七、图像分类模型的部署(Datawhale组队学习)
文章目录
- 前言
-
- ONNX简介
- 应用场景
- 部署ImageNet预训练图像分类模型
-
- 导出ONNX模型
- 推理引擎ONNX Runtime部署-预测单张图像
-
- 前期准备
- ONNX Runtime预测
- 推理引擎ONNX Runtime部署-ImageNet预训练图像分类模型预测摄像头实时画面
-
- 前期准备
- 预测摄像头的一帧画面
- 预测摄像头实时画面
- 部署自己训练的图像分类模型
-
- 导出ONNX模型
- 推理引擎ONNX Runtime部署-预测单张图像
-
- ONNX Runtime预测
- 解析预测结果
- 总结
本文内容为 同济子豪兄图像分类系列视频的学习笔记, 项目参考代码。本文使用ONNX-ONNX Runtime部署我们的模型。

前言
ONNX简介
ONNX是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。它使得不同的人工智能框架(如Pytorch, TensorFlow等)可以采用相同格式存储模型数据并交互。
应用场景
后面的代码在需要部署的硬件上运行,只需把onnx模型文件发到部署硬件上,并安装 ONNX Runtime 环境,用几行代码就可以运行模型了。
pip install onnx onnxruntime
部署ImageNet预训练图像分类模型
导出ONNX模型
import torch
from torchvision import models
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device', device)
载入ImageNet预训练图像分类模型
model = models.resnet18(pretrained=True)
model = model.eval().to(device)
Pytorch模型转ONNX模型
x = torch.randn(1, 3, 256, 256).to(device)
with torch.no_grad():
torch.onnx.export(
model, # 要转换的模型
x, # 模型的任意一组输入
'resnet18.onnx', # 导出的 ONNX 文件名
opset_version=11, # ONNX 算子集版本
input_names=['input'], # 输入 Tensor 的名称(自己起名字)
output_names=['output'] # 输出 Tensor 的名称(自己起名字)
)
验证onnx模型导出成功
import onnx
# 读取 ONNX 模型
onnx_model = onnx.load('resnet18.onnx')
# 检查模型格式是否正确
onnx.checker.check_model(onnx_model)
print('无报错,onnx模型载入成功')
#以可读形式打印计算图
#print(onnx.helper.printable_graph(onnx_model.graph))
无报错,onnx模型载入成功
使用Netron对onnx模型可视化
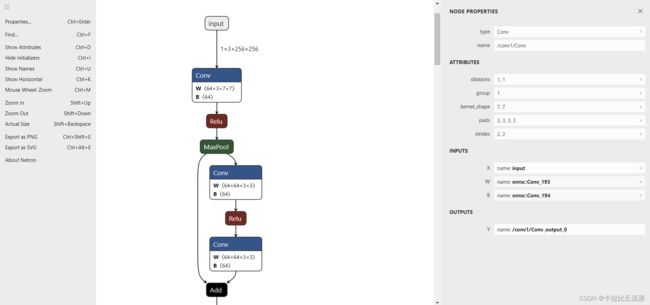
关于如何理解这个网络我们可以参考子豪兄的【精读AI论文】ResNet深度残差网络,一下为ResNet网络的简要介绍。

Resnet将一个模块的输入分为两条路。右边这条路称为短路连接,这个连接将输入原封不动的传入到输出。左边的这条路是两层的神经网络,这两层神经网络不用拟合复杂的底层映射,只用你和原来输入的基础上进行的偏移和修改(即残差)就可以了。最后将残差和恒等映射相加再用Relu激活函数处理。
推理引擎ONNX Runtime部署-预测单张图像
使用推理引擎 ONNX Runtime,读取 onnx 格式的模型文件,对单张图像文件进行预测。
import onnxruntime
import numpy as np
import torch
前期准备
载入 onnx 模型,获取 ONNX Runtime 推理器
ort_session = onnxruntime.InferenceSession('resnet18.onnx')
预处理
from torchvision import transforms
# 测试集图像预处理-RCTN:缩放裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
载入测试图像并进行预处理
img_path = 'banana1.jpg'
# 用 pillow 载入
from PIL import Image
img_pil = Image.open(img_path)
img_pil
input_img = test_transform(img_pil)
input_tensor = input_img.unsqueeze(0).numpy()
input_tensor.shape
(1, 3, 256, 256)
ONNX Runtime预测
注意,输入输出张量的名称需要和 torch.onnx.export 中设置的输入输出名对应
# ONNX Runtime 输入
ort_inputs = {'input': input_tensor}
# ONNX Runtime 输出
pred_logits = ort_session.run(['output'], ort_inputs)[0]
pred_logits = torch.tensor(pred_logits)
