HDFS编程实践(Hadoop3.1.3)
目录
1,在学习HDFS编程实践前,我们需要启动Hadoop(版本是Hadoop3.1.3)。执行如下命令:
一、利用Shell命令与HDFS进行交互
1.目录操作:
2.文件操作:
二、利用Web界面管理HDFS
三、编程实现以下指定功能,和使用 Hadopp 提供的 Shell 命令完成相同的任务。
三、利用Java API与HDFS进行交互
(一) 在Ubuntu中安装Eclipse/idea
HDFS编程实践(Hadoop3.1.3)
1,在学习HDFS编程实践前,我们需要启动Hadoop(版本是Hadoop3.1.3)。执行如下命令:
cd /usr/local/hadoop #切换到hadoop的安装目录
./sbin/start-dfs.sh #启动hadoop一、利用Shell命令与HDFS进行交互
Hadoop支持很多Shell命令,其中fs是HDFS最常用的命令,利用fs可以查看HDFS文件系统的目录结构、上传和下载数据、创建文件等。
① 查看fs总共支持了哪些命令: ./bin/hadoop fs
② 查看具体某个命令的作用: (例如:我们查看put命令如何使用): ./bin/hadoop fs -help put
1.目录操作:
(前提切换到hadoop的安装目录下)
| hadoop fs -ls hadoop fs -mkdir hadoop fs -cat hadoop fs -copyFromLocal ● 在配置好Hadoop集群之后,可以通过浏览器登录“http://localhost:9870”访问HDFS文件系统 ● 通过Web界面的”Utilities”菜单下面的“Browse the filesystem”查看文件 |
① 在HDFS中为hadoop用户创建一个用户目录:
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir -p /user/hadoop■ 该命令中表示在HDFS中创建一个“/user/hadoop”目录,“–mkdir”是创建目录的操作,“-p”表示如果是多级目录,则父目录和子目录一起创建,
这里“/user/hadoop”就是一个多级目录,因此必须使用参数“-p”,否则会出错。
② 查看目录下的内容:
./bin/hdfs dfs -ls .■ 该命令中 . 表示HDFS中的当前用户目录, 即 “/user/hadoop”目录
■ 列出HDFS上的所有目录命令:./bin/hdfs dfs -ls
③ 创建一个input目录:
./bin/hdfs dfs -mkdir input■ 在HDFS的根目录下创建一个名称为input的目录:
./bin/hdfs dfs -mkdir /input④ rm命令删除一个目录或文件(删除 input 目录):
./bin/hdfs dfs -rm -r /input2.文件操作:
■ 在本地Linux文件系统的“/home/hadoop/”目录下创建一个文件myLocalFile.txt,里面可以随意输入一些内容,Linux创建文件命令: touch filename
① 上传:上传本地文件(myLocalFile.txt)到HDFS:(上传到HDFS的“/user/hadoop/input/”目录下:)
./bin/hdfs dfs -put /home/hadoop/myLocalFile.txt input■ ■ ■ 向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件:
✿bug:Comman ‘hdfs’ not found,did you mean: command ‘hfs’ from deb hfsutils-tcltk…
■ 原因是没有在bin目录下设置PATH,因此相关hadoop或者hdfs的命令都无法正常使用。
解决:
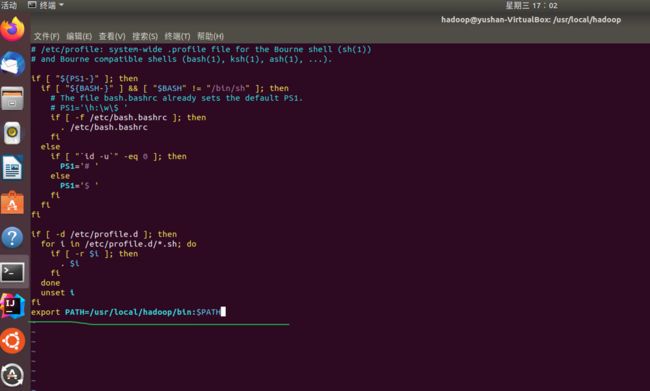
① sudo vi /etc/profile
② 然后在最下面加入一行配置PATH:(i 键进入编辑状态,Esc 退出编辑键,ZZ(两个大写的ZZ)保存并退出vim)
export PATH=/usr/local/hadoop/bin:$PAT
| 1 |
|
| 1 |
|
| 1 2 3 4 |
|
(text.txt 是Hadoop 系统中的一个文件, ~/下载/test.txt 是本地文件)
![]()
② ■ ■ ■ 从 HDFS 中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名;
(file:///下载/text.txt 是本地文件)if $(hdfs dfs -test -e file:///下载/text.txt) # hadoop 系统上是否存在文件名(与本地系统中的text.txt)相同?

