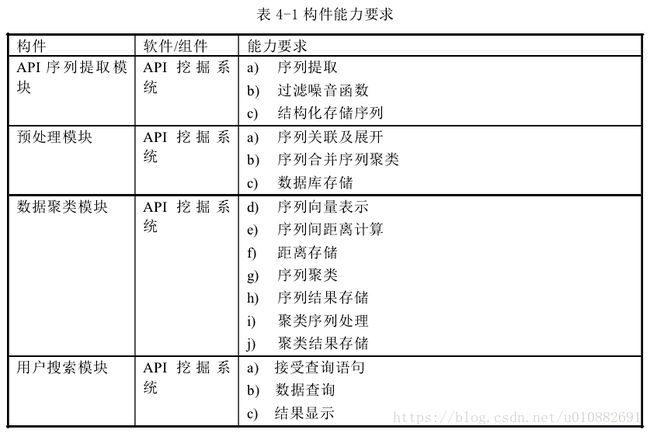
API挖掘系统说明书
API挖掘系统说明书
- API序列提取方法
- clang 序列提取
该部分的功能是逐条提取并记录调用方法所属的类、参数、名字命名空间等信息;并且标记循环中的方法.
- 过滤
该模块功能是过滤常用函数,去除噪音等。
- 结构化存储
将提取的 API 序列逐条结构化,以便后续模块处理。为序列添加上下文信息(比如起始位置及结束位置等)并结构化存储。
- API 序列关联
调用关系关联部分是将具有镶嵌关系进行展开处理,如主方法中序列为 A、B、C,另外方法 C 为 D、E,将序列 A B C 与序列 D E 进行关联。
- API 序列合并
API 调用序列合并是将完全相同的序列合并,对于一条新提取的 API 序列,查询序列池中是否有完全相同的序列,若有相同序列,则原序列池中序列统计属性数据做自加操作,新提取的序列不存入序列池;若新提取的序列在原序列池中没有相同的序列,则将新序列加入序列池。
- 数据库存储
经过以上步骤,得到了经过预处理后的序列池,下面就是将序列池中数据存入数据库,包括每条序列的上下文信息及组成方法的属性等。
- 聚类方法
本文研究的挖掘系统重要组成部分之一是聚类算法。聚类算法大概有五种分
类,分别为:划分聚类算法(K-平均算法等)、基于层次的聚类算法(BIRCH 算
法等)、基于密度的聚类算法(DBScan 算法等)、基于网格的聚类算法(STING算法等)、基于人工智能(神经网络等方向)的聚类算法(COBWEB 算法等)。划分聚类算法需要指定聚类数,本挖掘系统输入数据是 API 序列,无法指定聚类数,划分聚类算法不适合。基于层次的聚类算法处理大数据集时复杂度很高,本挖掘系统输入数据是百万行级别的代码库,基于层次的聚类算法也不适合。基于网格的聚类算法算法大大简化了聚类过程,虽然聚类时间很快,但聚类结果精度不高,所以基于网格的聚类算法也不是合适选择。聚类算法结合统计学及神经网络是较新的聚类研究方向,由于有生物学基础,该类算法自适应强,但是算法复
杂度很高,针对特定应用找合适的模型及降低复杂度是困难的,因此该类算法的应用还不成熟。基于密度的聚类算法能处理大数据集,并且基于密度的概念符合该应用场景,并且算法复杂度不高,因此基于密度的聚类算法在本应用场景下是适用的。基于密度的聚类算法有很多,原始算法是 DBScan 算法,其它基于密度的聚类算法是在 DBScan 算法的基础上发展来的,本系统使用该经典算法。下面阐述DBScan 算法基础及其增量算法基础。下面从算法的基本概念、算法过程、算法分析分别阐述。
