融合正余弦和柯西变异的麻雀搜索算法-附代码
融合正余弦和柯西变异的麻雀搜索算法
文章目录
- 融合正余弦和柯西变异的麻雀搜索算法
-
- 1.麻雀搜索算法
- 2.改进麻雀算法
-
- 2.1 折射反向学习策略
- 2.2 正余弦策略
- 2.3 柯西变异策略
- 3.实验结果
- 4.参考文献
- 5.Matlab代码
- 6.python代码
摘要:针对麻雀搜索算法(SSA)在寻优后期出现能力不足、种群多样性损失、易落进局部极值现象,造成SSA算法收敛速度慢、探索能力不足等问题,提出了融合正余弦和柯西变异的麻雀搜索算法(SCSSA)。首先借助折射反向学习机制初始化种群,增加物种多样性;然后在发现者位置更新中引入正余弦策略以及非线性递减搜索因子和权重因子协调算法的全局和局部寻优能力;最后在跟随者位置中引入柯西变异对最优解进行扰动更新,提高算法获取全局最优解能力。
1.麻雀搜索算法
基础麻雀算法的具体原理参考,我的博客:https://blog.csdn.net/u011835903/article/details/108830958
2.改进麻雀算法
2.1 折射反向学习策略
针对 SSA 算法在寻优后期出现群体多样 性损失, 造成落人局部极值的几率升高, 引 发收敛精度不足问题,本文采用一种折射反 向学习机制对麻隹种群初始化。反向学习是 Tizhoosh 提出的一种优化策略 [ 9 ] { }^{[9]} [9], 基本思想是 通过计算当前解的反向解来扩大搜索范围, 借此找出给定问题更好的备选解。文献[1011]将智能算法与反向学习的结合, 均能有效 提高算法求解精度。同时反向学习仍存在一 定的不足, 在寻优早期引进反向学习能加强 算法的收敛性能, 但在后期易使算法陷人早 熟收敛。因此在反向学习策略中引进一种折 射原理 [ 12 ] { }^{[12]} [12] 以降低算法在搜索后期陷人早熟收 敛的几率。折射反向学习原理如图 1所示。

其中, x x x 轴上面解的寻优范围为 [ , u ] , y [, u], y [,u],y 轴为法线, α 、 β \alpha 、 \beta α、β 分别表示人射角、折射角, h h h 和 h ∗ h^* h∗ 分别为入射、折射光线所对应的长度, O O O 为寻优范围 [ , u ] [, u] [,u] 的中点。根据数学中线几何 关系, 得到如下:
sin α = ( ( l + u ) / 2 − x ) / h sin β = ( x ∗ − ( l + u ) / 2 ) / h ∗ (4) \begin{aligned} &\sin \alpha=((l+u) / 2-x) / h \\ &\sin \beta=\left(x^*-(l+u) / 2\right) / h^* \end{aligned}\tag{4} sinα=((l+u)/2−x)/hsinβ=(x∗−(l+u)/2)/h∗(4)
根据折射率定义 n = sin α / sin β n=\sin \alpha / \sin \beta n=sinα/sinβ, 得到折 射率 n n n 公式为:
n = h ∗ ( ( l + u ) / 2 − x ) h ( x ∗ − ( l + u ) / 2 ) (5) n=\frac{h^*((l+u) / 2-x)}{h\left(x^*-(l+u) / 2\right)} \text { (5) } n=h(x∗−(l+u)/2)h∗((l+u)/2−x) (5)
令缩放因子 k = h / h ∗ k=h / h^* k=h/h∗, 带人式(5)得到 变形公式为:
x ∗ = l + u 2 + l + u 2 k n − x k n (6) x^*=\frac{l+u}{2}+\frac{l+u}{2 k n}-\frac{x}{k n} \text { (6) } x∗=2l+u+2knl+u−knx (6)
当 n = 1 n=1 n=1 且 k = 1 k=1 k=1 时, 式 ( 6 ) 可转为反 向学习公式 [ 11 ] { }^{[11]} [11] :