③ ■ ■ ■ 将 HDFS 中指定文件的内容输出到终端中; -cat 命令啦 ./bin/hdfs dfs -cat myHadoopFile
![]()
④ ■ ■ ■ 显示 HDFS 中指定的文件的读写权限、大小、创建时间、路径等信息; -ls 命令啦 ./bin/hdfs dfs -ls myHadoopFile
![]()
⑤ ■ ■ ■ 给定 HDFS 中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,
如果该文件是目录,则递归输出该目录下所有文件相关信息; (-ls 命令 的递归选项啦 -R) ./bin/hdfs dfs -ls -R myHadoopDir

⑥ ■ ■ ■ 提供一个 HDFS 内的文件的路径,对该文件进行创建和删除操作; -rm 命令啦 ./bin/hdfs dfs -rm myHadoopFile
(如果文件所在目录不存在,则自动创建目录)
![]()
⑦ 供一个 HDFS 的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在,则自动创建相应目录;
删除目录时,由用户指定当该目录不为空时是否还删除该目录; -rmr 命令
例如:hadoop fs -rmr myHadoopDir⑧ 向 HDFS 中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾;
./bin/hdfs dfs -appendToFile local.txt ./myHadoopFile.txt(注意:appendToFile 是将当地文件内容追加的到 hadoop 上的文件(不能hadoop上的文件1 追加给 hadoop上的文件2))
⑨ 删除 HDFS 中指定的文件; -rm 命令即可
⑩ 在HDFS中,将文件从源路径移动到目的路径; -mv 命令
例如:hadoop fs -mv /usr/local/hadoop/test.txt /usr/local/hadoop/hadoop_tmp/hello.txt| ● 使用ls命令查看一下文件是否成功上传到HDFS中: ./bin/hdfs dfs -ls input ● 使用-cat 命令查看HDFS中的myLocalFile.txt 的内容: ./bin/hdfs dfs -cat input/myLocalFile.txt ● 上传:上传本地文件(myLocalFile.txt)到HDFS:(上传到HDFS的“/user/hadoop/input/”目录下:)./bin/hdfs dfs -put /home/hadoop/myLocalFile.txt input ● 下载:从HDFS 下载文件到本地:(把HDFS中的myLocalFile.txt文件下载到本地文件系统中的“/home/hadoop/下载/”): ./bin/hdfs dfs -get input/myLocalFile.txt /home/hadoop/下载 ● 拷贝:把文件从HDFS中的一个目录拷贝到HDFS中的另外一个目录 (比如,如果要把HDFS的“/user/hadoop/input/myLocalFile.txt”文件,拷贝到HDFS的另外一个目录“/input”中): ./bin/hdfs dfs -cp input/myLocalFile.txt /input ● 追加内容:向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾: ./bin/hdfs dfs -appendToFile local.txt ./myHadoopFile.txt (注意:appendToFile 是将当地文件内容追加的到 hadoop 上的文件(不能hadoop上的文件1 追加给 hadoop上的文件2)) |
二、利用Web界面管理HDFS
利用Linux自带的火狐浏览器,WEB界面的访问地址是http://localhost:9870。通过Web界面的”Utilities”菜单下面的“Browse the filesystem”查看文件。
三、编程实现以下指定功能,和使用 Hadopp 提供的 Shell 命令完成相同的任务。
1. 向HDFS中上传任意文本文件,如果指定的文件在 HDFS 中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件。
hadoop fs -put /User/Binguner/Desktop/test.txt /test
hadoop fs -appendToFile /User/Binguner/Desktop/test.txt /test/test.txt
hadoop fs -copyFromLocal -f /User/Binguner/Desktop/test.txt / input/test.txt /**
* @param fileSystem
* @param srcPath 本地文件地址
* @param desPath 目标文件地址
*/
private static void test1(FileSystem fileSystem,Path srcPath, Path desPath){
try {
if (fileSystem.exists(new Path("/test/test.txt"))){
System.out.println("Do you want to overwrite the existed file? ( y / n )");
if (new Scanner(System.in).next().equals("y")){
fileSystem.copyFromLocalFile(false,true,srcPath,desPath);
}else {
FileInputStream inputStream = new FileInputStream(srcPath.toString());
FSDataOutputStream outputStream = fileSystem.append(new Path("/test/test.txt"));
byte[] bytes = new byte[1024];
int read = -1;
while ((read = inputStream.read(bytes)) > 0){
outputStream.write(bytes,0,read);
}
inputStream.close();
outputStream.close();
}
}else {
fileSystem.copyFromLocalFile(srcPath,desPath);
}
} catch (IOException e) {
e.printStackTrace();
}
