条件生成对抗网络(CGAN)基于pytorch在minist数据集上的实现
目录
1、概述
2、代码和网络训练说明
2.1、代码链接
2.2、网络训练
3、代码说明
3.1、生成器和判别器模型文件(model.py)
3.2、基本参数(base_parameters.py)
3.3、数据集加载(data_loader.py)
3.4、训练代码(train.py)
3.5、推理代码(prediction.py)
1、概述
条件生成对抗网络(Conditional Generative Adversarial Nets),通过对生成器和判别器输入额外的条件标签信息来对网络进行训练。最终,训练完成后的生成器能够根据带有条件标签信息的输入生成你想要的图片。以minist手写字为例,训练完成后,可以对生成器输入你想要生成器生成的手写数字标签,而生成器就可以生成你想要的数字图片,如下图所示,为生成器生成的手写字图片。
 生成器生成的手写字图片
生成器生成的手写字图片
2、代码和网络训练说明
2.1、代码链接
github仓库
gitee仓库
2.2、网络训练
训练图示如下:
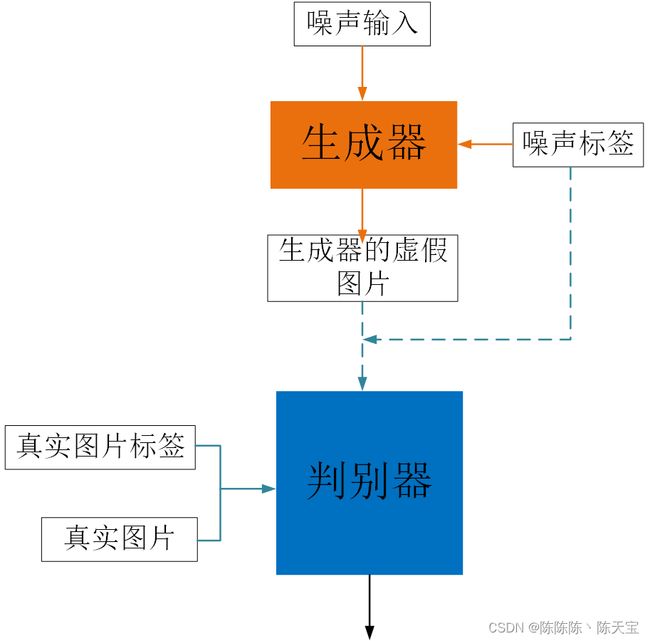
3、代码说明
3.1、生成器和判别器模型文件(model.py)
"""
定义生成器模型和判别器模型
"""
import numpy as np
import torch.nn as nn
import torch
# 生成器模型
class Generator(nn.Module):
def __init__(self, input_dim, n_classes, img_shape):
"""
:param input_dim: 干扰数据的长度
:param n_classes: 数据集包含的目标种类
:param img_shape: 想要生成的图片的尺寸(与判别器输入的图像尺寸保持一致)
"""
super(Generator, self).__init__()
self.input_dim = input_dim
self.n_classes = n_classes
self.img_shape = img_shape
self.label_emb = nn.Embedding(self.n_classes, self.n_classes)
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn
.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(self.input_dim + self.n_classes, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(self.img_shape))),
nn.Tanh()
)
def forward(self, noise, labels):
# 连接标签嵌入和图像以产生输入
gen_input = torch.cat((self.label_emb(labels), noise), -1)
img = self.model(gen_input)
img = img.view(img.size(0), *(self.img_shape))
return img
# 判别器模型
class Discriminator(nn.Module):
def __init__(self, n_classes, img_shape):
"""
:param n_classes: 数据集包含的目标种类
:param img_shape: 输入图片的尺寸
"""
super(Discriminator, self).__init__()
self.n_classes = n_classes
self.img_shape = img_shape
self.label_embedding = nn.Embedding(self.n_classes, self.n_classes)
self.model = nn.Sequential(
nn.Linear(self.n_classes + int(np.prod(self.img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.Dropout(0.4),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.Dropout(0.4),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 1),
)
def forward(self, img, labels):
# 连接标签嵌入和图像以产生输入
d_in = torch.cat((img.view(img.size(0), -1), self.label_embedding(labels)), -1)
validity = self.model(d_in)
return validity
if __name__ == "__main__":
# 定义一些变量
input_dim = 100 # 干扰输入
class_nummber = 10 # 数据集类别数
img_size = [1, 32, 32] # 图像形状
# 创建判别器
d_model = Discriminator(n_classes=class_nummber, img_shape= img_size)
# 打印判别模型
print(d_model.model)
print('\n')
# 创建生成器
g_model = Generator(input_dim=input_dim, n_classes=class_nummber, img_shape=img_size)
# 打生成模型
print(g_model.model)
print('\n')3.2、基本参数(base_parameters.py)
"""
设置的默认参数
"""
import argparse
def base_parameters():
"""
:return: 默认参数
"""
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=4, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--n_classes", type=int, default=10, help="number of classes for dataset")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="图像采样间隔")
