分布式架构图解
一、分布式架构图解
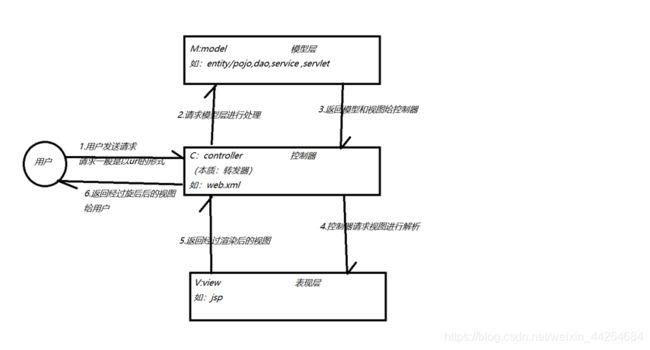
1)传统servlet+jsp模式
2)分布式架构
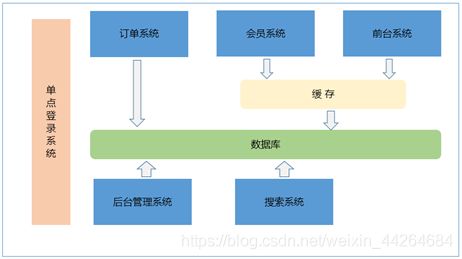
需要按照功能点把系统拆分,拆分成独立的功能。单独为某一个节点添加服务器。需要系统之间配合才能完成整个业务逻辑。叫做分布式。
分布式架构:多个子系统相互协作才能完成业务流程。系统之间需要进行通信。
集群:同一个工程部署到多台服务器上。
分布式架构:把系统按照模块拆分成多个子系统。
优点:
1.把模块拆分,使用接口通信,降低模块之间的耦合度。
2.把项目拆分成若干个子项目,不同的团队负责不同的子项目。
3.增加功能时只需要再增加一个子项目,调用其他系统的接口就可以。
4.可以灵活的进行分布式部署。
缺点:
1、系统之间交互需要使用远程通信,接口开发增加工作量。
2、各个模块有一些通用的业务逻辑无法共用。
3)基于SOA架构
SOA:Service Oriented Architecture面向服务的架构。也就是把工程拆分成服务层、表现层两个工程。服务层中包含业务逻辑,只需要对外提供服务即可。表现层只需要处理和页面的交互,业务逻辑都是调用服务层的服务来实现。
二、架构演变
随着互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,亟需一个治理系统确保架构有条不紊的演进。
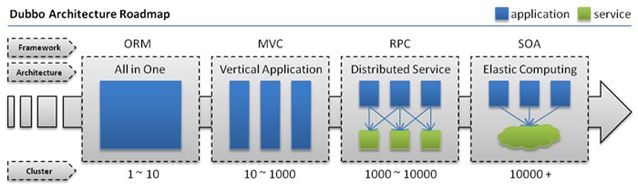
• 单一应用架构
• 当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。
• 此时,用于简化增删改查工作量的 数据访问框架(ORM) 是关键。
• 垂直应用架构
• 当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。
• 此时,用于加速前端页面开发的 Web框架(MVC) 是关键。
• 分布式服务架构
• 当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。
• 此时,用于提高业务复用及整合的 分布式服务框架(RPC) 是关键。
• 流动计算架构
• 当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。
• 此时,用于提高机器利用率的 资源调度和治理中心(SOA) 是关键。
三、Dubbo
Dubbo就是资源调度和治理中心的管理工具。
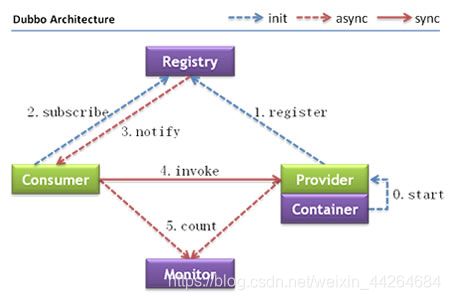
节点角色说明:
Provider: 暴露服务的服务提供方。---------------------------------------对应Service层
Consumer: 调用远程服务的服务消费方。------------------------------对应Web层
Registry: 服务注册与发现的注册中心。---------------------------------Zookeeper
Monitor: 统计服务的调用次调和调用时间的监控中心。
Container: 服务运行容器。--------------------------------------------------Spring容器
调用关系说明:
0. 服务容器负责启动,加载,运行服务提供者。
- 服务提供者在启动时,向注册中心注册自己提供的服务。
- 服务消费者在启动时,向注册中心订阅自己所需的服务。
- 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
- 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
- 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
发布服务
四、Zookeeper
ZooKeeper是一个树形结构的目录服务,支持变更推送,因此非常适合作为Dubbo服务的注册中心。
基于ZooKeeper实现的注册中心节点结构示意图:
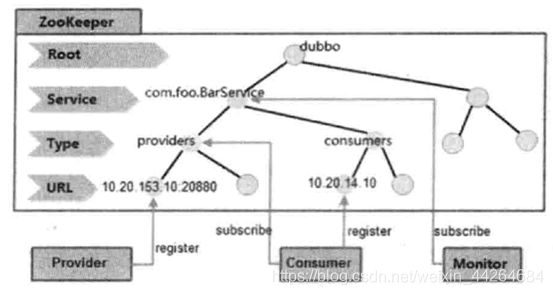
/dubbo:这是dubbo在ZooKeeper上创建的根节点;
/dubbo/com.foo.BarService:这是服务节点,代表了Dubbo的一个服务;
/dubbo/com.foo.BarService/providers:这是服务提供者的根节点,其子节点代表了每一个服务真正的提供者;
/dubbo/com.foo.BarService/consumers:这是服务消费者的根节点,其子节点代表每一个服务真正的消费者;
2.注册中心的工作流程