}2. 从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名。
hadoop fs -copyToLocal /input/test.txt /User/binguner/Desktop/test.txt /**
* @param fileSystem
* @param remotePath HDFS 中文件的地址
* @param localPath 本地要保存的文件的地址
*/
private static void test2(FileSystem fileSystem,Path remotePath, Path localPath){
try {
if (fileSystem.exists(remotePath)){
fileSystem.copyToLocalFile(remotePath,localPath);
}else {
System.out.println("Can't find this file in HDFS!");
}
} catch (FileAlreadyExistsException e){
try {
System.out.println(localPath.toString());
fileSystem.copyToLocalFile(remotePath,new Path("src/test"+ new Random().nextInt()+".txt"));
} catch (IOException e1) {
e1.printStackTrace();
}
} catch (IOException e) {
e.printStackTrace();
}
}3. 将HDFS中指定文件的内容输出到终端中。
hadoop fs -cat /test/test.txt /**
* @param fileSystem
* @param remotePath 目标文件地址
*/
private static void test3(FileSystem fileSystem,Path remotePath){
try {
FSDataInputStream inputStream= fileSystem.open(remotePath);
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
String line;
while ((line = bufferedReader.readLine()) != null){
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
}4. 显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息。
hadoop fs -ls -h /test/test.txt /**
* @param fileSystem
* @param remotePath 目标文件地址
*/
private static void test4(FileSystem fileSystem, Path remotePath){
try {
FileStatus[] fileStatus = fileSystem.listStatus(remotePath);
for (FileStatus status : fileStatus){
System.out.println(status.getPermission());
System.out.println(status.getBlockSize());
System.out.println(status.getAccessTime());
System.out.println(status.getPath());
}
} catch (IOException e) {
e.printStackTrace();
}5. 给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息。
hadoop fs -lsr -h / /**
* @param fileSystem
* @param remotePath 目标文件地址
*/
private static void test5(FileSystem fileSystem, Path remotePath){
try {
RemoteIterator iterator = fileSystem.listFiles(remotePath,true);
while (iterator.hasNext()){
FileStatus status = iterator.next();
System.out.println(status.getPath());
System.out.println(status.getPermission());
System.out.println(status.getLen());
System.out.println(status.getModificationTime());
}
} catch (IOException e) {
e.printStackTrace();
}
} 6. 提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录。
hadoop fs -touchz /test/test.txt
hadoop fs -mkdir /test
hadoop fs -rm -R /test/text.txt /**
* @param fileSystem
* @param remoteDirPath 目标文件夹地址
* @param remoteFilePath 目标文件路径
*/
private static void test6(FileSystem fileSystem, Path remoteDirPath, Path remoteFilePath){
try {
if (fileSystem.exists(remoteDirPath)){
System.out.println("Please choose your option: 1.create. 2.delete");
int i = new Scanner(System.in).nextInt();
switch (i){
case 1:
fileSystem.create(remoteFilePath);
break;
case 2:
fileSystem.delete(remoteDirPath,true);
break;
}
}else {
fileSystem.mkdirs(remoteDirPath);
}
} catch (IOException e) {
e.printStackTrace();
}
