【论文学习】Soft-NMS: 用一行代码改进目标检测
在目标检测领域,非极大值抑制是目标检测管道中的重要一环。那么你知道它的原理吗?它有哪些缺点?如何改进?
本文会介绍NMS和改进方法Soft-NMS。 后续会陆续介绍其他几篇有名的NMS变体,包括IoU-Guided NMS、Adaptive NMS、DIoU-NMS、Softer-NMS等。 详情关注【CV面试宝典】,回复关键词【NMS】可获取NMS与其变体的论文资料。
摘要
非极大值抑制(NMS)是目标检测管道中的一个必要组成部分。首先,它基于目标检测框的置信度对所有目标检测框进行排序,其中得分最高的检测框M被选中,然后其余检测框和M的重叠度超过阈值(阈值是预先设定)的检测框将被抑制。这个过程是递归地应用到剩余的目标检测框中。根据此算法的设计,如果一个目标检测框位于预先设定的重叠阈值内,它将被丢弃。为此,我们提出了Soft-NMS算法,该算法将其他目标检测框的置信度衰减为它们与M的重叠的连续函数。因此,在这个过程中没有目标被忽略。Soft-NMS在标准数据集上获得一致的提升,如PASCAL VOC2007数据集上R-FCN和Faster-RCNN均提升1.7%,MS-COCO数据集上R-FCN提升1.3%以及Faster-RCNN提升1.1%。Soft-NMS这种方式在不增加任何超参数的情况下仅仅对NMS进行改进即可实现。利用Deformable-RFCN,Soft-NMS在单一模型下将目标检测的最新水平从39.8%提升到40.9%。并且Soft-NMS的计算复杂度和传统的NMS是一样的,因此可以有效的实现。因为Soft-NMS没有要求任何额外的训练,且易于实现,因此它可以很容易地集成到任何目标检测管道中。Soft-NMS的代码公开可用,这里是Github地址
1. 引言
目标检测是计算机视觉的一个基本问题,在这个问题中,一个算法为指定的目标类别生成边界框,并给它们分配类别置信度。它在自动驾驶[6,9]、视频/图像索引[28,22],监控[2,11]等方面有许多实际应用。因此,为目标检测管道提出的任何新组件都不应造成计算瓶颈。否则在实际实现中很容易被忽略。此外如果引入一个复杂的模块,并需要对模型进行重新训练,且性能仅仅略有提高,那么它也将被忽略。然而,如果一个简单的模块可以在不需要对现有模型进行任何重新训练的情况下提高性能,那么它将被广泛采用。为此,本文提出了一种Soft-NMS算法,以替代传统的NMS算法在当前管道目标检测中的应用。
传统的目标检测管道[4,8]采用了一种基于多尺度滑动窗口的方法,该方法根据在每个窗口中计算的特征为每个类分配前景/背景得分。然而,邻近窗口通常具有相关分数(这会增加假阳性) ,因此非极大抑制被用作后处理步骤以获得最终检测结果。随着深度学习的出现。使用卷积神经网络生成的类别独立的区域建议算法,取代了滑动窗口算法。在最先进的检测器中,这些建议的区域被输入到一个分类子网络,该子网络为它们分配特定类别的分数[ 16,24],同时另一个并行的回归子网络细化了这些建议的位置。这一改进过程改善了对象的定位,但也导致了混乱的检测,因为多个建议往往会回归到相同的兴趣区域(ROI)。因此。即使在最先进的探测器,也会使用非极大抑制来获得最后的检测结果,因为它显著地减少了假阳性的数量。
笔者注:
上文提到了假阳性的名词。在目标检测中存在TP,FP,FN,TN四个表达,具体含义如下。
- 真阳性 True Positive(TP):一个正确的检测,检测的IOU ≥ threshold。即预测的边界框(bounding box)中分类正确且边界框坐标正确的数量。
- 假阳性 False Positive(FP):一个错误的检测,检测的IOU < threshold。即预测的边界框中分类错误或者边界框坐标不达标的数量,即预测出的所有边界框中除去预测正确的边界框,剩下的边界框的数量。
- 假阴性 False Negative(FN):一个没有被检测出来的ground truth。所有没有预测到的边界框的数量,即正确的边界框(ground truth)中除去被预测正确的边界框,剩下的边界框的数量。
- 真阴性 True Negative(TN): 在目标检测领域不适用。 在目标检测任务中,存在许多不应该在图像内检测到的可能的边界框。 因此,TN代表正确未检测到的所有可能的边界框(图像中的如此多的可能框)。