对于聚类算法的输入,一般是用向量空间表示的数据集。因为在向量空间里,数据点用空间向量表示,这样就可以用经典计算距离的方法(比如欧几里得距离及切比雪夫距离等)来计算数据点之间的距离。
(1)
序列的向量表示
假如序列 1 有 m 个元素,序列 2 有 n 个元素,将这 2 个集合合并成 1 个集合,
新集合 set 共有 p 个元素,对这 P 个元素统一编号为 1,2,...,p,则序列 1 用 m 维
向量表示,每一维数据为序列中元素在 set 中对应编号。序列 2 同理可得其 n 维向量的表示。
例如:序列 1:f(),w(),g()序列 2:f(),h(),g()

则序列 1 向量为:A1={1,2,3};
序列 2 向量为 A2={1,4,3};
(2)
序列间的距离计算
针对每两个序列计算距离,两个序列向量合并形成新向量 S。例如:
序列 1 向量为:A1={1,2,3};
序列 2 向量为 A2={1,4,3};
新向量 S={1,2,3,4};
定义距离度 d 为 2 个集合中不同元素的个数。则两个序列向量的距离为:
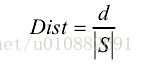
例如序列 1 和序列 2 距离度为 2,2 个序列间距离为:
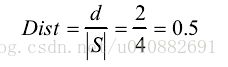
显然,Dist 取值范围为[0,1]。每两条序列求出距离后,将距离存入距离矩阵,n 条序列对应 nn的矩阵。得到距离矩阵后,在对序列进行聚类处理。经过改进后的距离计算方法能够很好的反应序列间的差异,时间复杂度为 O(n)
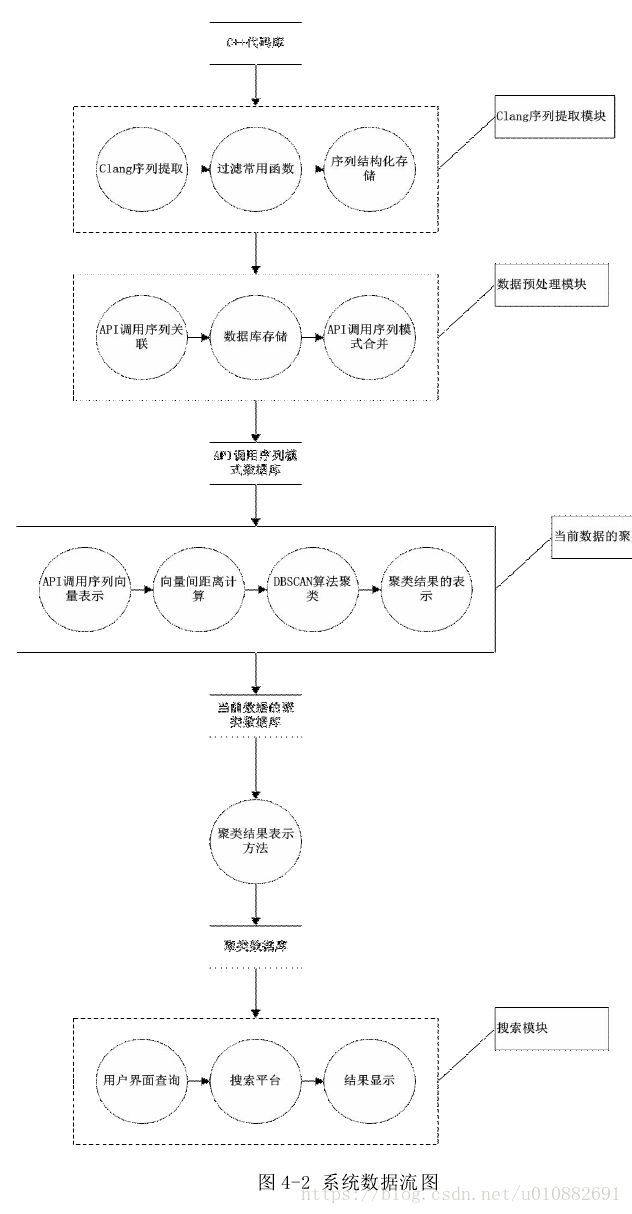
- 总体架构设计
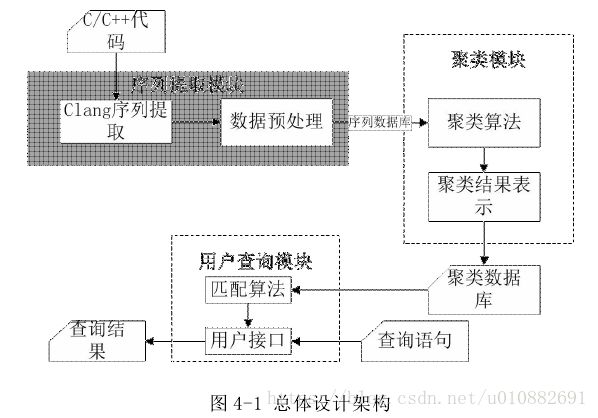
挖掘系统包括:
API 调用序列提取模块,数据预处理模块,数据聚类模块,用户搜索模块
- API 调用序列提取模块包括三个子模块,分别为 clang 序列提取模块、过滤模块、结构化存储模块。
- 数据预处理模式包括三个子模块,分别为 API 序列关联模块、API 序列合并模块、序列数据库存储模块。关联模块将 API 序列进行关联及层次展开,合并模块将相同的 API 序列合并且更新相关统计信息,序列数据库存储模块将 API 序列按设计的存储方法存储。