}7. 提供一个 HDFS 的文件的路径,对该文件进行创建和删除操作。创建目录时,如果该目录文件所在目录不存在则自动创建相应目录;删除目录时,由用户指定该目录不为空时是否还删除该目录。
hadoop fs -touchz /test/test.txt
hadoop fs -mkdir /test
hadoop fs -rm -R /test/text.txt /**
* @param fileSystem
* @param remotePath 目标文件夹地址
*/
private static void test7(FileSystem fileSystem, Path remotePath){
try {
if (!fileSystem.exists(remotePath)){
System.out.println("Can't find this path, the path will be created automatically");
fileSystem.mkdirs(remotePath);
return;
}
System.out.println("Do you want to delete this dir? ( y / n )");
if (new Scanner(System.in).next().equals("y")){
FileStatus[] iterator = fileSystem.listStatus(remotePath);
if (iterator.length != 0){
System.out.println("There are some files in this dictionary, do you sure to delete all? (y / n)");
if (new Scanner(System.in).next().equals("y")){
if (fileSystem.delete(remotePath,true)){
System.out.println("Delete successful");
return;
}
}
}
if (fileSystem.delete(remotePath,true)){
System.out.println("Delete successful");
}
}
} catch (IOException e) {
e.printStackTrace();
}
}8. 向 HDFS 中指定的文件追加内容,由用户指定追加到原有文件的开头或结尾
hadoop fs -get text.txt
cat text.txt >> local.txt
hadoop fs -copyFromLocal -f text.txt text.txt /**
* @param fileSystem
* @param remotePath HDFS 中文件到路径
* @param localPath 本地文件路径
*/
private static void test8(FileSystem fileSystem,Path remotePath, Path localPath){
try {
if (!fileSystem.exists(remotePath)){
System.out.println("Can't find this file");
return;
}
System.out.println("input 1 or 2 , add the content to the remote file's start or end");
switch (new Scanner(System.in).nextInt()){
case 1:
fileSystem.moveToLocalFile(remotePath, localPath);
FSDataOutputStream fsDataOutputStream = fileSystem.create(remotePath);
FileInputStream fileInputStream = new FileInputStream("/Users/binguner/IdeaProjects/HadoopDemo/src/test2.txt");
FileInputStream fileInputStream1 = new FileInputStream("/Users/binguner/IdeaProjects/HadoopDemo/src/test.txt");
byte[] bytes = new byte[1024];
int read = -1;
while ((read = fileInputStream.read(bytes)) > 0) {
fsDataOutputStream.write(bytes,0,read);
}
while ((read = fileInputStream1.read(bytes)) > 0){
fsDataOutputStream.write(bytes,0,read);
}
fileInputStream.close();
fileInputStream1.close();
fsDataOutputStream.close();
break;
case 2:
FileInputStream inputStream = new FileInputStream("/Users/binguner/IdeaProjects/HadoopDemo/"+localPath.toString());
FSDataOutputStream outputStream = fileSystem.append(remotePath);
byte[] bytes1 = new byte[1024];
int read1 = -1;
while ((read1 = inputStream.read(bytes1)) > 0){
outputStream.write(bytes1,0,read1);
}
inputStream.close();
outputStream.close();
break;
}
} catch (IOException e) {
e.printStackTrace();
}
}9. 删除 HDFS 中指定的文件。
hadoop fs -rm -R /test/test.txt private static void test9(FileSystem fileSystem,Path remotePath){
try {
if(fileSystem.delete(remotePath,true)){
System.out.println("Delete success");
}else {
System.out.println("Delete failed");
}
} catch (IOException e) {
e.printStackTrace();
}
}10. 在 HDFS 中将文件从源路径移动到目的路径。