接下来以上述的BarService为例,说明注册中心的工作流程。
1)服务提供方启动
服务提供者在启动的时候,会在ZooKeeper上注册服务。所谓注册服务,其实就是在ZooKeeper的/dubbo/com.foo.BarService/providers节点下创建一个子节点,并写入自己的URL地址,这就代表了com.foo.BarService这个服务的一个提供者。
2)服务消费者启动
服务消费者在启动的时候,会向ZooKeeper注册中心订阅自己的服务。其实,就是读取并订阅ZooKeeper上/dubbo/com.foo.BarService/providers节点下的所有子节点,并解析出所有提供者的URL地址来作为该服务地址列表。
同时,服务消费者还会在ZooKeeper的/dubbo/com.foo.BarService/consumers节点下创建一个临时节点,并写入自己的URL地址,这就代表了com.foo.BarService这个服务的一个消费者。
3)消费者远程调用提供者
服务消费者,从提供者地址列表中,基于软负载均衡算法,选一个提供者进行调用,如果调用失败,再选另一个提供者调用。
4)增加服务提供者
增加提供者,也就是在providers下面新建子节点。一旦服务提供方有变动,zookeeper就会把最新的服务列表推送给消费者。
5)减少服务提供者
所有提供者在ZooKeeper上创建的节点都是临时节点,利用的是临时节点的生命周期和客户端会话相关的特性,因此一旦提供者所在的机器出现故障导致该提供者无法对外提供服务时,该临时节点就会自动从ZooKeeper上删除,同样,zookeeper会把最新的服务列表推送给消费者。
6)ZooKeeper宕机之后
消费者每次调用服务提供方是不经过ZooKeeper的,消费者只是从zookeeper那里获取服务提供方地址列表。所以当zookeeper宕机之后,不会影响消费者调用服务提供者,影响的是zookeeper宕机之后如果提供者有变动,增加或者减少,无法把最新的服务提供者地址列表推送给消费者,所以消费者感知不到。
五、spring父子容器简单概念
在Spring整体框架的核心概念中,容器是核心思想,就是用来管理Bean的整个生命周期的,而在一个项目中,容器不一定只有一个,Spring中可以包括多个容器,而且容器有上下层关系,目前最常见的一种场景就是在一个项目中引入Spring和SpringMVC这两个框架,那么它其实就是两个容器,Spring是父容器,SpringMVC是其子容器,并且在Spring父容器中注册的Bean对于SpringMVC容器中是可见的,而在SpringMVC容器中注册的Bean对于Spring父容器中是不可见的,也就是子容器可以看见父容器中的注册的Bean,反之就不行。
有的时候启动项目我们发现SpringMVC无法进行跳转,SpringMVC容器中的请求没有映射到具体controller中:Spring把所有带有@Controller注解的Bean都注册在Spring这个父容器中了,所以springMVC找不到处理器,不能进行跳转。springmvc是子容器,spring是父容器,但是检测controller时springmvc默认只会在自己容器中查找带有@Controller注解的bean,而不会去父容器中找,所以导致找不到
spring mvc servlet
springMvc
org.springframework.web.servlet.DispatcherServlet
配置spring mvc加载的配置文件(配置处理器映射器、适配器等等)
contextConfigLocation
classpath:spring/springmvc.xml
1
springMvc
*.html
六、FastDFS
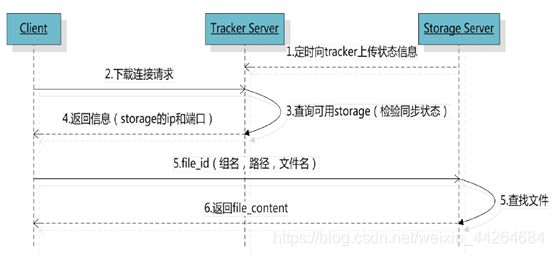
FastDFS架构包括 Tracker server和Storage server。客户端请求Tracker server进行文件上传、下载,通过Tracker server调度最终由Storage server完成文件上传和下载。
Tracker server作用是负载均衡和调度,通过Tracker server在文件上传时可以根据一些策略找到Storage server提供文件上传服务。可以将tracker称为追踪服务器或调度服务器。
Storage server作用是文件存储,客户端上传的文件最终存储在Storage服务器上,Storage server没有实现自己的文件系统而是利用操作系统 的文件系统来管理文件。可以将storage称为存储服务器。
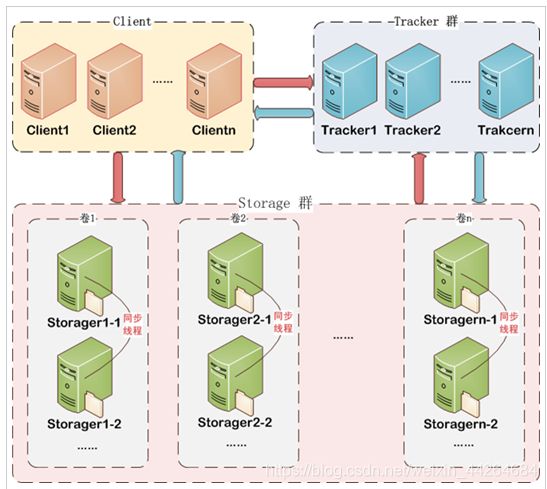
服务端两个角色:
Tracker:管理集群,tracker也可以实现集群。每个tracker节点地位平等。
收集Storage集群的状态。