- 聚类模块计算数据库中 API 序列间距离并完成聚类。
其中 clang 调用序列提取模块,数据预处理模块及数据聚类模块组成模式挖掘模块。
- 搜索模块提供用户界面,获取用户输入的片段信息,将搜索结果返回给用户。
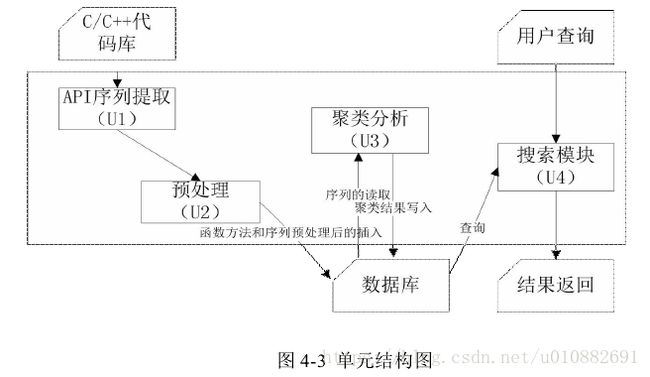
挖掘系统主要分为四大模块,按功能分为四个单元。
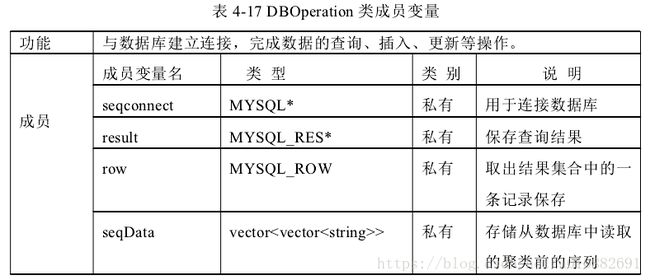
U1 单元经过 clang 序列提取后在内存中结构化存储 API 序列。U2 单元读取内存中 API 序列,将 API 序列方法进行存储,后将 API 序列经过预处理后结构化存储。U3 单元将预处理后的 API序列进行聚类处理,聚类结果写入聚类数据库。U4 单元读取用户查询信息,查询数据库,将符合查询要求的数据返回给用户。单元间的结构如下。
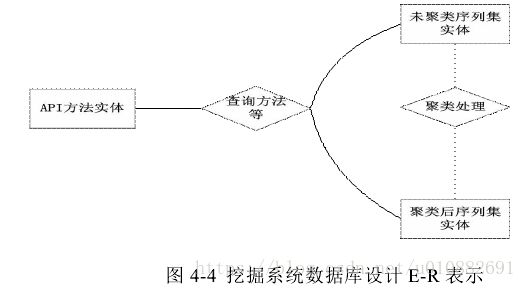
- 挖掘系统数据库的设计
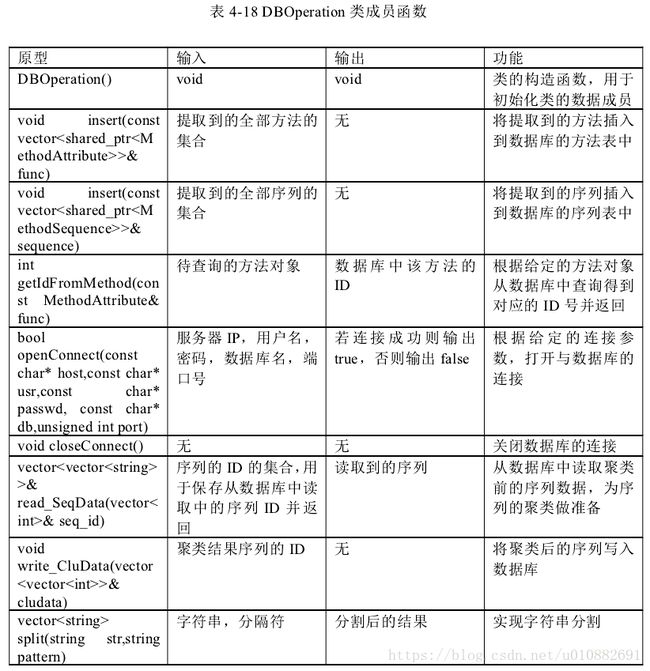
数据库中应该主要包含三张表:一张表用于存储 API 调用序列中全部方法,一张表用于存储原始的未经聚类的 API 调用序列,一张表用于存储经过聚类后所得到的 API 调用模式。这三张表对应着三个实体,分别为 API 方法实体、未聚类序列集实体、聚类后序列集实体,重点描述三实体关系。
-
- 方法存储表
存储 API 调用模式方法的表中的每一项不只包含有方法的名称,只有名称不能够唯一确定一个方法,
应该包含以下几项:
1. 方法名
2. 方法所属类名
3. 方法所在名字空间名称
4. 方法的参数类型

-
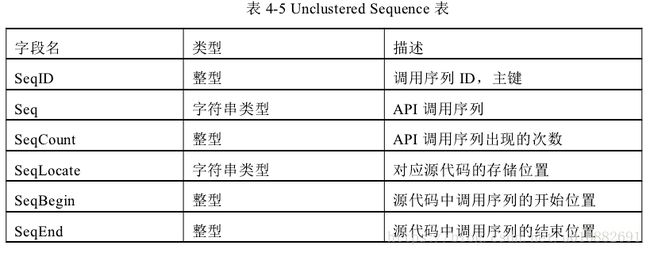
- 未经聚类的序列存储表
存储未经聚类的 API 调用序列的表中包含的项有:
1. API 调用序列
2. API 调用序列出现的次数
3. 调用序列的源代码片段
-
- 聚类的序列存储表
存储聚类后得到的 API 调用模式的表中应包含的项为:
1. API 调用模式
2. 调用模式的频数
3. 调用模式相应的代码片段
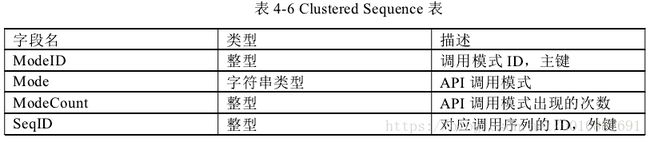
- API 序列提取模块的设计
对 C/C++代码,用开源编译器 Clang 完成对 API 调用序列的逐条提取并结构
