱姜等),然后需要进行合适的烹饪手法,最后才能得到一道菜。从数据库中只能得到每个食材,得不到一道经过烹饪的菜,只有数据仓库才能完成这一步。
- 消费者在淘宝上买东西,只需要数据库即可,淘宝分析一年的销售情况则需要使用数据仓库,因为分析的数据来自不同的数据库。
对比DataWarehouse和DataLake
再看这个表格,DataWarehouse发展到一定程度时,其不灵活的弊端逐渐显露出来,因而产生了DataLake这种管理数据的模式,与DataWarehouse相比,DataLake的数据管理更为灵活,不需要在创建DataLake之前对问题有十分清晰的认识。

例子
对之前对比DataBase和DataWarehouse时举的例子进行拓展:
- 并不知道未来需要看某个人的身体状况,定期收集这个人的身体检测指标,突然某一天这个人生病了,再从收集的数据中提取生病原因。
- 并不知道未来需要做鱼,但养了一池子鱼,院子里也种了大葱和姜,突然某一天想吃鱼,就从院子里收集素材做鱼。
在上述两个例子中,数据并非是为了什么目的而收集的,只是定期收集,汇总在数据湖中,以保证问题出现时数据湖中有数据可用。
Delat Lake调研总篇
参考材料
- 「博客」数据仓库的概念
- 「知乎帖子」数据库与数据仓库的本质区别是什么
- 「博客」Data Warehouse 简介
- 「博客」浅析数据库(DB)、操作数据存储(ODS)和数据仓库(DW)的区别与联系
- 「博客」数据湖和数据仓库的区别是什么
- 「博客」数据湖(Data Lake)总结
- 「博客」有了数据湖,距离数据仓库消失还有几年?
- 「论文」Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics
- 「博客」【实践案例】Databricks 数据洞察 Delta Lake 在基智科技(STEPONE)的应用实践