Storage:实际保存文件
Storage分为多个组,每个组之间保存的文件是不同的。每个组内部可以有多个成员,组成员内部保存的内容是一样的,组成员的地位是一致的,没有主从的概念。
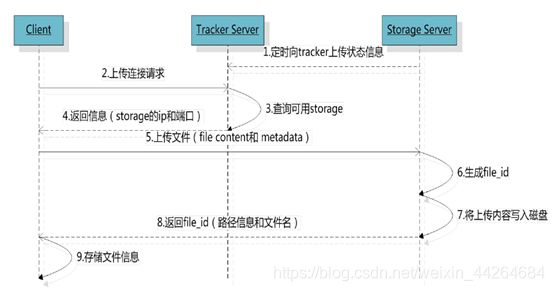
客户端上传文件后存储服务器将文件ID返回给客户端,此文件ID用于以后访问该文件的索引信息。文件索引信息包括:组名,虚拟磁盘路径,数据两级目录,文件名。
组名:文件上传后所在的storage组名称,在文件上传成功后有storage服务器返回,需要客户端自行保存。
虚拟磁盘路径:storage配置的虚拟路径,与磁盘选项store_path*对应。如果配置了store_path0则是M00,如果配置了store_path1则是M01,以此类推。
数据两级目录:storage服务器在每个虚拟磁盘路径下创建的两级目录,用于存储数据文件。
文件名:与文件上传时不同。是由存储服务器根据特定信息生成,文件名包含:源存储服务器IP地址、文件创建时间戳、文件大小、随机数和文件拓展名等信息。
文件下载
//1.导入fastDFSjar包
//2.加载配置文件,配置文件的内容就是tracker服务器的地址
ClientGlobal.init(“E:/k8508workspace/jd-manager/jd-manager-service/src/main/resources/properties/fdfs_tracker.conf”);
//3.创建trackerCLient对象
TrackerClient trackerClient = new TrackerClient();
//4.通过trackerClient对象,创建trackerServer对象
TrackerServer trackerServer = trackerClient.getConnection();
//5.声明StrogageServer对象
StorageServer storageServer = null;
//6.创建StorageCleint对象
StorageClient storageClient = new StorageClient(trackerServer, storageServer);
//7.使用storageClient来完成图片的上传
String[] strings = storageClient.upload_file(“D:\img.jpg”, “jpg”, null);
//8.返回数组(包含group 图片的路径)
for (String string : strings) {
System.out.println(string);
}
与spring整合后使用FastDFSClient工具类上传
FastDFSClient client=new FastDFSClient(“classpath:properties/fdfs_tracker.conf”);
String fileName=uploadFile.getOriginalFilename();
String extName=fileName.substring(fileName.indexOf(".")+1);
String path=client.uploadFile(uploadFile.getBytes(),extName);
String realPath=“http://192.168.25.133/”+path;
七、Redis
NoSQL,泛指非关系型的数据库,NoSQL即Not-Only SQL,它可以作为关系型数据库的良好补充。兴起原因:
1、High performance - 对数据库高并发读写的需求
2、Huge Storage - 对海量数据的高效率存储和访问的需求
3、High Scalability && High Availability- 对数据库的高可扩展性和高可用性的需求
NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
NoSQL数据库的四大分类如下:
键值(Key-Value)存储数据库
相关产品: Tokyo Cabinet/Tyrant、Redis、Voldemort、Berkeley DB
典型应用: 内容缓存,主要用于处理大量数据的高访问负载。
数据模型: 一系列键值对
优势: 快速查询(内存中)
劣势: 存储的数据缺少结构化
列存储数据库
相关产品:Cassandra, HBase, Riak
典型应用:分布式的文件系统
数据模型:以列簇式存储,将同一列数据存在一起
优势:查找速度快,可扩展性强,更容易进行分布式扩展
劣势:功能相对局限
文档型数据库
相关产品:CouchDB、MongoDB
典型应用:Web应用(与Key-Value类似,Value是结构化的)
数据模型: 一系列键值对
优势:数据结构要求不严格