化存储。并且记录调用方法所属类、参数、名字命名空间等属性信息。特别注意
记录循环中的调用方法及重载函数的处理。通过记录 API 相关属等信息,就可以
完成对 C++特殊语法的分析,比如通过参数及返回类型就可以对 C++重载函数语法
分析。该模块数据流图如图 4-5 所示。
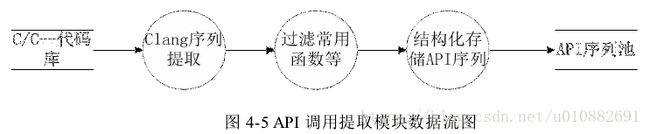
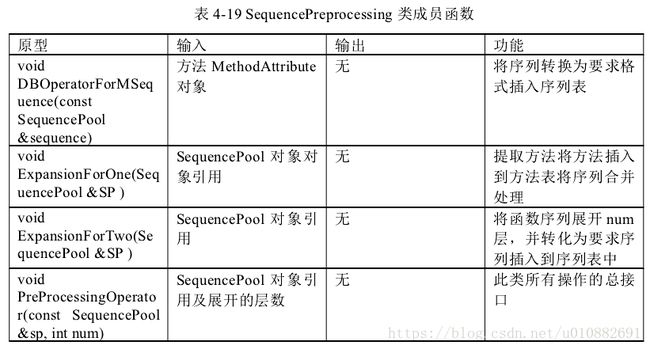
本单元主要实现 API 序列提取的功能,主要包括用户参数解析、API 序列提取、
序列和序列元素的表示、函数过滤、结构化存储 API 序列的功能。主要设计了类
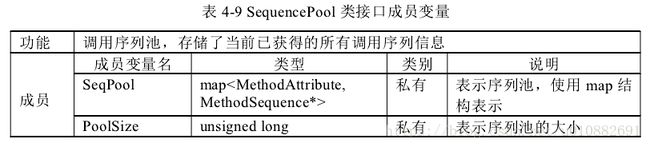
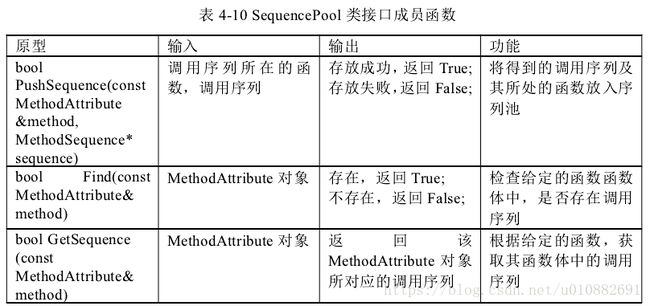
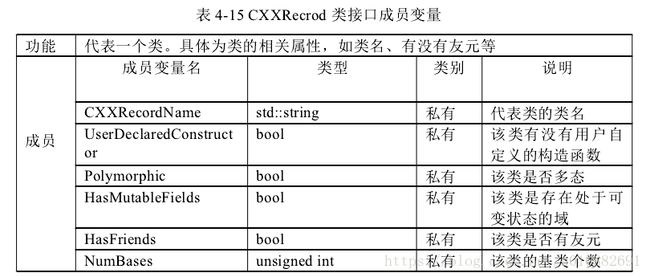
Method Extract ASTVisitor、类 Sequence Pool、类 Method Attribute、类 Method Sequence、
类 CXXRecrod。类 Method Extract ASTVisitor 负责遍历 Clang 编译源码生成的 AST树,提取 API 调用序列。类 Sequence Pool 调用序列池,存储了当前已获得的所有
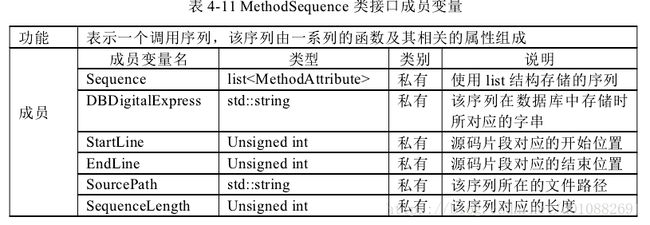
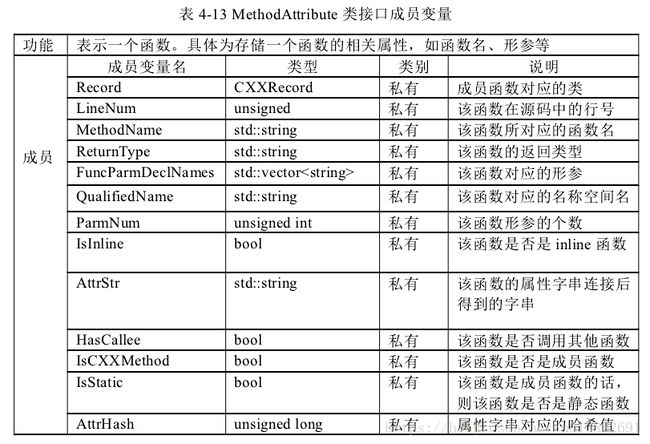
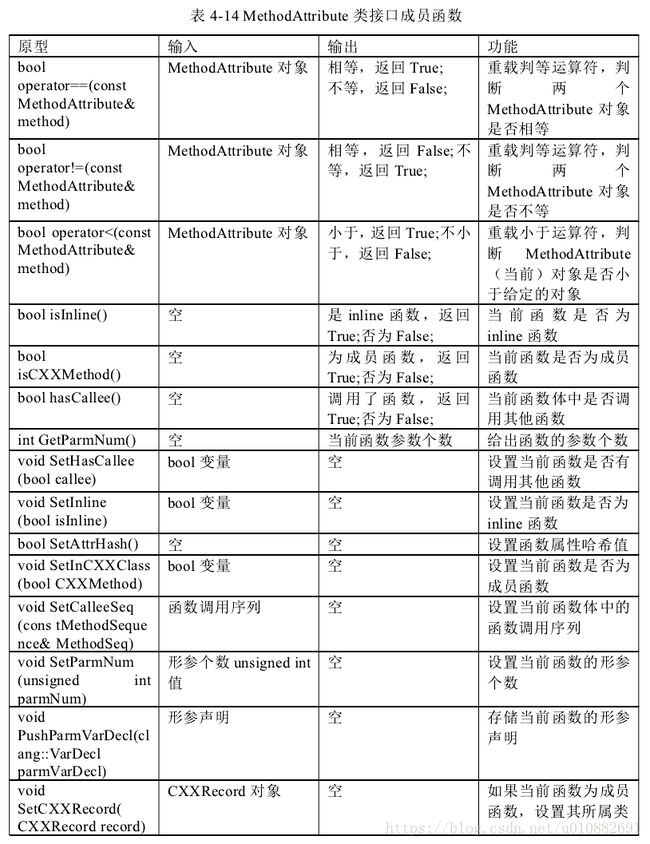
调用序列信息。类 Method Attribute 表示一个调用序列,该序列由一系列的函数及
其相关的属性组成。类 Method Sequence 表示一个函数。具体为存储一个函数的相
关属性,如函数名、形参等。类 CXXRecrod 代表一个类,具体为类的相关属性,如类名、有没有友元等。具体设计类图如图 4-6 所示。
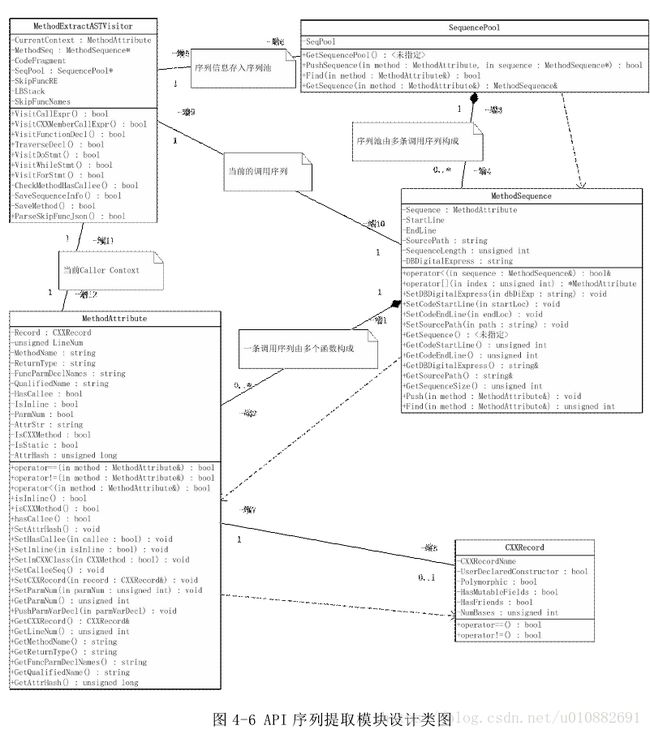
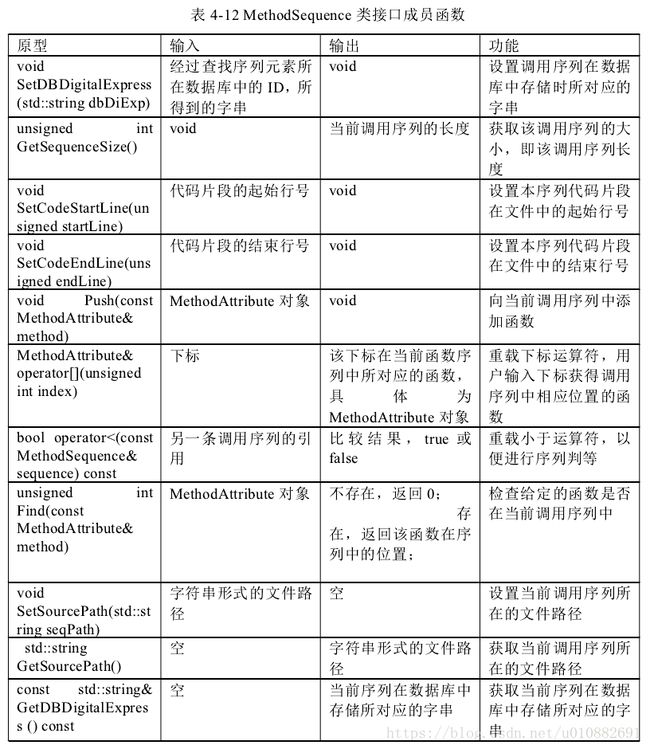
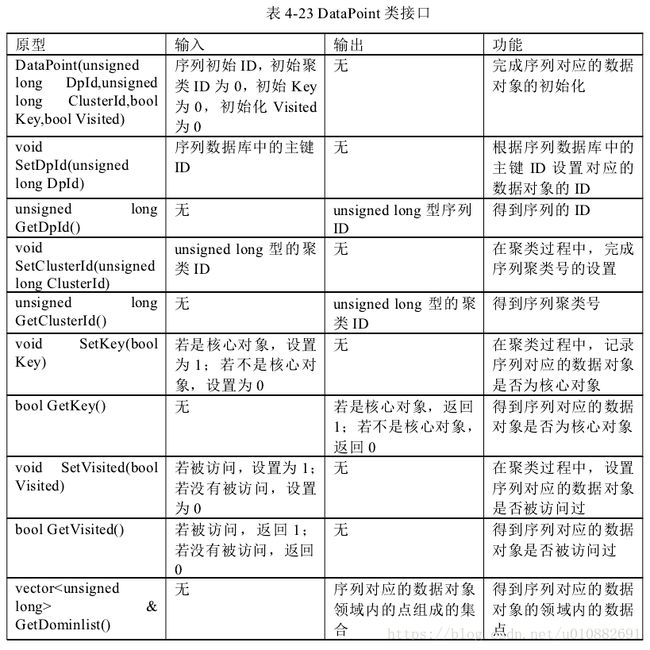
下面分别对这个五个类接口设计予以表格阐述,
