CTW数据集使用
笔者在使用CTW数据集进行街景文字检测与识别,为了让自己更好地理解,将使用过程记录下来,包含原作者的文档说明和笔者使用过程中遇到的问题及解决方案。笔者也是初学者,不保证完全正确,可能存在疏漏或者问题,欢迎批评指正。另文章未完,会继续更新。
目录
- 数据准备
-
- 文件内容介绍
- 下载图像和注释
- 数据分割
- 文字识别
-
- 分类网络框架
- 训练网络
-
- 数据训练前处理
- 运行train.py
- 端到端文字检测与识别
-
- 架构
-
- 训练步骤
-
- 编译Darknet并下载预训练模型
- 设置类别数目
- 裁剪图像生成meta 文件
数据准备
下载图像和注释数据链接: https://ctwdataset.github.io/.
git工程链接: https://github.com/yuantailing/ctw-baseline.
注意:所有代码运行环境要求尽量满足python>=3.4
下载git工程时,科学上网(挂梯子)会更快一些。
如果使用git命令下载git工程,需要先下载git并安装。参考链接: https://blog.csdn.net/Andone_hsx/article/details/87937329.
文件内容介绍

tutorial/: 教程,也是本文的参考来源
data/: 图像(images)和注释(annotations)数据,需要下载解压放到此文件夹中
prepare/: 准备数据集拆分
classification/: 使用tensorflow分类的baseline,也就是文字识别,将每个字看成一类,因此文字识别也是分类问题
detection/: 使用YOLOv2进行文字检测,这是一个端到端的文字检测和识别模型
judge/: 评估测试结果,并绘制结果和统计数据
pythonapi/: api用于遍历注释,评估结果,或用于通用用途
cppapi/: 更快地实现检测AP评估
codalab/: 在CodaLab(我们的评估服务器)上运行
ssd/: 使用SSD的检测方法
以上的大多数文件夹中都包含一下文件
/settings.py: 配置图像目录、注释的文件路径,以及每个步骤的专用配置
/products/: 存放临时文件、日志、中间结果、最终结果
/pythonapi: 一个指向pythonapi/的符号链接,以便更方便地使用Python API
大多数代码使用python语言,少量使用C++,Shell等。
我没有用过Shell,百度了一下:Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁。Shell 既是一种命令语言,又是一种程序设计语言。Shell 是指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问操作系统内核的服务。业界所说的 shell 通常都是指 shell 脚本,但读者朋友要知道,shell 和 shell script 是两个不同的概念。
所有的代码,应该在子文件夹下运行。
教程中所给运行代码示例,应该是在linux系统中运行,Windows的话,就打开cmd,先使用cd命令到文件所在的文件夹下,再使用“python3 文件名.py ”运行文件。
所有的代码不会在CTW根文件夹之外创建新的文件。
安装需求
- git>=1
- Python>=3.4
- Jupyter notebook>=5.0
- gcc>=5 安装教程链接: http://www.manongjc.com/article/23844.html.
- g++>=5
- CUDA driver
- CUDA toolkit>=8.0
- CUDNN>=6.0
- OpenCV>=3.0 我的版本是4.5.2
以下可直接使用“pip install 库名称”命令安装 - Jinja2
- matplotlib 我的版本是3.1.0
- opencv-python
- scikit-image
- scipy
- six
- tensorflow-gpu>=1.4.0rc0
硬件需求
RAM >= 32GB
GPU memory >= 12 GB
Hard Disk free space >= 200 GB
CPU logical cores >= 8
Network connection
我没有这么好的硬件,不知道能不能跑起来啊
下载图像和注释
下载图像和注释数据链接: https://ctwdataset.github.io/.