hadoop fs -mv /test/test.txt /test2 /**
* @param fileSystem
* @param oldRemotePath old name
* @param newRemotePath new name
*/
private static void test10(FileSystem fileSystem, Path oldRemotePath, Path newRemotePath){
try {
if (fileSystem.rename(oldRemotePath,newRemotePath)){
System.out.println("Rename success");
}else {
System.out.println("Rename failed");
}
} catch (IOException e) {
e.printStackTrace();
}
}三、利用Java API与HDFS进行交互
(一) 在Ubuntu中安装Eclipse/idea
1. 在Eclipse中创建项目
2. 为项目添加需要用到的JAR包
为了编写一个能够与HDFS交互的Java应用程序,一般需要向Java工程中添加以下JAR包:
(1)“/usr/local/hadoop/share/hadoop/common”目录下的所有JAR包,包括hadoop-common-3.1.3.jar、hadoop-common-3.1.3-tests.jar、haoop-nfs-3.1.3.jar和haoop-kms-3.1.3.jar,注意,不包括目录jdiff、lib、sources和webapps;
(2)“/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/usr/local/hadoop/share/hadoop/hdfs”目录下的所有JAR包,注意,不包括目录jdiff、lib、sources和webapps;
(4)“/usr/local/hadoop/share/hadoop/hdfs/lib”目录下的所有JAR包。
3. 1.编写Java应用程序
例如任务:现在要执行的任务是:假设在目录“hdfs://localhost:9000/user/hadoop”下面有几个文件,分别是file1.txt、file2.txt、file3.txt、file4.abc和file5.abc,
这里需要从该目录中过滤出所有后缀名不为“.abc”的文件,对过滤之后的文件进行读取,并将这些文件的内容合并到文件“hdfs://localhost:9000/user/hadoop/merge.txt”中。
■ 准备工作:HDFS的“/user/hadoop”目录下已经存在file1.txt、file2.txt、file3.txt、file4.abc和file5.abc,每个文件里面有内容。这里,假设文件内容如下:
file1.txt的内容是: this is file1.txt
file2.txt的内容是: this is file2.txt
file3.txt的内容是: this is file3.txt
file4.abc的内容是: this is file4.abc
file5.abc的内容是: this is file5.abc
import java.io.IOException;
import java.io.PrintStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
/**
* 过滤掉文件名满足特定条件的文件
*/
class MyPathFilter implements PathFilter {
String reg = null;
MyPathFilter(String reg) {
this.reg = reg;
}
public boolean accept(Path path) {
if (!(path.toString().matches(reg)))
return true;
return false;
}
}
/***
* 利用FSDataOutputStream和FSDataInputStream合并HDFS中的文件
*/
public class MergeFile {
Path inputPath = null; //待合并的文件所在的目录的路径
Path outputPath = null; //输出文件的路径
public MergeFile(String input, String output) {
this.inputPath = new Path(input);
this.outputPath = new Path(output);
}
public void doMerge() throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fsSource = FileSystem.get(URI.create(inputPath.toString()), conf);
FileSystem fsDst = FileSystem.get(URI.create(outputPath.toString()), conf);
//下面过滤掉输入目录中后缀为.abc的文件
FileStatus[] sourceStatus = fsSource.listStatus(inputPath,
new MyPathFilter(".*\\.abc"));
FSDataOutputStream fsdos = fsDst.create(outputPath);
PrintStream ps = new PrintStream(System.out);
//下面分别读取过滤之后的每个文件的内容,并输出到同一个文件中
for (FileStatus sta : sourceStatus) {
//下面打印后缀不为.abc的文件的路径、文件大小
System.out.print("路径:" + sta.getPath() + " 文件大小:" + sta.getLen()
+ " 权限:" + sta.getPermission() + " 内容:");
FSDataInputStream fsdis = fsSource.open(sta.getPath());
byte[] data = new byte[1024];
int read = -1;
while ((read = fsdis.read(data)) > 0) {
ps.write(data, 0, read);
fsdos.write(data, 0, read);
}
fsdis.close();
}
ps.close();
fsdos.close();
}
public static void main(String[] args) throws IOException {