**非极大值抑制过程开始于一个检测框列表B和一个对应的置信度列表S,在选择最高置信度的检测框M之后,将M从集合B中删除,并将其附加到最终检测集合 D中。然后从B中删除任何和M的重叠度大于阈值Nt 的检测框。对于B中剩余的检测框,继续重复这个过程。**非极大值抑制的一个主要问题是,它将与M检测框相邻的检测框的置信度直接设置为零。因此,如果一个对象实际上出现在重叠阈值中,它也将会被忽略,从而导致平均精度(AP)下降。但是。如果我们使用其他检测框与M重叠的函数来衰减它们的置信度,那么其他检测框就仍然会在检测框列表B中,只是置信度变低了。我们在下图中展示了这个问题的一个例子。
笔者注:上文这段话描述了NMS的过程,以及存在的主要问题。

利用这种直觉,我们对传统的贪婪 NMS 算法提出了一种单线修正方法,该算法采用重叠度的函数来降低目标检测框的置信度,取代在NMS中直接置为0。即如果一个边界框与 M有很高的重叠,那么它应该被分配一个很低的分数;而如果一个边界框与M有很低的重叠甚至没有重叠,它可以保持它原来的检测分数。这个 Soft-NMS 算法如图2所示。Soft-NMS导致了在PASCAL VOC和MS-COCO这样的标准数据集上,在多个重叠阈值上测量最先进的目标检测器,其平均精度显著提高。由于Soft-NMS不需要任何额外的训练,而且易于实现,因此它可以很容易地集成到对象检测管道中。

笔者注:
在上图中,红框内容是传统NMS做法。绿框内容是改进后的Soft-NMS做法。
Soft-NMS的改进就这么简单,但确实解决了NMS存在的问题。
什么问题呢,其实在上文中已经提到了:在密集预测的场景下,两个物体距离很近,置信度低的物体会因为和置信度高的物体重叠度高而被抑制(置信度置为0),从而导致平均精度降低。
那么采样Soft-NMS后不会将置信度直接置为0,而是将置信度置为一个基于重叠度的函数值。这个函数满足随着重叠度越大,函数值越小的规律。
2. 相关工作
近50年来,NMS 已经成为计算机视觉中许多检测算法中不可或缺的一部分。它首先应用于边缘检测技术[25]。随后,它被应用于多种任务,如特征点检测[19,12,20]、人脸检测[29]和目标检测[4,8,10]。在边缘检测中,NMS 进行边缘细化以去除虚假响应[25,1,31];在特征点检测器[12]中,NMS可以有效地执行局部阈值来获得唯一的特征点检测。在人脸检测[29]中,NMS 是通过使用重叠准则将边界框划分为不相交的子集来执行的,最终检测是通过对集合中边界框的坐标进行平均得到的。用于人体探测,Dalal 和 trigs [4]证明了贪婪的 NMS 算法,其中选择具有最大检测分数的边界框,并使用预定义的重叠阈值抑制其相邻框,与用于人脸检测的方法相比提高了性能[29]。从那时起贪婪的NMS已经成为目标检测领域实际使用的算法[8,10,24,16]。
令人惊讶的是,这个检测管道的组成部分已经保持了十多年。当将平均精度(AP)作为评估指标时,贪婪 NMS 仍然获得最好的性能,被应用于最先进的检测器[24,16]。一些基于学习的方法被提出作为贪婪NMS的一种改进,它们在目标检测方面取得了良好的性能[5,26,211]。例如,[26]首先计算每对检测框之间的重叠,然后进行亲和度传播聚类,为每个聚类选择代表最终检测框的子集。在21 中提出了该算法的一个多类版本。然而,目标检测是一个不同的问题,所有类的对象实例在每幅图像上同时计算。因此,我们需要为所有类选择一个阈值,并生成一组固定的框。由于不同的阈值可能适用于不同的应用,在通用目标检测中,平均精度是通过计算一个特定类中所有对象实例的排序列表来计算的,因此贪婪NMS对这些算法的性能是有利的。
在另一项工作中,为了检测显著对象,提出了一种建议子集优化算法,作为贪婪 NMS 的替代方案。该算法采用基于MAP的子集优化方法,共同优化检测窗口的个数和位置。在显著的目标检测中,算法只期望找到显著的目标,而不是找到所有的目标。因此,这个问题也不同于一般的对象检测,并且贪婪NMS在测量目标检测性能时表现良好。对于行人检测这样的特殊情况,提出了一个二次无约束二元优化(QUBO)解决方案,它使用检测分数作为一元潜力,检测框之间的重叠作为一对潜力来确定检测框的最优子集。与贪婪 NMS 一样,QUBO 也使用了一个硬阈值来抑制边界框。这不同于 Soft-NMS。在另一个基于学习的行人检测框架中,,决定点过程与个体预测分数相结合,以优化选择最终检测结果[15]。据我们所知,对于通用目标检测,贪婪的 NMS 仍然是PASCAL VOC 和 MS-COCO目标检测数据集中最强的基线。
