搭建这个hadoop集群电脑表示要离家出走!
1.hadoop集群搭建的详细过程
实验前的准备:
== jdk ==
jdk-8u11-linux-x64.tar.gz
提取码:wgte
== hadoop ==
hadoop-2.10.1.tar.gz
提取码:bfxz
== VMware ==
官网下载
== centOS -XXX…-iso ==
文件过大阿里云镜像下载
== Xshell或其他软件 ==
2.jdk的安装和环境变量的配置,hadoop的安装
此处不再做过多解释,大厅有详解
3hadoop的下载安装
windows安装hadoop教程
4.VM的下载和安装

更改安装位置,选择加入path环境,选择安装位置,点击下一步。
直接下一步,vmware会自己安装,等待即可。
搭建环境并创建虚拟机
教程
搭建hadoop需要三个虚拟机,但是对电脑配置要求便较高,如果电脑不适用就选择克隆虚拟机不要创建,不然会卡。
克隆的过程:
右键点击创建的虚拟机comepter_one,在点击管理,点击克隆
点第二个,下一步。

最后选择位置,输入名称就ok了。
创建三个虚拟机,即可。

点击开启,三个都开打开Xshell,在centOS中输入** ifconfig ** 查看ip地址。
点击file中的new会跳出下图

编辑name,在host输入上面查到的ip,完成后点击图中Authentication。
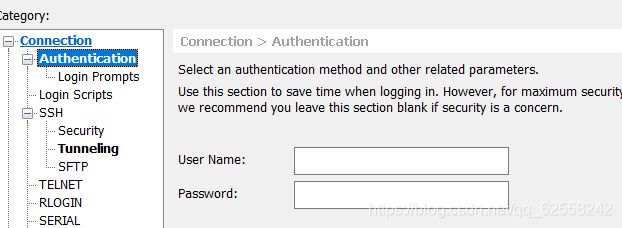
在user name中输入创建虚拟机时建的用户和密码,建议直接root用,不然后面还要获取root权限,完成都点击connect。
链接成功后时== root@username ==,三个虚拟机依次链接。
5.虚拟网络配置
在开始界面搜索虚拟网络配置器,或者在计算机设置里找
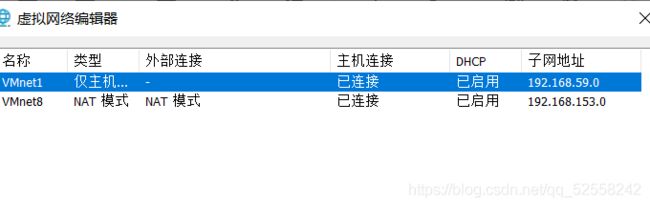
点击NAT模式,在点击NAT设置查看网关,子网掩码。
在Xshell中输入:vim /etc/sysconfig/network-scripts/ifcfg-eth0这窜代码,按i进入编辑模式输入(注:vim后有空格):
| 名称 | Value |
|---|---|
| DEVICE= | eth0 |
| BOOTPROTO= | static |
| ONBOOT= | yes |
| IPADDR= | IP地址 |
| GATEWAY= | 网关 |
| NETMASK= | 子网掩码 |
| DNS1= | 8.8.8.8 |
字符串要有引号包裹BOOTPROTO=“static”,ip地址时最开始在虚拟机中查到的地址,数字不用引号。
输入完成后按ESC切换命令模式,SHIFT+:输入wq后按ENTER保存退出。
6.更改主机名称
命令:
hostname 查看主机名
hostnamectl set-hostname [克隆时的名称]
(方法不限这一种)
7. 建立主机名与ip地址的映射
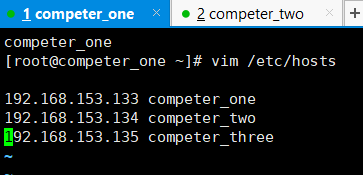
输入 vim /etc/hosts修改,方法和上面的一样** i—>编辑模式(下面有一个enter标志)—>输入ip地址和名称(ip地址依然是在centOS中查的,名称时之前改的)—>ESC—>SHIFT+:—>wq—>enter(就ok了)这只Linux的命令如果遇到其他问题自行上网查找,查看:cat /etc/hosts。
三个虚拟机都要改!!!
8.关闭防火墙
状态查看:systemctl status firewalld.service
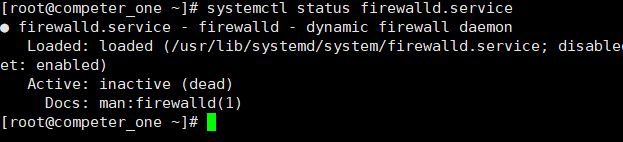
图中Active是状态,后面显示表示关闭(我已经关闭了)关闭代码是:
关闭代码:systemctl stop firewalld.service
永久关闭:systemctl disable firewalld.service
后面两个代码依次输入就可以永久关闭,最后用第一个查看是否关闭成功,是图中状态就成功了。