import torch.nn.functional as F
pred_softmax = F.softmax(pred_logits, dim=1) # 对 logit 分数做 softmax 运算
pred_softmax.shape
torch.Size([1, 1000])
对预测结果进行柱状图可视化
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(8,4))
x = range(1000)
y = pred_softmax.cpu().detach().numpy()[0]
ax = plt.bar(x, y, alpha=0.5, width=0.3, color='yellow', edgecolor='red', lw=3)
plt.ylim([0, 1.0]) # y轴取值范围
# plt.bar_label(ax, fmt='%.2f', fontsize=15) # 置信度数值
plt.xlabel('Class', fontsize=20)
plt.ylabel('Confidence', fontsize=20)
plt.tick_params(labelsize=16) # 坐标文字大小
plt.title(img_path, fontsize=25)
plt.show()

推理引擎ONNX Runtime部署-ImageNet预训练图像分类模型预测摄像头实时画面
前期准备
#导入包
import onnxruntime
import torch
import pandas as pd
import numpy as np
from PIL import Image, ImageFont, ImageDraw
import matplotlib.pyplot as plt
%matplotlib inline
import os
import numpy as np
import pandas as pd
import cv2 # opencv-python
from tqdm import tqdm # 进度条
import matplotlib.pyplot as plt
%matplotlib inline
import torch
import torch.nn.functional as F
from torchvision import models
# 导入中文字体,指定字号
font = ImageFont.truetype('SimHei.ttf', 32)
# 载入 onnx 模型,获取 ONNX Runtime 推理器
ort_session = onnxruntime.InferenceSession('resnet18.onnx')
# 载入ImageNet 1000图像分类标签
df = pd.read_csv('imagenet_class_index.csv')
idx_to_labels = {}
for idx, row in df.iterrows():
idx_to_labels[row['ID']] = row['Chinese']
# 测试集图像预处理-RCTN:缩放裁剪、转 Tensor、归一化
from torchvision import transforms
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
预测摄像头的一帧画面
获取摄像头的一帧画面
# 导入opencv-python
import cv2
import time
# 获取摄像头,传入0表示获取系统默认摄像头
cap = cv2.VideoCapture(1)
# 打开cap
cap.open(0)
time.sleep(1)
success, img_bgr = cap.read()
# 关闭摄像头
cap.release()
# 关闭图像窗口
cv2.destroyAllWindows()
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB) # BGR转RGB
img_pil = Image.fromarray(img_rgb)
img_pil

使用onnx runtime进行预测
# 预处理
input_img = test_transform(img_pil)
input_tensor = input_img.unsqueeze(0).numpy()
# onnx runtime 预测
# onnx runtime 输入
ort_inputs = {'input': input_tensor}
# onnx runtime 输出
pred_logits = ort_session.run(['output'], ort_inputs)[0]
pred_logits = torch.tensor(pred_logits)
import torch.nn.functional as F
pred_softmax = F.softmax(pred_logits, dim=1) # 对 logit 分数做 softmax 运算
## 解析图像分类预测结果
n = 5
top_n = torch.topk(pred_softmax, n) # 取置信度最大的 n 个结果
pred_ids = top_n[1].cpu().detach().numpy().squeeze() # 解析出类别
confs = top_n[0].cpu().detach().numpy().squeeze() # 解析出置信度