x ∗ = l + u − x (7) x^*=l+u-x \text { (7) } x∗=l+u−x (7)
式 (6) 推广到麻雀算法高维空间时, 令 n = 1 n=1 n=1 可得到如下:
x i , j ∗ = l j + u j 2 + l j + u j 2 k − x i , j k ( 8) x_{i, j}^*=\frac{l_j+u_j}{2}+\frac{l_j+u_j}{2 k}-\frac{x_{i, j}}{k} \text { ( 8) } xi,j∗=2lj+uj+2klj+uj−kxi,j ( 8)
式中: x i , j x_{i, j} xi,j 为种群中第 i i i 只麻雀在 j j j 维位置 ( i = 1 , 2 , … , D ; j = 1 , 2 , … , N ) , D (i=1,2, \ldots, D ; j=1,2, \ldots, N), D (i=1,2,…,D;j=1,2,…,N),D 为种群数, N N N 为维度; x i , j ∗ x_{i, j}^* xi,j∗ 为 x i , j x_{i, j} xi,j 的折射反向位置; l j l_j lj 、
u j u_j uj 分别为搜索空间第 j j j 维的最小值和最大值。
算法 1 初始化种群算法
(1)在寻优范围中随机初始化 N N N 个麻雀 位置 x i , j x_{i, j} xi,j 作为初始种群位置;
(2)根据式(8)生成折射反向种群 x i , j ∗ x_{i, j}^* xi,j∗;
(3) 合并初始种群和折射反向种群, 根 据适应度值的升降进行排序, 选取适应度值 前 N N N 个麻雀个体作为初始种群。
2.2 正余弦策略
在麻雀捕食过程中, 食物源位置非常重 要作用, 影响整个麻雀种群前进方向。但考 虑到食物来源可能不同, 位置也不尽相同, 当发现者搜寻的食物位于局部最优时,大量 的跟随者会涌人到该位置,此时发现者与整 个群体停滞不前, 造成种群位置多样性出现 损失, 进而增加陷人局部极值的可能性。针 对该现象,本文在麻雀搜索算法发现者的位 置. 更新中引进正余弦算法 ( SineCosineAlgorithm,SCA ) [ 13 ] { }^{[13]} [13] ,通过利用正余弦 模型震荡变化特性对发现者位置进行作用, 维持发现者个体多样性, 进而提高 S S A \mathrm{SSA} SSA 的全 局搜索能力。 S C A \mathrm{SCA} SCA 的中心思想是根据正余弦 模型的振荡变化对整体和局部寻优, 获取整 体最优值。
针对基本的正余弦算法的步长搜索因子 r 1 = a − a t / r_1=a-a t / r1=a−at/ Iter max ( a _{\max }(a max(a 为常数, t t t 为迭代次数, 本文设置 a = 1 a=1 a=1 )呈线性递减趋势, 不利于进 一步平衡 SSA 的全局搜索和局部开发能力,受文献[14]启发,对步长搜索因子进行改进,新的非线性递减搜索因子如式(9),在前期权重较大,递减速度慢,利于提高全局寻优能力,在权重因子较小时,增强算法在局部开发的优势,加快获取最优解的速度。
r 1 ′ = a × ( 1 − ( t Iter max ) η ) 1 / η ( 9 ) r_1^{\prime}=a \times\left(1-\left(\frac{t}{\text { Iter }_{\max }}\right)^\eta\right)^{1 / \eta}(9) r1′=a×(1−( Iter maxt)η)1/η(9)
式中: η \eta η 为调节系数, η ⩾ 1 ; a = 1 \eta \geqslant 1 ; a=1 η⩾1;a=1 。
考虑 S S A \mathrm{SSA} SSA 算法在整个抻索过程中, 种群 个体位真更新常受到当前位置影响。因此弓 进式(10)非线性权重因子心用于调整种群 个体位置更新对此时个体信自的依赖度。在 寻优前期, 较小的心降低了寻优个体位置更 新对当前解位置影吅, 提升了算法全居奇优 个体位真更新的高度依赖性, 加快了算法的 收敛速度, 变化曲线如图 2 所示。则得到新 的发现者位置更新公式如式 ( 10 ):