劣势: 查询性能不高,而且缺乏统一的查询语法
图形(Graph)数据库
相关数据库:Neo4J、InfoGrid、Infinite Graph
典型应用:社交网络
数据模型:图结构
优势:利用图结构相关算法。
劣势:需要对整个图做计算才能得出结果,不容易做分布式的集群方案。
Redis应用场景
缓存(数据查询、短连接、新闻内容、商品内容等等)。(最多使用)
分布式集群架构中的session分离。
聊天室的在线好友列表。
任务队列。(秒杀、抢购、12306等等)
应用排行榜。
网站访问统计。
数据过期处理(可以精确到毫秒)
与spring整合
Spring中使用接口注入方式,而JedisClient有两个实现类
与spring整合时我们使用Redis集群,所以选择JedisClientCluster
而由于JedisClientCluster需要注入JedisCluster,所以bean中还需配置JedisCluster
3.根据查询删除
@Test
public void deleteDocumentByQuery() throws Exception {
SolrServer solrServer = new HttpSolrServer(“http://192.168.25.154:8080/solr”);
solrServer.deleteByQuery(“title:change.me”);
solrServer.commit();
}
4.查询索引库
查询步骤:
第一步:创建一个SolrServer对象
第二步:创建一个SolrQuery对象。
第三步:向SolrQuery中添加查询条件、过滤条件。。。
第四步:执行查询。得到一个Response对象。
第五步:取查询结果。
第六步:遍历结果并打印。
4.1简单查询
@Test
public void queryDocument() throws Exception {
// 第一步:创建一个SolrServer对象
SolrServer solrServer = new HttpSolrServer(“http://192.168.25.154:8080/solr”);
// 第二步:创建一个SolrQuery对象。
SolrQuery query = new SolrQuery();
// 第三步:向SolrQuery中添加查询条件、过滤条件。。。
query.setQuery(":");
// 第四步:执行查询。得到一个Response对象。
QueryResponse response = solrServer.query(query);
// 第五步:取查询结果。
SolrDocumentList solrDocumentList = response.getResults();
System.out.println(“查询结果的总记录数:” + solrDocumentList.getNumFound());
// 第六步:遍历结果并打印。
for (SolrDocument solrDocument : solrDocumentList) {
System.out.println(solrDocument.get(“id”));
System.out.println(solrDocument.get(“item_title”));
System.out.println(solrDocument.get(“item_price”));
}
}
4.2带高亮显示
@Test
public void queryDocumentWithHighLighting() throws Exception {
// 第一步:创建一个SolrServer对象
SolrServer solrServer = new HttpSolrServer(“http://192.168.25.131:8080/solr”);
// 第二步:创建一个SolrQuery对象。
SolrQuery query = new SolrQuery();
// 第三步:向SolrQuery中添加查询条件、过滤条件。。。
query.setQuery(“测试”);
//指定默认搜索域
query.set(“df”, “item_keywords”);
//开启高亮显示
query.setHighlight(true);
//高亮显示的域
query.addHighlightField(“item_title”);
query.setHighlightSimplePre("");
query.setHighlightSimplePost("");
// 第四步:执行查询。得到一个Response对象。
QueryResponse response = solrServer.query(query);
// 第五步:取查询结果。
SolrDocumentList solrDocumentList = response.getResults();