Method Extract ASTVisitor 接口
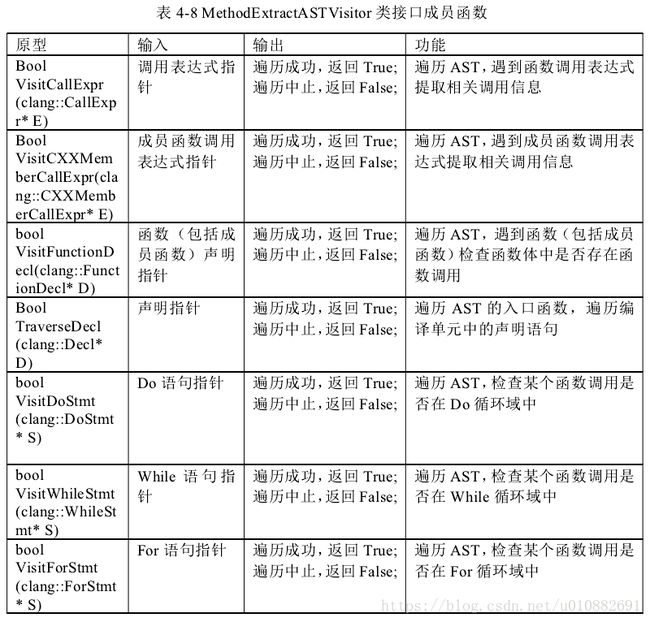
- 数据预处理模块的设计
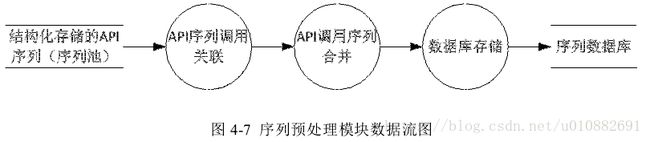
本小节主要对预处理模块方法设计予以描述。上一节我们已经介绍过,经过
clang 序列预处理后,得到的是序列池(存储若干序列及其上下文信息)。本模块
的输入数据即为序列池,本模块主要功能有三个,分别为:API 序列关联、API 序
列合并及数据库存储。首先调用关系关联模块是将具有镶嵌关系进行展开处理,
如主方法中序列为 A、B、C,另外方法 C 为 D、E,将序列 A B C 与序列 D E 进
行关联。序列关联处理后,将相同的序列进行合并处理,并记录该序列出现的次
数(为搜索结果排序提供依据)。序列合并处理后,将处理后的序列及其属性信
息存储到数据库中。预处理模块数据流图如 4-7 所示。
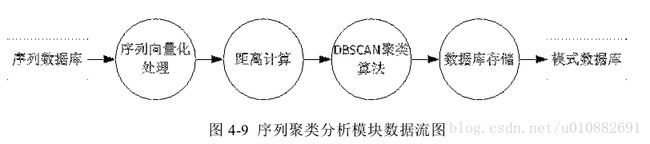
- 聚类模块的设计
本模块以序列数据库中的序列作为输入。首先计算任意两条序列之间的距离
得到距离矩阵,然后将 DBScan 算法应用到本场景中进行聚类分析。聚类完成后将
聚类结果按照其所在的簇进行分组,即属于同一个簇的序列被分在一组。同时将
所有的噪声序列归于一个独立的组,以便于在存储聚类结果时对其进行过滤。最
后将聚类结果以簇为单位写入模式数据库中,为序列模式查询模块提供直接数据
来源。该模块的数据流图如图 4-9 所示。

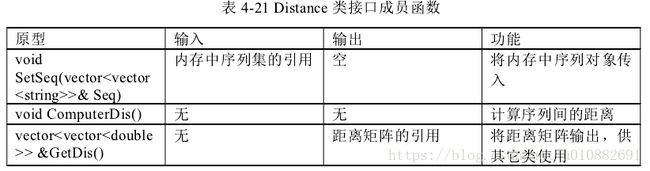
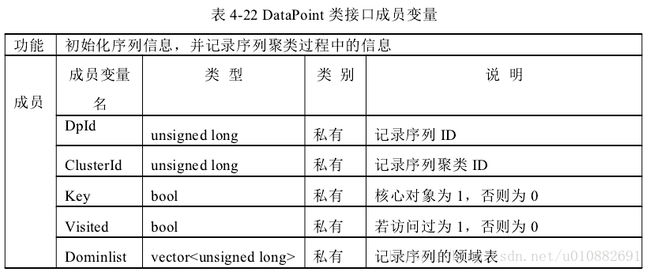
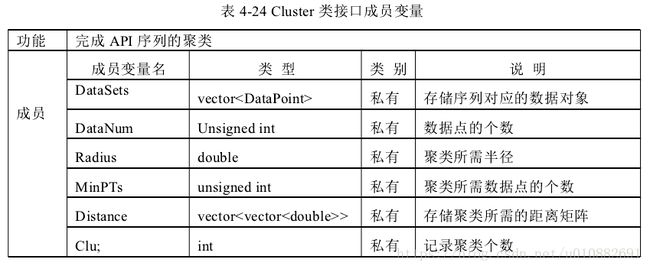
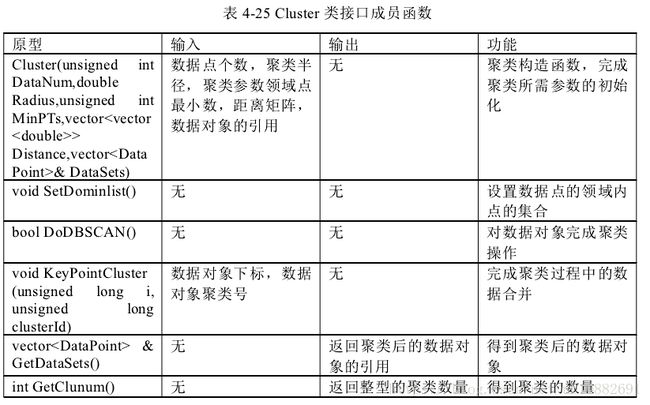
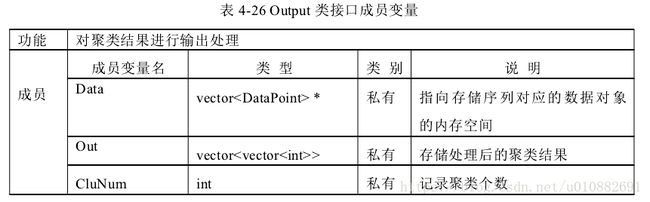
本单元实现序列的聚类功能。将序列读入内存,作为输入;将聚类结果作为
输出。本单元一共四个类,分别是
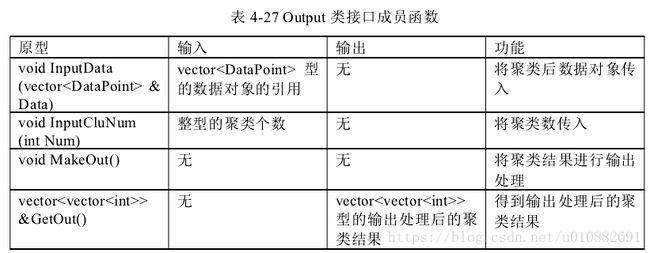
Distance 类、Data Point 类、Cluster 类、Output类。
其中 Distance 类完成序列间距离的计算;Data Point 类完成聚类所需数据信息设置;