draw = ImageDraw.Draw(img_pil)
# 在图像上写字
for i in range(len(confs)):
pred_class = idx_to_labels[pred_ids[i]]
text = '{:<15} {:>.3f}'.format(pred_class, confs[i])
# 文字坐标,中文字符串,字体,rgba颜色
draw.text((50, 100 + 50 * i), text, font=font, fill=(255, 0, 0, 1))
img = np.array(img_pil) # PIL 转 array
plt.imshow(img)
plt.show()

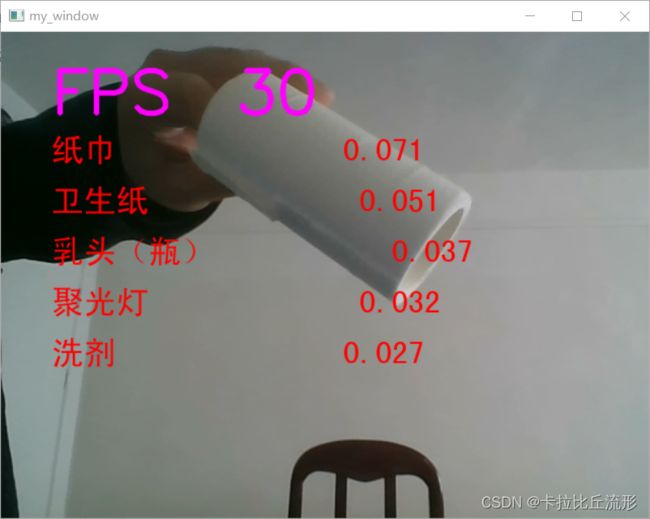
预测摄像头实时画面
处理单帧画面的函数(中文)
# 处理帧函数
def process_frame(img):
# 记录该帧开始处理的时间
start_time = time.time()
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # BGR转RGB
img_pil = Image.fromarray(img_rgb) # array 转 PIL
## 预处理
input_img = test_transform(img_pil) # 预处理
input_tensor = input_img.unsqueeze(0).numpy()
## onnx runtime 预测
ort_inputs = {'input': input_tensor} # onnx runtime 输入
pred_logits = ort_session.run(['output'], ort_inputs)[0] # onnx runtime 输出
pred_logits = torch.tensor(pred_logits)
pred_softmax = F.softmax(pred_logits, dim=1) # 对 logit 分数做 softmax 运算
## 解析图像分类预测结果
n = 5
top_n = torch.topk(pred_softmax, n) # 取置信度最大的 n 个结果
pred_ids = top_n[1].cpu().detach().numpy().squeeze() # 解析出类别
confs = top_n[0].cpu().detach().numpy().squeeze() # 解析出置信度
draw = ImageDraw.Draw(img_pil)
# 在图像上写字
for i in range(len(confs)):
pred_class = idx_to_labels[pred_ids[i]]
text = '{:<15} {:>.3f}'.format(pred_class, confs[i])
# 文字坐标,中文字符串,字体,rgba颜色
draw.text((50, 100 + 50 * i), text, font=font, fill=(255, 0, 0, 1))
img = np.array(img_pil) # PIL 转 array
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR) # RGB转BGR
# 记录该帧处理完毕的时间
end_time = time.time()
# 计算每秒处理图像帧数FPS
FPS = 1/(end_time - start_time)
# 图片,添加的文字,左上角坐标,字体,字体大小,颜色,线宽,线型
img = cv2.putText(img, 'FPS '+str(int(FPS)), (50, 80), cv2.FONT_HERSHEY_SIMPLEX, 2, (255, 0, 255), 4, cv2.LINE_AA)
return img
调用摄像头获取每帧
# 调用摄像头逐帧实时处理模板
# 不需修改任何代码,只需修改process_frame函数即可
# 导入opencv-python
import cv2
import time
# 获取摄像头,传入0表示获取系统默认摄像头
cap = cv2.VideoCapture(1)
# 打开cap
cap.open(0)
# 无限循环,直到break被触发
while cap.isOpened():
# 获取画面
success, frame = cap.read()
if not success:
print('Error')
break
## !!!处理帧函数
frame = process_frame(frame)
# 展示处理后的三通道图像
cv2.imshow('my_window',frame)
if cv2.waitKey(1) in [ord('q'),27]: # 按键盘上的q或esc退出(在英文输入法下)
break
# 关闭摄像头
cap.release()
# 关闭图像窗口
cv2.destroyAllWindows()
部署自己训练的图像分类模型
基本流程和上一小节是一样的,我们这里仅展示运用推理引擎ONNX Runtime部署自己训练的水果图像分类模型并预测单张图像。
导出ONNX模型
import torch
from torchvision import models
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device', device)