parser.add_argument("--input_shape", type=tuple, default=(1, 32, 32), help="输入图像的尺寸")
parser.add_argument("--input_dim", type=int, default=100, help="生成器输出参数的长度")
parser.add_argument("--class_nummber", type=int, default=10, help="数据集中的类别数")
opt = parser.parse_args()
return 3.3、数据集加载(data_loader.py)
"""
数据集加载
"""
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision import datasets
import torch
def data_load(batch_size, img_size):
"""
数据加载\n
:batch_size: 批量大小
:img_size: 图片大小
:return: 数据集迭代器
"""
return torch.utils.data.DataLoader(
datasets.MNIST(
"data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=batch_size,
shuffle=True,)
if __name__ == "__main__":
data_loader = data_load(256, 32)
for i, (imgs, labels) in enumerate(data_loader):
print(f"i = {i}\n imgs.shape = {imgs.shape}\n labels = {labels}\n")
if i == 0:
break3.4、训练代码(train.py)
"""
网络的训练
"""
import os
from data_loader import data_load
from model import Generator, Discriminator
from base_parameters import base_parameters
from torch.autograd import Variable
import numpy as np
from torchvision.utils import save_image
import torch
# 创建文件夹,没有才创建。有的话就有吧
os.makedirs("images", exist_ok=True)
os.makedirs("saved_models", exist_ok=True)
# 是否使用GUP
cuda = True if torch.cuda.is_available() else False
# 导入参数
opt = base_parameters()
# 损失函数
adversarial_loss = torch.nn.MSELoss()
# 初始化生成器和判别器
generator = Generator(input_dim=opt.input_dim, n_classes=opt.n_classes, img_shape=opt.input_shape) # 生成器
discriminator = Discriminator(n_classes=opt.n_classes, img_shape=opt.input_shape) # 判别器
# 如果GPU可用的话
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if cuda else torch.LongTensor
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# 加载数据
dataloader = data_load(batch_size=opt.batch_size, img_size=opt.img_size)
# 优化器
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
# 模型训练
for epoch in range(opt.n_epochs):
for i, (imgs, labels) in enumerate(dataloader):
batch_size = imgs.shape[0]
# 对抗器的真实标签
valid = Variable(FloatTensor(batch_size, 1).fill_(1.0), requires_grad=False)
fake = Variable(FloatTensor(batch_size, 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(FloatTensor))
labels = Variable(labels.type(LongTensor))
# 训练生成器
optimizer_G.zero_grad()
# 噪声样本和对应的标签
z = Variable(FloatTensor(np.random.normal(0, 1, (batch_size, opt.latent_dim)))) # 噪声样本
gen_labels = Variable(LongTensor(np.random.randint(0, opt.n_classes, batch_size))) # 对应的标签
# 利用噪声样本和标签生成一系列的图片 ----> 该图片由生成器生成
gen_imgs = generator(z, gen_labels) # 生成器利用噪声和对应的标签生成
# Loss measures generator's ability to fool the discriminator # 利用判别器计算生成器生成的图片与图片对应标签的损失。
# 生成器的目的就是根据标签和干扰生成对应的标签图片,
# 假设判别器市准的,则目的就是希望其与真实标签1的损失最小
validity = discriminator(gen_imgs, gen_labels)
g_loss = adversarial_loss(validity, valid)
g_loss.backward()
optimizer_G.step()
# 训练判别器
optimizer_D.zero_grad()