Cluster 完成序列的聚类;Output 完成对聚类结果的输出处理。
- 搜索模块的设计
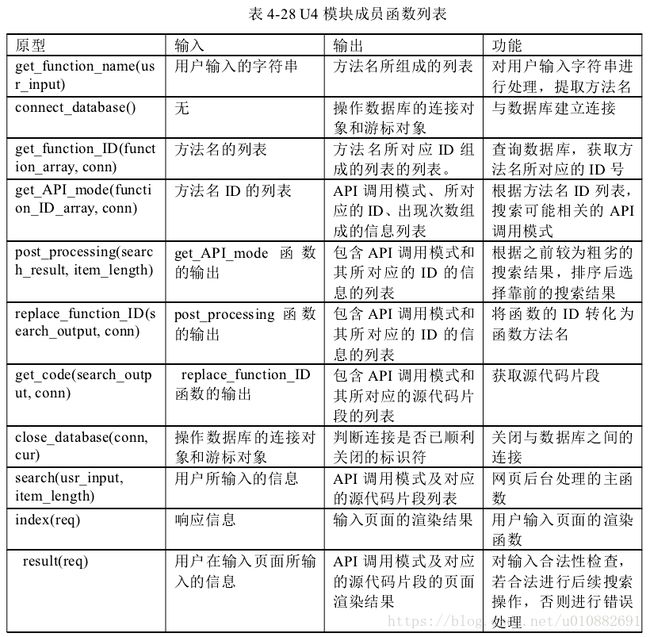
用户在搜索框中输入想查找的方法的名称,通过查找数据库中相应的表,返回API 调用模式,且是以使用频率从高到低排序的。并且还要返回与 API 调用模式相应的源代码片段。返回 API 调用模式的条数可由用户指定。
整个搜索模块是以网页的形式来呈现的。模块包括两个部分:第一是前端部
分,主要功能包括提供用户输入信息的页面、展示搜索结果的页面、和一些返回
错误信息的页面;第二是后台部分,主要功能是根据前端返回的用户输入信息,
进行一系列处理和查询数据库的操作,得到 API 调用模式和其相应的源代码片段,
返回给前端。该模块成员函数列表如表 4-28 所示。

整个模块使用 Python 实现,Web 应用框架采用 Django,Web 服务器采用Apache。
-
-
- 前端设计
-
前端的主要功能就是获取用户输入的搜索信息,将其传递给后台;获取后台
处理的结果,将其展示给用户。所以,应该具有的网页如下:
(1)搜索的开始页面,供用户输入搜索的信息;
(2)搜索结果的页面,展示搜索得到的 API 调用模式和其对应的源代码片段;
(3)一些显示错误信息的页面,包括数据库连接错误、用户输入错误、和文件
不存在错误。其中,用户输入的搜索信息应该包括:输入的方法名和显示结果的条数。数据
库连接错误出现在创建与数据库的连接时与关闭与数据库的连接时,可能是由于
连接参数设置的问题。用户输入错误出现在对用户输入的信息进行检查时,例如
用户并没有输入要搜索的方法名、用户输入的方法并不存在、输入显示结果的数
目为 0 等等。这些错误都归结于因为用户的输入而产生的。文件不存在错误是在
读取源代码片段时,文件由于某种原因并在指定的路径下而产生的错误。
-
-
- 后台设计
-
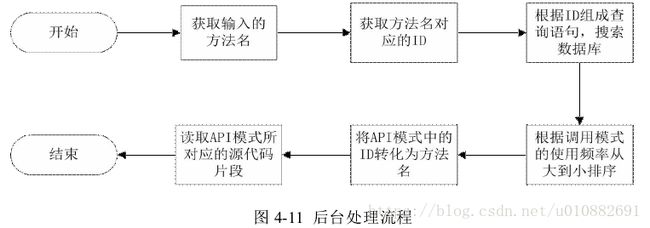
后台部分所需实现的主要功能是根据前端传来的用户的输入数据,提取出方
法名,根据方法名查询数据库得到相对应的 ID 信息,将这些 ID 信息组合成一条
查询语句,利用数据库的模糊查询技术,查询与之相似的 API 调用模式,根据获
取到的其他信息,读取与该 API 调用模式相对应的源代码片段,最后根据其出现的频率从大到小排序,将结果返回给前端。处理的整个流程如图 4-10 所示。