3. 背景
在本节中,我们简要描述了用于最先进的目标检测器中的目标检测管道。在推理过程中,目标检测网络使用深度卷积神经网络(CNN)对一幅图像执行一系列卷积操作。目标检测网络在L层分化出两个分支,一个分支生成区域建议,而另一个分支通过池化由区域建议网络生成的 ROI 内的卷积特性进行分类和回归。
其中区域建议网络为特征图中每个像素上的多尺度锚定框,生成分类置信度和回归偏移量。然后对这些锚定框进行排序,并选择置信度最大的K个锚定框 (约 6000个),在这些锚定框基于预测的回归偏移量,以获得每个锚定框在图像中水平坐标;对这K个锚定框应用贪婪NMS,最终生成区域建议(proposals)。
然后分类网络为每个区域建议生成分类和回归分数。由于网络中没有强制它为目标物体生成唯一 RoI的约束,因此多个区域建议可能对应同一物体。因此除了第一个正确的边界框之外。同一物体上的其他边界框都会产生假阳性。为了解决这个问题,对每个类的检测框独立地执行非极大值抑制NMS,并使用一个特定的重叠阈值。由于检测物体的数量通常很小,而且可以通过过滤低于非常小的阈值的检测框来进一步减少,因此在这一阶段采用非最大值抑制并不需要昂贵的计算量。针对这种非极大值抑制算法,我们在目标检测通道中提出了一种可替代的方法。目标检测管道的概述如图3所示。

4. Soft-NMS
当前目标检测的评估标准是强调精确定位,并在多个重叠阈值(从0.5到0.95)上测量检测框的平均精度。因此,当评价指标AP重叠阈值设置为0.7时,应用具有低阈值(如0.3)的 NMS可能会导致平均精度下降。从这里开始,我们将检测评估阈值设置为 O t O_t Ot。
这是因为可能有一个检测框 b i b_i bi非常接近一个对象(在0.7重叠阈值范围内),但得分略低于 M M M( M M M没有覆盖对象),因此 b i b_i bi会被低的NMS阈值 N t N_t Nt抑制。随着重叠阈值标准的增加,这种情况的可能性也会增加。因此,以一个低阈值 N t N_t Nt抑制附近所有检测框,会增加错误率。
当 O t O_t Ot很小时,使用高阈值 N t N_t Nt如0.7,将增加假阳性。这种情况下,假阳性增加远远超过真阳性的增加。因为图像中的物体数量远少于检测器生成的ROI的数量。因此,使用一个高NMS阈值也是不合适的。
笔者注:
O t O_t Ot小,且 N t N_t Nt大时,过滤掉的检测框就会很少。这时对于一个Ground truth ,会有多个检测结果。因为只有一个是正确的结果,因此会增加假阳性。
O t O_t Ot大,且 N t N_t Nt小时,过滤掉的检测框就会很多。这时对于一个Ground truth, 可能没有一个对应的检测结果,会使得正确的物体不被识别,这时会增加假阴性。
且 N t N_t Nt在由小变大的过程,也是对应于Ground truth,从没有对应的检测结果,到检测出结果。这样做,虽然增加了真阳性,同时也增加了假阳性,且由于图像中要检测的物体是有限的,则真阳性的增加是有限的。在由小到大的过程中,假阳性的增加会逐渐远远大于真阳性。所以 N t N_t Nt通常不适合设置过大。一般设置为0.4左右
为了克服这些困难,我们更加细致地回顾了NMS算法。在NMS算法中的剪枝步骤可以写成如下评分函数:
s i = { s i i o u ( M , b i ) < N t 0 i o u ( M , b i ) > = N t s_i= \begin{cases} s_i& {iou(M,b_i) < N_t}\\ 0& {iou(M,b_i) >= N_t} \end{cases} si={si0iou(M,bi)<Ntiou(M,bi)>=Nt
因此,NMS 设置了一个硬阈值,其决定了哪些边界框应该从 M M M的领域保留或删除。假设,我们衰减一个与 M M M重叠度很高的边界框 b i b_i bi的得分,而不是完全抑制它。如果 b i b_i bi包含一个未被 M M M包含的对象,它不会在较低的检测阈值上导致失败。但是,如果 b i b_i bi未包含任何对象,而 M M M包含一个对象,即使在它的分数衰减后,它的排名仍高于真正的检测,它仍然会产生一个假阳性,因此 NMS 应该考虑以下条件:
- 相邻检测的得分应该降低到这样的程度: 它们增加假阳性率的可能性较小,同时在检测列表中的排名明显在误报的检测框之上。
- 用较低的 NMS 阈值去除相邻的检测框将是次优的,如果评估在较高的重叠阈值上执行,将会增加失败率。
- 当 NMS 阈值较高时,在重叠阈值范围内测量的平均精度将下降
我们在6.3节上通过实验评估了这些条件。
**Soft-NMS的评分函数:**衰减与M重叠的其他检测框的分数似乎是改进NMS的一个有希望的方法。同样清楚的是,与M重叠更高的检测框的分数应该衰减得更多,因为它们有更高的假阳性的可能性。因此,我们建议使用以下规则更新修剪步骤:
s i = { s i i o u ( M , b i ) < N t s i ( 1 − i o u ( M , b i ) ) i o u ( M , b i ) > = N t s_i= \begin{cases} s_i& {iou(M,b_i) < N_t}\\ s_i(1-iou(M,b_i))& {iou(M,b_i) >= N_t} \end{cases} si={sisi(1−iou(M,bi))iou(M,bi)<Ntiou(M,bi)>=Nt
上述函数将使高于阈值 N t N_t Nt 的检测框得分衰减为与 M M M重叠有关的线性函数,因此,距离较远的检测框不会受到影响,而距离较近的检测框则会受到较大的惩罚。
但是。它在重叠程度方面不是连续的。当 满足NMS 阈值 N t N_t Nt时,会突然施加惩罚。如果惩罚函数是连续的,那将是理想的,否则它可能导致检测列表的排名的突然变化。连续惩罚函数在没有重叠的情况下不应该有惩罚,而在高重叠的情况下惩罚很高。另外,当重叠度较低时,应该逐渐增加惩罚,因为 M M M不应该影响与之重叠很低的检测框的得分。然而,当一个检测框 b i b_i bi与 M M M的重叠变得接近1, b i b_i bi应该显著的惩罚。考虑到这一点,我们建议用高斯惩罚函数更新剪枝步骤:
s i = s i e − i o u ( M , b i ) 2 σ s_i= s_i e^{-\frac{iou(M,b_i)^2}{\sigma}} si=sie−σiou(M,bi)2
在每次迭代中应用此更新规则,并更新所有剩余检测框的得分。
图2中正式描述了Soft-NMS算法,其中 f ( i o u ( M , b i ) ) f(iou(M,b_i)) f(iou(M,bi))是基于重叠的加权函数。Soft-NMS中每一步的计算复杂度为 O ( N ) O(N) O(N),其中N是检测框的数目。这是因为与M重叠的所有检测框的分数都会更新。因此,对于N个检测框,Soft-NMS的计算复杂度为 O ( N 2 ) O(N^2) O(N2),这与传统贪婪nms相同。因为nms不会适用于所有检测框(在每次迭代中对具有最小阈值的检测框进行修剪),这一步骤的计算成本不高,因此不影响当前检测器的运行时间。
注意,Soft-NMS 也是一种贪婪算法,不能找到检测框的全局最优重新评分。检测框的重新评分是以贪婪的方式执行的,因此具有高局部得分的检测不被抑制。然而,Soft- NMS 是NMS的一种普遍形式,传统 NMS 是它的特例,可以看作不连续二元加权函数。除了这两个函数,还可以利用Soft- NMS探索其他具有更多参数的函数,例如,可以使用类似 Gompertz 函数的广义 Logistic函数。但这样的功能会增加超参数的数量。
5. 数据集和评估
我们在两个数据集上进行实验,PASCAL VOC [7]和 MS-COCO [17]。Pascal 数据集有20个对象类别,MS-COCO 数据集有80个对象类别。我们选择 VOC 2007测试集来度量性能。对于 MS-COCO 数据集,敏感性分析是在一个公开的5,000图像的小型数据集进行。我们还展示了 MS-COCO 数据集上的测试分区的结果,该数据集由20,288张图像组成。
为了评估我们的方法。我们实验了三种最先进的探测器,即 FASTER-RCNN [24]、R-FCN[16]和 Deformable-RFCN。