MergeFile merge = new MergeFile(
"hdfs://localhost:9000/user/hadoop/",
"hdfs://localhost:9000/user/hadoop/merge.txt");
merge.doMerge();
}
}3. 2.编写Java应用程序
例如任务:现在要执行的任务是:编程实现一个类"MyFSDataInputStream",该类继承"org.apache.hadoop.fs.FSDataInputStream",要求如下:实现按行读取 HDFS 中指定文件的方法"readLine()",如果读到文件末尾,则返回空,否则返回文件一行的文本。同时实现缓存功能,即用“MyFSDataInputStream” 读取若干字节数据时,首先查找缓存,若缓存中有所需的数据,则直接由缓存提供,否则从HDFS中读取数据。
参考HDFS 读取数据:
import java.io.BufferedReader;
import java.io.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FSDataInputStream;
public class Chapter3 {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
Path file = new Path("test");
FSDataInputStream getIt = fs.open(file);
BufferedReader d = new BufferedReader(new InputStreamReader(getIt));
String content = d.readLine(); //读取文件一行
System.out.println(content);
d.close(); //关闭文件
fs.close(); //关闭hdfs
} catch (Exception e) {
e.printStackTrace();
}
}
}正解:
package Second;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class MyFsDataInputStream extends FSDataInputStream{
public MyFsDataInputStream(InputStream in) {
super(in);
}
public static String readline(Configuration conf,String filename) throws IOException
{
Path filename1=new Path(filename);
FileSystem fs=FileSystem.get(conf);
FSDataInputStream in=fs.open(filename1);
BufferedReader d=new BufferedReader(new InputStreamReader(in));
String line=d.readLine();
if (line!=null) {
d.close();
in.close();
return line;
}else
return null;
}
public static void main(String[] args) throws IOException {
Configuration conf=new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs=FileSystem.get(conf);
String filename="/user/hadoop/myLocalFile.txt";
System.out.println("读取文件:"+filename);
String o=MyFsDataInputStream.readline(conf, filename);
System.out.println(o+"\n"+"读取完成");
}
}3. 3.编写Java应用程序
例如任务:现在要执行的任务是:查看Java帮助手册或其它资料,用”java.net.URL”和“org.apache.hadoop.fs.FsURLStreamHandler
Factory”编程完成输出HDFS中指定文件的文本到终端中。
package Second;
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.io.IOUtils;
public class FSUrl {
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void cat(String filename) throws MalformedURLException, IOException
{
InputStream in=new URL("hdfs","localhost",9000,filename).openStream();
IOUtils.copyBytes(in, System.out,4096,false);
IOUtils.closeStream(in);
}
public static void main(String[] args) throws MalformedURLException, IOException {
String filename="/user/hadoop/myLocalFile.txt";
System.out.println("读取文件"+filename);
FSUrl.cat(filename+"\n读取完成");
}
}最后,其他问题可以参考文章:《参考大数据厦门大学林子雨编著的《大数据技术原理与应用(第3版)》中第三课《HDFS编程实践(Hadoop3.1.3)》遇到的bug》
本文参考文章:
《hdfs报错Command ‘hdfs‘ not found, did you mean》 hdfs报错Command ‘hdfs‘ not found, did you mean_码农阿益的博客-CSDN博客
《第三章 熟悉常用的HDFS操作》第三章 熟悉常用的HDFS操作 - 119林江绅 - 博客园
《熟悉常用的 HDFS 操作》熟悉常用的 HDFS 操作_拉格朗日的迷妹-CSDN博客_向hdfs中上传任意文本文件
《基于JAVA的HDFS文件操作》 基于JAVA的HDFS文件操作_missbearC的博客-CSDN博客
《HDFS编程实践(Hadoop3.1.3)_厦大数据库实验室博客 (xmu.edu.cn)》
《实验二 熟悉常用的 HDFS 操作》实验二 熟悉常用的 HDFS 操作 - 程序员大本营