在第一个步骤中,主要是对用户输入的搜索字符串进行处理,忽略掉其中的
一些符号,例如“(”或“)”,提取出用户想要搜索的方法名。由于用户输入的
内容中可能并不包含一个合法的方法名,所以会返回一个信息指示前端显示用户
输入错误页面。在第二个步骤中,主要是根据前一步所得到的方法名,查询数据库,获取其对应的 ID 信息。由于在数据库中可能并不存在用户输入的方法名,所以会返回一个信息指示前端显示用户输入错误页面。
在第三个步骤中,主要是根据前一步所得的
ID,组合成一条查询语句,搜索数据库,获取与之相似的 API 调用序列。由于一个函数名可能不止对应于一个 ID可能由于函数的重载等等情况),需要对方法名所对应的
ID 进行一个组合的操作,操作的方式类似于笛卡儿积。在对数据库进行查询时,所使用的方式是模糊查询,这一技术会在下一部分进行详细的介绍。由于需要连接数据库,可能由于
参数错误导致创建连接失败,所以会返回一个信息指示前端显示数据库连接错误页面。同样的,由于在数据库中可能并不存在由用户输入的方法名所组成的序列,所以会返回一个信息指示前端显示用户输入错误页面。
在第四个步骤中,主要是根据前一步获得的使用频率的信息,对
API 调用序列按照从大到小的顺序进行排序。并截取出用户所想要的输出的条数。
在第五个步骤中,由于之前所获取的 API 调用序列是由函数的 ID 信息所组成
的,用户阅读起来并不方便,通过查询数据库将其转换为对应的方法名信息。
在第六个步骤中,主要是根据之前获取的 API 调用序列对应的源代码文件的
位置信息和开始结束的位置信息,读取源代码片段。由于需要读取 API 调用序列
的源代码片段,需要打开其所在的文件,该文件可能并不存在,所以会返回一个
信息指示前端显示文件不存在页面。以上六个步骤为后台处理过程,后台读取前台用户输入数据后,查询处理后将匹配数据返回给用户。后台处理流程如图 4-11 所示。
-
-
- 数据库查询设计
-
本挖掘系统中,由于输入信息是 API 模式的部分信息,所以在查询数据库时,
完整匹配不符合实际应用情况,只能采取模糊匹配进行搜索,将模糊搜索的结果
返回给用户。数据库常用模糊匹配方式是用 like 后面跟条件,因此条件的设计是
数据库查询设计的关键。
在本系统所用的 MYSql 数据库中,数据库本身对条件有以下几种修饰方式:
(1) %:字符串的抽象表示,比如“挖掘系统的设计”,用该修饰符可以表示
为:“%的设计”,该修饰符可以抽象任意字符串。显然,“%系统”表示以“系