对于 PASCAL 数据集,我们选择了作者提供的公开可用的预训练模型。FASTER-RCNN 目标检测模型采用 VOC 2007训练数据集来训练,R-FCN目标检测模型采用VOC 2007和2012数据集的训练。
对于 MS-COCO,我们也使用Faster-R2CNN 的公开可用模型。然而,由于在MS-COCO数据集上R-FCN没有公开可用的模型,我们从一个ResNet-101CNN框架开始在 Caffe 训练自己的模型。对RPN anchors 简单的修改为5个尺度,使用的最小图像大小为800,每个小批量使用16张图像,每个图像使用256个ROI。训练是在8个 gpu 上并行进行的。请注意,我们的实现比文献[16]中报道的在没有使用多尺度训练或测试的情况下获得了1.9% 的准确率。因此,这是在MS-COCO 数据集上 R-FCN 的一个强基线。
这些检测器都使用默认的 NMS 阈值0.3。在灵敏度分析部分,我们也改变了这个参数,并给出了结果。我们也用相同的训练数据集训练 Deformable-RFCN。在10e-4的阈值上,使用4个 CPU 线程,它每个图像(80个类)花费0.01 s。在每次迭代之后,降低反复脱粒的重新丢弃的计算时间减少。在10e-2,运行时间是0.005秒在一个核心。我们将MS-COCO上每个图像的最大检测数设置为400,评估服务器选择每个类的前100个检测数来生成度量(我们确认COCO评估服务器直到2017年6月才选择每个图像的前100个得分检测数)。将最大探测次数设置为100,可减少AP0.1。
实验
在本节中,我们通过实验显示了比较结果,并且执行了敏感度分析分析来显示Soft-NMS相对于传统NMS的健壮性。我们还进行特定的实验,以了解为什么和在哪里做Soft-NMS比传统 NMS 更好.
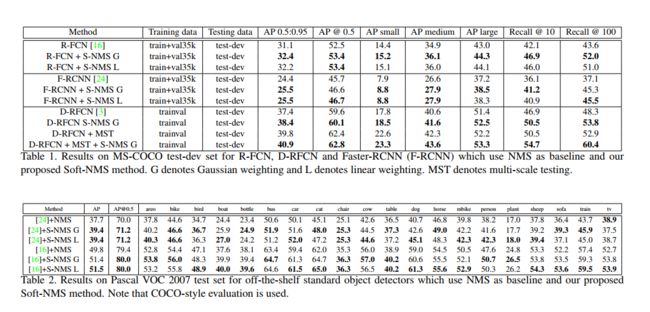
6.1 结论
在表一中,我们在MS-COCO数据集上使用NMS和Soft-NMS来比较R-FCN 和 Faster-RCNN。当使用线性加权函数时,我们将 N t N_t Nt设置为0.3,高斯加权函数设置 σ \sigma σ为0.5。显然,在任何情况下Soft-NMS(使用高斯和线性加权函数)均比NMS来说改善了性能。特别是当 AP 计算在多个阈值并平均。例如,我们分别在R-FCN 和 Faster-RCNN获得了1.3% 的改进和1.1%的改进。这对于 MS-COCO 数据集来说意义重大。注意,我们只需要改变 NMS 算法就可以得到这种改进,因此它只需要很少的改变,可以很容易地应用在多个检测器上。我们在 PASCAL VOC 2007测试集上做了同样的实验,如表1所示。我们还报告平均精度,Soft-NMS对 Faster-RCNN 和 R-FCN 均有1.7% 的改进。对于没有区域建议的 SSD [18]和 YOLOV2[23]等检测器,利用线性函数Soft-nms 仅仅提升0.5% 。这是因为区域建议的检测器具有更高的召回率,因此Soft-NMS 在更高的 O t O_t Ot下具有更大的提高召回率的潜力。
从现在开始。在所有的实验中。当我们提到 NMS 时,它使用高斯加权函数。在图6中,我们还显示了 MS-COCO 的每个类别的提升。有趣的是,在 R-FCN 上使用 Soft-nms 可以使斑马、长颈鹿、绵羊、大象、马等动物的性能提高3-6% ,而使用烤面包机、运动球、吹风机等物体的性能提高很少,因为这些物体在同一图像中不太可能同时出现。
6.2 敏感度分析
Soft-NMS有一个参数 σ \sigma σ,传统NMS有一个重叠阈值参数 N t N_t Nt。我们改变这些参数并在 MS-COCO最小数据集上测量每个检测器的平均精度,见图4。

注意,AP在0.3到0.6之间是稳定的,并且对于这两个目标检测器来说,在这两个范围之外AP均显著下降。对于传统的 NMS 来说,AP 在这个范围内的变化约为0.25% 。Soft-NMS 在0.1到0.7之间获得比 NMS 更好的性能。其性能稳定在0.4ー0.7之间,即使选择最佳的 NMS 阈值,每个检测器的性能也会改善1%。
在我们所有的实验中,我们设置了 σ \sigma σ为0.5,尽管0.6似乎在表现得更好。这是因为我们后来才进行了敏感度分析实验,得到了0.1% 没什么显著影响。