# Loss for real images 真实图片的损失,目的就是希望其与真实标签1的损失最小
validity_real = discriminator(real_imgs, labels)
d_real_loss = adversarial_loss(validity_real, valid)
# Loss for fake images 生成的虚假图片的损失,目的就是希望其与虚假标签0的损失最小
validity_fake = discriminator(gen_imgs.detach(), gen_labels)
d_fake_loss = adversarial_loss(validity_fake, fake)
# Total discriminator loss 判别器的总的损失,真实图片与虚假图片各取一般
d_loss = (d_real_loss + d_fake_loss) / 2
d_loss.backward()
optimizer_D.step()
# 打印每个step后的损失结果
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
# 统计总共训练的step,每经过opt.sample_interval个step就利用当前的生成器参数进行随机生成并保存结果
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
# 随机生成100个图片并显示
z = Variable(FloatTensor(np.random.normal(0, 1, (10 ** 2, opt.latent_dim))))
# Get labels ranging from 0 to n_classes for n rows
labels = np.array([num for _ in range(10) for num in range(10)])
labels = Variable(LongTensor(labels))
gen_imgs = generator(z, labels)
save_image(gen_imgs.data, "images/%d.png" % batches_done, nrow=10, normalize=True)
# 保存最近一次epoch的网络权重模型到指定路径下
torch.save(generator.state_dict(), "saved_models/generator_best.pth")运行train,py开始训练,会保存最近一次的网络权重参数到saved_models/generator_best.pth,需要的环境和python包在readme中可见。每经过800个step的训练,会用当前的生成器参数生成0-9的手写字图片各10张,并保存,随着训练的进行,可以看到生成的图片的确与输入的标签越来越接近。
3.5、推理代码(prediction.py)
"""
网络的推理
"""
import matplotlib.pyplot as plt
from data_loader import data_load
from model import Generator
from base_parameters import base_parameters
from torch.autograd import Variable
import numpy as np
from PIL import Image
import torch
from torchvision import transforms
import time
unloader = transforms.ToPILImage()
# 生成的数量
batch_g = 2
# 预训练权重参数路径 根据自己的与训练权利权重路径进行填写
pretraining_weight_path = 'saved_models/generator_best.pth'
# 是否使用GUP
cuda = True if torch.cuda.is_available() else False
# 导入参数
opt = base_parameters()
opt.prediction_batch = batch_g
# 加载数据
dataloader = data_load(batch_size=opt.batch_size, img_size=opt.img_size)
# 初始化生成器
generator = Generator(input_dim=opt.input_dim, n_classes=opt.n_classes, img_shape=opt.input_shape) # 生成器
# 导入预训练权重
generator.load_state_dict(torch.load(pretraining_weight_path))
# 如果GPU可用的话
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if cuda else torch.LongTensor
# 噪声样本和对应的标签
z = Variable(FloatTensor(np.random.normal(0, 1, (opt.prediction_batch, opt.latent_dim)))) # 噪声样本
gen_labels = Variable(LongTensor(np.random.randint(0, opt.n_classes, opt.prediction_batch))) # 对应的标签
# print(f'想要生成的数据标签:{gen_labels}, {gen_labels.shape}')
# print(f'噪声样本:{z}, {z.shape}')
# 模型预测
if cuda:
generator.cuda()
generator.eval()
with torch.no_grad():
gen_imgs = generator(z, gen_labels) # 生成器利用噪声和对应的标签生成
# 结果保存
for i in range(gen_imgs.shape[0]):
img = gen_imgs[i]
lable = gen_labels[i].cpu().numpy()
# print(img.shape)
name = str(time.time()) + "_lable[" + str(lable) + "].jpg"
image = img.cpu().clone() # clone the tensor
image = unloader(image)
image.save(name)