统”两字结尾的字符串,“系统%”表示以“系统”两字开头的字符串,所以通过
“%系统%”即可构造搜索所有含有“系统”两字的字符串的条件。
(2) _:单个字符的抽象,例如“挖掘”,用该修饰符可以表示为:“挖_”, 通过合理使用该字符,可以对搜索字符串的长度设定。比如要搜索含有“系统”
两字的长度为 4 的字符串,即可构造搜索条件:“_ _系统”或者“系统_ _”。
(3) []:对括号内单个字符的抽象,括号更像对一个集合的定义,括号内元素
为此位置单个字符的候选。比如搜索“挖掘设计”及“方法设计”字符串,但可
能还有“界面设计”等,即“设计”二字前必须为“挖掘”或者“方法”,则该
搜索条件即可设定为“[系统,方法]设计”。
(4) [^ ]:对括号内元素补集的一个抽象,表示在该位置不能为括号内的元素。
比如搜索“**设计”,但排除“挖掘设计”字符串,则搜索条件即可设定为:“[^
挖掘]设计”。通过以上方法的介绍,就可以设计实际搜索应用中的条件。在实际情况下,
用户在搜索框中搜索其想了解的 API 调用串。本系统读取用户输入的每一个函数
名,在数据库的 function 表中查找其所对应的 ID 号。不妨假设用户输入了两个方
法名,对应的 ID 号分别为 ID_1,ID_2,则我们可以构造 SQL 语句为: SELECT* FROM clustered_sequence WHERE API 调用模式 LIKE ‘%ID_1%ID_2%’。存在一个函数名对应着不同
ID 的可能性,这样我们就只需要做一些组合即可。
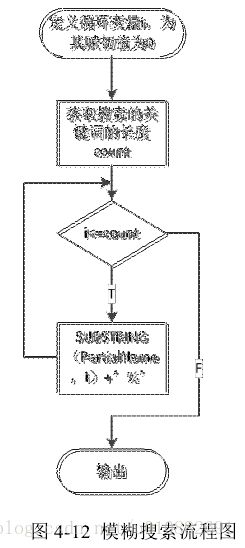
综上,提取用户输入的所有关键词,即一个或者若干个方法,在后台进行模
糊查询过程之前,构造查询条件,若用户没有指定限制条件,则默认搜索包含用
户输入的 API 的所有序列串。其流程如图 4-12 所示。
- 挖掘系统的特性要求
从实际应用出发,API 调用挖掘系统需满足下列 4 个特性:
1.高性能;
5分钟内完成100K C/C++代码的API模式挖掘;平均每10000万个API使用模式搜索响应时间小于2s。
2.处理大数据
API 挖掘工具能完成百万行级 C/C++代码的 API 使用模式挖掘。并完成聚类分析。
3.特殊功能
支持重载函数和函数作用域等C++语法分析。
4.模块化
模式聚类功能不与其他功能耦合,可单独使用,支持对多个代码片段做模式
挖掘和聚类分析。