6.3 Soft-NMS在什么情况下工作得更好?
当Soft-NMS在性能上获得显著提高时,平均精度本身并不能清楚地解释。因此,我们提出了在不同重叠阈值下测量NMS和Soft-NMS的平均精度。我们还通过改变NMS和Soft-NMS超参数来了解这两种算法的特点。从表3中我们可以推断,平均精度随着NMS阈值的增加而降低。
当 O t O_t Ot比较高时,尽管较高的 N t N_t Nt比低的 N t N_t Nt获得稍好的性能,但使用一个低阈值 N t N_t Nt,AP也下降的不明显。另一方面,当 O t O_t Ot比较低时,较高的 N t N_t Nt比低的 N t N_t Nt获得明显的下降。因此,当AP在多个阈值上取平均值时,我们观察到性能下降。因此,对于传统的NMS,使用更高的 N t N_t Nt获得更好的性能并不意味着 O t O_t Ot值更低。
然而,当我们为软nms改变 σ \sigma σ时,我们观察到不同的特性。表3显示,即使我们在较高的 N t N_t Nt获得更好的性能,在较低的 N t N_t Nt下的性能也不会明显下降。此外,我们观察到,在高的 O t O_t Ot下无论所选 N t N_t Nt的值如何,Soft-NMS都比传统NMS表现得更好约2%。而且对于的任何超参数( σ \sigma σ或$N_t),最佳AP始终是Soft-NMS更好。这个比较非常清楚地表明,在所有参数设置中。
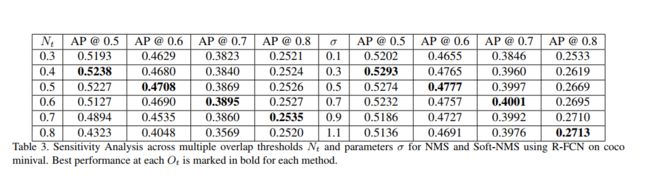
Soft-NMS的最佳参数 σ \sigma σ比传统NMS中选择的硬阈值 N t N_t Nt性能更好。而且当所有阈值的性能都是平均值时,由于Soft-NMS中的单参数设置在 O t O_t Ot的多个值下都能很好地工作,因此总体性能增益得到了放大。正如预期的那样,在 O t O_t Ot较低时 σ \sigma σ的低阈值表现更好;在 O t O_t Ot较高时 σ \sigma σ的高阈值表现更好;sigma的高值在O较高时表现更好。与NMS不同,其 N t N_t Nt值较高时AP的改善很小。而Soft-NMS在在 O t O_t Ot较高时较高的 σ \sigma σ对AP的提升明显。
因此,为了更好的定位( O t O_t Ot高),更大的 σ \sigma σ能被用来提升性能。而对于NMS来说是适用,因为高阈值 N t N_t Nt带来很小的提升。
最后,我们还想知道,在不同的 O t O_t Ot值下,什么样的召回率Soft-NMS 比 NMS 表现得更好。注意,在Soft-NMS中我们重新给检测框分数打分,并给它们分配较低的分数,因此我们不指望在较低的召回率下精确度会有所提高。然而,随着 O t O_t Ot和召回率的增加,Soft-NMS在精确度上获得了显著的提高。这是因为,传统的 NMS 为所有重叠大于 N t N_t Nt的方框分配了一个零分。因此许多检测框被遗漏,因此在更高的召回率下准确率不会增加。Soft-NMS 重新对邻近的边界框进行评分,而不是完全压制它们,从而提高了在搞的召回率下检测的准确率。