# 导入训练好的模型
model = torch.load('checkpoints/fruit30_pytorch_20230123.pth')
model = model.eval().to(device)
Pytorch模型转ONNX模型
x = torch.randn(1, 3, 256, 256).to(device)
with torch.no_grad():
torch.onnx.export(
model, # 要转换的模型
x, # 模型的任意一组输入
'fruit30_resnet18.onnx', # 导出的 ONNX 文件名
opset_version=11, # ONNX 算子集版本
input_names=['input'], # 输入 Tensor 的名称(自己起名字)
output_names=['output'] # 输出 Tensor 的名称(自己起名字)
)
验证onnx模型导出成功
import onnx
# 读取 ONNX 模型
onnx_model = onnx.load('fruit30_resnet18.onnx')
# 检查模型格式是否正确
onnx.checker.check_model(onnx_model)
print('无报错,onnx模型载入成功')
#以可读的形式打印计算图
#print(onnx.helper.printable_graph(onnx_model.graph))
无报错,onnx模型载入成功
和上一小节一样也可以使用Netron对onnx模型可视化
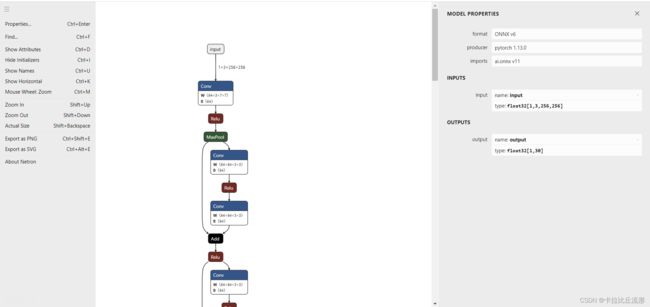
推理引擎ONNX Runtime部署-预测单张图像
import onnxruntime
import numpy as np
import torch
载入 onnx 模型,获取 ONNX Runtime 推理器
ort_session = onnxruntime.InferenceSession('fruit30_resnet18.onnx')
预处理
from torchvision import transforms
# 测试集图像预处理-RCTN:缩放裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
img_path = 'test_img/watermelon1.jpg'
# 用 pillow 载入
from PIL import Image
img_pil = Image.open(img_path)
img_pil
input_img = test_transform(img_pil)
input_tensor = input_img.unsqueeze(0).numpy()
input_tensor.shape
(1, 3, 256, 256)
ONNX Runtime预测
注意,输入输出张量的名称需要和 torch.onnx.export 中设置的输入输出名对应
# ONNX Runtime 输入
ort_inputs = {'input': input_tensor}
# ONNX Runtime 输出
pred_logits = ort_session.run(['output'], ort_inputs)[0]
pred_logits = torch.tensor(pred_logits)
import torch.nn.functional as F
pred_softmax = F.softmax(pred_logits, dim=1) # 对 logit 分数做 softmax 运算
pred_softmax.shape
torch.Size([1, 30])
解析预测结果
#设置matplotlib中文字体
# windows操作系统
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
#载入类别和对应 ID
idx_to_labels = np.load('idx_to_labels.npy', allow_pickle=True).item()
绘制预测结果柱状图
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(22, 10))
x = idx_to_labels.values()
y = pred_softmax.cpu().detach().numpy()[0] * 100
width = 0.45 # 柱状图宽度
ax = plt.bar(x, y, width)
plt.bar_label(ax, fmt='%.2f', fontsize=15) # 置信度数值
plt.tick_params(labelsize=20) # 设置坐标文字大小
plt.title(img_path, fontsize=30)
plt.xticks(rotation=45) # 横轴文字旋转
plt.xlabel('类别', fontsize=20)
plt.ylabel('置信度', fontsize=20)
plt.show()

总结
本文主要讲述了ONNX-ONNX Runtime部署流程,首先将训练好的Pytorch模型转ONNX模型,这样我们就可以将ONNX模型在任何安装了ONNX Runtime环境的机器上进行运行,进行单张图片的预测、调用摄像头进行实时画面的预测等。使用ONNX我们可以让模型在不同框架之间进行迁移,方便我们低成本的将模型部署到移动设备中去。