w = e t 1 t e max − 1 e − 1 ( 10 ) w=\frac{e^{\frac{t}{1 t e_{\max }}}-1}{e-1}(10) w=e−1e1temaxt−1(10)
X i , j t + 1 = { ω ⋅ X i , j t + r 1 ′ ⋅ sin ( r 2 ) ⋅ ∣ r 3 ⋅ X best − X i , j t ∣ R 2 < S T ω ⋅ X i , j t + r 1 ′ ⋅ cos ( r 2 ) ⋅ ∣ r 3 ⋅ X best − X i , j t ∣ R 2 ⩾ S T (11) X_{i, j}^{t+1}= \begin{cases}\omega \cdot X_{i, j}^t+r_1{ }^{\prime} \cdot \sin \left(r_2\right) \cdot\left|r_3 \cdot X_{\text {best }}-X_{i, j}^t\right| \quad R_2Xi,jt+1={ω⋅Xi,jt+r1′⋅sin(r2)⋅∣ ∣r3⋅Xbest −Xi,jt∣ ∣R2<STω⋅Xi,jt+r1′⋅cos(r2)⋅∣ ∣r3⋅Xbest −Xi,jt∣ ∣R2⩾ST(11)
式中: r 2 ∈ [ 0 , 2 π ] r_2 \in[0,2 \pi] r2∈[0,2π] 的随机数, 决定麻雀的移动距离 ; r 3 ∈ [ 0 , 2 π ] r_3 \in[0,2 \pi] r3∈[0,2π] 的随机数, 控制最优个 体对麻雀后一位置的影响。
2.3 柯西变异策略
在觅食过程中, 跟随者经常围绕最好的 发现者周围进行觅食, 其间也有可能发生食 物的争夺, 使其自已变成发现者, 为避免算 法陷人局部最优, 在跟随者更新公式中引人 柯西变异策略, 提升全局寻优能力。新的跟 随者位置更新如下:
X i , j t + 1 = X best ( t ) + cauchy ( 0 , 1 ) ⊕ X best ( t ) X_{i, j}^{t+1}=X_{\text {best }}(t)+\operatorname{cauchy}(0,1) \oplus X_{\text {best }}(t) Xi,jt+1=Xbest (t)+cauchy(0,1)⊕Xbest (t) ( 12 )
式中: cauchy ( 0 , 1 ) \operatorname{cauchy}(0,1) cauchy(0,1) 为标准柯西分布函数;
⊕ \oplus ⊕表示相乘含义。
以原点为中心的一维柯西变异函数如下: f ( x ) = 1 π ( 1 x 2 + 1 ) , − ∞ < x < ∞ f(x)=\frac{1}{\pi}\left(\frac{1}{x^2+1}\right),-\infty
SCSSA 算法流程
步骤 1 设置种群大小 N N N, 最大迭代次数 Iter r max r_{\max } rmax, 发现者比例 P D P D PD, 侦察者比例 S D S D SD, 警戒阈值 R 2 R_2 R2, 安全阈值 S T S T ST 等;
步骤 2 执行算法 1 对麻雀种群初始化;
步骤 3 计算每只麻﨎的适应度值并排序, 确定当前最优、最差适应度个体;
步骤 4 根据式(11)对发现者位置更新;
步骤 5 根据式 ( 12) 对跟随者位置更新;
步骤 6 根据式(3)对警戒者位置更新;
步骤 7 判断当前迭代次数是否达到结束条件, 若满足, 则进行下一步, 否则跳转步骤 3;
步骤 8 程序结束, 输出最优适应度值和最佳位置。
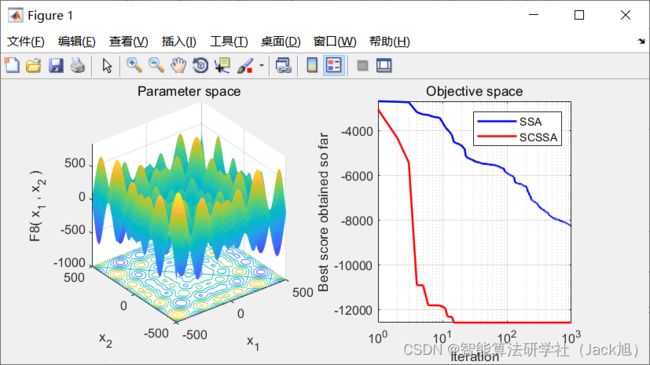
3.实验结果
4.参考文献
[1]李爱莲,全凌翔,崔桂梅,解韶峰.融合正余弦和柯西变异的麻雀搜索算法[J/OL].计算机工程与应用:1-11[2021-09-09].http://kns.cnki.net/kcms/detail/11.2127.TP.20210806.0937.008.html.