下载后
- 解压图像文件,放在$CTW_ROOT/data/all_images文件夹下,我下载的每一个压缩包解压都显示文件损坏,但还是有图像可以用的,暂时没管。
- 下载注释文件,解压放在$CTW_ROOT/data/annotations/downloads下。
- 为了测试和分析本地代码,可以使用验证集和测试集测试,运行/prepare/fake_testing_set.py。
运行报找不到pythonapi模型的错误,原因是没有将该目录设置为环境变量,解决方案:右键make_directory as–>sources path或sources root。 - 建文件夹TRAIN+VAL ( C T W R O O T / d a t a / i m a g e s / t r a i n v a l / ) T E S T ( CTW_ROOT/data/images/trainval/) TEST( CTWROOT/data/images/trainval/)TEST(CTW_ROOT/data/images/test/) set
数据分割
将数据分割成四部分:
-
训练集(75%)
数据格式:
每张图像包含若干个lines,每个lines包含若干个文字示例(character instances),每个文字示例包含:对应的文字,文字框,6个属性(遮挡属性、复杂背景属性、扭曲属性、凸起属性、艺术字属性和手写属性)。
需要注意,仅标注出了图像中的全部中文,非中文只有部分标注,因此只适用于中文检测和识别。 -
验证集(5%)
与训练集一样 -
文字识别测试集(10%)
这里的数据集中,图像和注释中的文字框是可用的,但是对应中文、属性是不可用的。
To evaluate your results on testing set, please visit our evaluation server. -
端到端文字检测与识别测试集(10%)
只有图像是可输入的数据。
文字识别
代码主要在classification文件夹下。
分类网络框架
原作者使用Tensorflow训练网络,笔者打算使用pytorch
对每个字:
1、裁剪
2、随意调整饱和度、亮度、对比度
3、随意仿射变换
4、标准化
5、输入大小调整
6、输入训练网络
训练网络
数据训练前处理
1、setting.py文件内可以修改最终结果的类型数据,当前1000的含义是我们只考虑最常见的1000个字符类别的识别。我们放弃承认其他类别,这必然导致这些类别的失败。
- 在import settings时,发现settings下标红色波浪线,原因是没有将该目录设置为环境变量,解决方案:右键make_directory as–>sources path或sources root。
2、decide_cates.py 对字出现的频率进行排序,并保存在products/cates.json。
3、create_pkl.py 对文字区域进行裁剪,并且有四边形框调整,保存在products/*.pkl
4、在这里报了许多错误,主要是因为我下载的数据集压缩包损坏,解压出来缺失了很多图片。
解决方案:在读取文件之前,加入一个判断文件是否存在的命令,load_train函数修改以后如下所示。
def load_train(i):
if i % 100 == 0:
print('trainval', i, '/', len(lines))
anno = json.loads(lines[i].strip())
image_path = Path(os.path.join(settings.TRAINVAL_IMAGE_DIR, anno['file_name']))
if image_path.exists():
image = imageio.imread(image_path)
assert image.shape == (anno['height'], anno['width'], 3)
for char in anno_tools.each_char(anno):
if not char['is_chinese']:
continue
cropped = crop(image, char['adjusted_bbox'])
train[i].append([cropped, char['text']])
load_test函数同样:
def load_test(i):
if i % 100 == 0:
print('test', i, '/', len(lines))
anno = json.loads(lines[i].strip())
image_path = Path(os.path.join(settings.TRAINVAL_IMAGE_DIR, anno['file_name']))
if image_path.exists():
image = misc.imread(image_path)
assert image.shape == (anno['height'], anno['width'], 3)
for char in anno['proposals']:
cropped = crop(image, char['adjusted_bbox'])
test[i].append([cropped, None])
运行train.py