9.SSH免密码登录[^2]
重点
// 步骤:
在root用户下输入ssh-keygen -t rsa 三次回车(图一)
接着输入cd ~/.ssh 后回车
输入 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
再输入chmod 600 ~/.ssh/authorized_keys
输入cat authorized_keys
出现如图的问句是输入yes即可(图二)
之后就可以输入ssh-copy-id 名称 添加机器就OK了(两台虚拟机)
ssh 名称 (切换)
== 间隙大的有空格 ==
- 出现下图即可
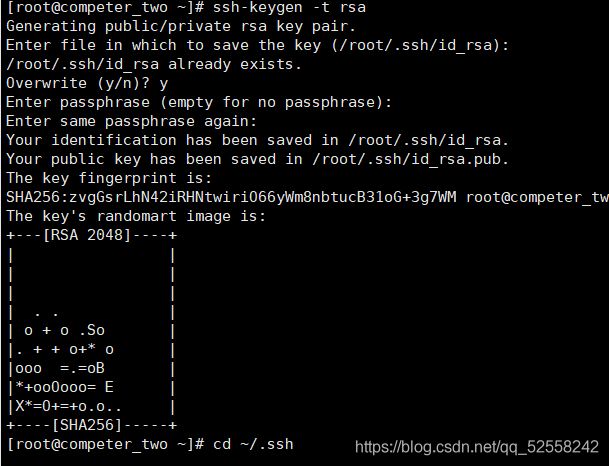
- 图一(密钥生成)
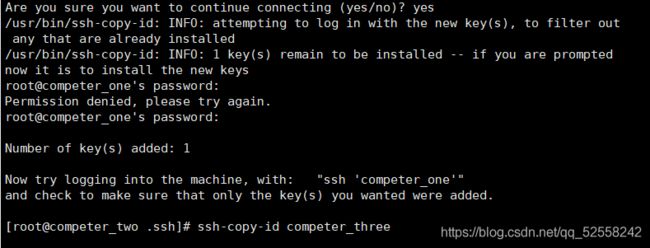
- 图二(
还有一种情况如图
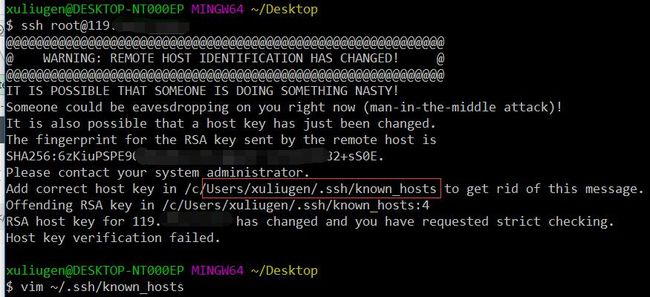
出现这样的错误导致不能切换登录可输入vi ~/.ssh/known_hosts
并将与该主机ip地址相同的内容全部删去即可
10.安装JDK找到jdk的绝对路径
jdk安装和解压
(1)先再虚拟机中建立jdk的目录,可以建再桌面,也可以再其他目录但自己要清楚它的绝对路径。命令是 mkdir /home/jdk(home是我的主目录)
(2)将下载的jdk的压缩包上传到其中一个虚拟机中,可以直接拖拽,如果不能的可以下载Xftp传输文件的软件进行上传。
(3)进入虚拟机的界面右键点击->进入终端界面->tar -zxvf home/jdk ** (这是解压命令,如果不行,就再桌面调出子目录后提取也可) **
(4)如图是成功安装的标志(我已经解压所以有前面的文件夹)
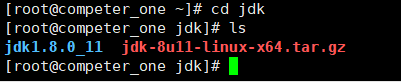
jdk环境变量的配置
(1)输入 == vim /etc/profile == 进入编辑模式添加:(命令前面已讲)
export JAVA_HOME=/home/jdk (对应自己的jdk目录,jdk名称写完整)
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin (到bin目录)
// 验证:
source /etc/profile
java -version
出现java版本型号是就配置成功
(2)将工作目录复制到其余节点:
scp -r /home/jdk competer_two:/home/
scp -r /home/jdk competer_three:/home/
(3)将配置文件复制到其余节点:
scp -r /etc/profile competer_two:/etc/
scp -r /etc/profile competer_three:/etc/
(4)在其余节点重复操作,然后验证是否配置成功
-r前后有空格,competer_two是名称
11.zookeeper的安装
apache-zookeeper-3.5.9
提取码:cqc8
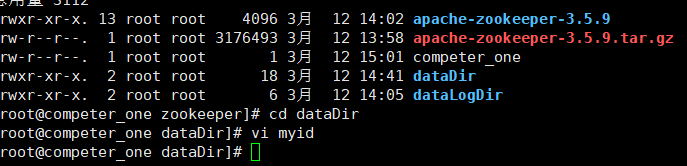
将压缩包上传到机器的zookeeper文件中(没有建一个mkdir命令)解压步骤和jdk相同,再zookeeoer中建dataDir和dataLogdir,存放数据和日志,若不创建登录目录则事务日志和快照日志都会写到data目录下,将会严重影响zookeeper的性能
切换到dataDir(cd /root/zookeeper/dataDir) 再当前目录下输入vi myid 将里面的类容编辑为ech0 “1” >/home/zookeeper/dateDir/myid (即myid文件的绝对路径,这是我设置的绝对路径)
将zookkeeper复制到其他两台机子上就欧克了,复制命令:scp -rp 【绝对路径同上】最后切换到其他两台机子将ech 后面的== 1 ==该为 2,3 就行了。

配置环境变量见下链接(感谢作者) :
zookeeper环境变量
至此我们已完成
后面三节下次跟新偶