1、文件中集成了多个网络模型,根据自己的需要,可以在classification/train.py中修改cfgs,笔者使用的是inception_v4,不用修改原程序,只需要在运行的时候指定模型名称就可以了。
2、脚本输出会存放在classification/products/下,并且会需要较长的时间。作者给出了时间参考:
Time cost estimation (NVIDIA GTX TITAN X):
alexnet_v2: 0.2 sec / step, 6 hours in total
resnet_v2_152: 1.2 sec / step, 33 hours in total
others: 1.0 sec / step, 28 hours in total
3、训练后可以查看/classification/products/train_logs_alexnet_v2/的训练日志,作者给出了查看代码:
tensorboard --logdir=../classification/products/train_logs_alexnet_v2/
4、作者给的一些建议
如果training step变得越来越慢(例如,> 2 sec / step),你可以按Ctrl+C来中断它,执行sudo sh -c "echo 3 >/proc/sys/vm/drop_caches"来删除缓存,然后重新运行train.py。它将自动从最近的检查点恢复训练。
我们每1200秒保存一次检查点,这个神奇的数字在classification/train.py中的cfg_common中的save_interval_secs中设置。不要将它与其他内存密集型应用程序一起运行。
如果你得到一个CUDNN_STATUS_BAD_PARAM错误,你可以在classification/train.py中关闭per_process_gpu_memory_fraction。
在培训resnet_v2_152时,tensorflow可能同时运行training step和summary step,导致run out of memory (OOM)。你可以在classification/train.py的cfgs中设置save_summaries_secs为无穷大(例如999999)来禁用总结步骤。
您可以从源代码更新TensorFlow-Slim,但请保留我们定制的修改slim/train_image_classifier.py和slim/eval_image_classifier.py。
5、我在运行的时候又又又又报错了
- 主程序第一行 “sys.argv[1]”报错,参考链接: https://www.cnblogs.com/aland-1415/p/6613449.html.
所以这个程序需要关掉在命令行中运行
!cd ../classification && python3 train.py inception_v4
事实上,我在运行的时候,需要把python3 改成python来运行,用python3没有反应。
-
然后又报了没有inception_v4模型
原作者提供了模型检查点文件的下载网站,我也下了inception_v4的检查点,但不知道怎么用,需要学习一下。
在nets文件夹中,作者提供了各网络的架构,只要从nets文件夹讲inception_v4 import进来即可。 -
又报了AssertionError,是断言错误,逐渐看不懂,于是分析一下整个代码,还是没能明白问题在哪。
-
module ‘tensorflow’ has no attribute ‘contrib’,参考链接: https://www.codenong.com/cs106147741/.
-
Could not load dynamic library ‘cudart64_110.dll’; dlerror: cudart64_110.dll not found
解决方案,重新安装了tensorflow-gpu参考链接: https://blog.csdn.net/FriendshipTang/article/details/113573114.
下载cudart64.110.dll文件,参考链接: https://blog.csdn.net/weixin_43786241/article/details/109203995. -
[TensorFlow] 运行报错——Ignore above cudart dlerror if you do not have a GPU set up on your machine.
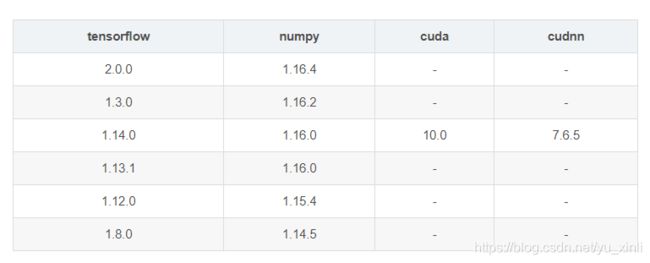
报错原因:cuda、cudnn、tensorflow版本问题,不能乱装。电脑好久之前装的cuda,都不记得版本了,tensorflow安装的时候没太在意版本,导致现在出错了。新手注意电脑的GPU、CUDA、CUDNN、tensorflow版本都是需要对应的。
解决方案:
1、查看CUDA版本
nvcc --version

2、TensorFlow-GPU与CUDA cudnn Python版本关系:
链接: https://tensorflow.google.cn/install/source_windows?hl=en#gpu.

笔者这里对应的tensorflow直接安装tensorflow_gpu-1.15.0,因为之前也报了 ‘tensorflow’ has no attribute 'contrib’错误,说是tensorflow2没有contrib包,所以还是安装tensorflow1方便。
如果已经安装过tensorflow,需要将之前的卸载
pip uninstall tensorflow-gpu
并且找到安装包的位置,我的在E:\anaconda3\Lib\site-packages下,将有关tensorflow和tensorboard的文件夹删除。再重新安装
pip install tensorflow-gpu==1.14.0
报了FutureWarning: Passing (type, 1) or ‘1type’ as a synonym of type is deprecated;错误,经查询是numpy版本错误,应该降低numpy版本,我又查找了numpy和tensorflow对应的版本,我应该安装1.16.0版本。
查询当前numpy版本
在python中输入
import numpy
numpy.__version__
输出显示我当前的版本是1.18.5
重装代码
pip install -U -i https://pypi.tuna.tsinghua.edu.cn/simple numpy==版本
U 是重装
i https://pypi.tuna.tsinghua.edu.cn/simple 是使用清华镜像
- 报错“list index out of range”,问题出在语句
cfg_model = list(filter(lambda o: o['model_name'] == model_name, cfgs))[0]
翻来覆去看也没发现什么问题这句,我没有耐心了,先看端到端文字检测与识别。
端到端文字检测与识别
架构
使用的是YOLOv2网络,这次是设置输出1001类,前一千个常见文字和一个其他类。
训练步骤
编译Darknet并下载预训练模型
这里很迷惑,不明白为什么突然讲起了darknet,看了教程很久,最后百度了一下darknet才知道,原来darknet是一个小众的深度学习框架,而且是基于YOLO的框架。我知识面有限,对深度学习的框架认识仅限于pytorch、tensorflow、caffe、keras,所以耽误很长时间。
该框架还是有一些独有的优点:
1.易于安装:在makefile里面选择自己需要的附加项(cuda,cudnn,opencv等)直接make即可,几分钟完成安装;
2.没有任何依赖项:整个框架都用C语言进行编写,可以不依赖任何库,连opencv作者都编写了可以对其进行替代的函数;
3.结构明晰,源代码查看、修改方便:其框架的基础文件都在src文件夹,而定义的一些检测、分类函数则在example文件夹,可根据需要直接对源代码进行查看和修改;
4.友好python接口:虽然darknet使用c语言进行编写,但是也提供了python的接口,通过python函数,能够使用python直接对训练好的.weight格式的模型进行调用;
5.易于移植:该框架部署到机器本地十分简单,且可以根据机器情况,使用cpu和gpu,特别是检测识别任务的本地端部署,darknet会显得异常方便。
这里对darknet的介绍参考链接,可以说是超级详细: https://blog.csdn.net/u010122972/article/details/83541978.
Darknet yolov3 Makefile文件解析链接: https://blog.csdn.net/u012435142/article/details/82957892.
初始化git子模块,这里意思是在当前git项目中使用darknet模块,将darknet模块称为子模块(submodule),可以将darknet仓库当作当前ctw仓库的一个子目录。可以手动下载darknet项目,下载地址在$CTW_ROOT/.gitmodules中,下载后放在detection/darknet文件夹下。
下载后编译
这里需要用到gcc 和g++,确保已经安装,打开cmd,更改目录到detection/darknet,试运行make -j8。
此处如果报错“不是内部或外部命令…”,可以查看自己的gcc和g++的环境变量是否配置正确,并在bin文件夹下寻找make编译程序文件。
例如我安装gcc后,在mingw64/bin文件夹下,发现编译程序的文件名是mingw32-make,因此将命令改为
mingw32-make -j8
原作者使用的是make。make是Linux下的一个命令工具,是一个解释makefile中指令的命令工具。它可以简化编译过程里面所下达的指令,当执行 make 时,make 会在当前的目录下搜寻 Makefile (or makefile) 这个文本文件,执行对应的操作。make 会自动的判别原始码是否经过变动了,而自动更新执行档。
预训练的yolov2权重下载链接: https://ctwdataset.github.io/.
![]()
设置类别数目
python3 decide_cates.py
可在setting.py中设置输出最常见的1000个类别,保存至products/cates.json中。