System.out.println(“查询结果的总记录数:” + solrDocumentList.getNumFound());
// 第六步:遍历结果并打印。
for (SolrDocument solrDocument : solrDocumentList) {
System.out.println(solrDocument.get(“id”));
//取高亮显示
Map
List list = highlighting.get(solrDocument.get(“id”)).get(“item_title”);
String itemTitle = null;
if (list != null && list.size() > 0) {
itemTitle = list.get(0);
} else {
itemTitle = (String) solrDocument.get(“item_title”);
}
System.out.println(itemTitle);
System.out.println(solrDocument.get(“item_price”));
}
}
Spring中xml的配置
- 集群Solr
使用步骤:
第一步:把solrJ相关的jar包添加到工程中。
第二步:创建一个SolrServer对象,需要使用CloudSolrServer子类。构造方法的参数是zookeeper的地址列表。
第三步:需要设置DefaultCollection属性。
第四步:创建一SolrInputDocument对象。
第五步:向文档对象中添加域
第六步:把文档对象写入索引库。
第七步:提交。
@Test
public void testSolrCloudAddDocument() throws Exception {
// 第一步:把solrJ相关的jar包添加到工程中。
// 第二步:创建一个SolrServer对象,需要使用CloudSolrServer子类。构造方法的参数是zookeeper的地址列表。
//参数是zookeeper的地址列表,使用逗号分隔
CloudSolrServer solrServer = new CloudSolrServer(“192.168.25.135:2181,192.168.25.135:2182,192.168.25.135:2183”);
// 第三步:需要设置DefaultCollection属性。
solrServer.setDefaultCollection(“collection2”);
// 第四步:创建一SolrInputDocument对象。
SolrInputDocument document = new SolrInputDocument();
// 第五步:向文档对象中添加域
document.addField(“item_title”, “测试商品”);
document.addField(“item_price”, “100”);
document.addField(“id”, “test001”);
// 第六步:把文档对象写入索引库。
solrServer.add(document);
// 第七步:提交。
solrServer.commit();
}
九、ActiveMQ
对于消息的传递有两种类型:
一种是点对点的,即一个生产者和一个消费者一一对应;
另一种是发布/订阅模式,即一个生产者产生消息并进行发送后,可以由多个消费者进行接收。
JMS定义了五种不同的消息正文格式,以及调用的消息类型,允许你发送并接收以一些不同形式的数据,提供现有消息格式的一些级别的兼容性。
· StreamMessage – Java原始值的数据流
· MapMessage–一套名称-值对
· TextMessage–一个字符串对象
· ObjectMessage–一个序列化的 Java对象
· BytesMessage–一个字节的数据流
一般我们使用TextMessage
ActiveMQ生产者和消费者的xml共同配置
生产者
Xml:
代码:
jmsTempate.send(addItemTopic, new MessageCreator() {
@Override
public Message createMessage(Session session) throws JMSException {
return session.createTextMessage(id+"");
//匿名内部类中使用方法外定义的变量必须是final修饰的常量
}
});
消费者
本质是一个监听器
十、FreeMarker
Freemaker生成静态页面的时机
添加商品后使用activemq广播消息,freemaker监听到消息去数据库查询商品生成静态页面
为什么不去redis中获取商品信息?
添加商品时还没有存到redis中
为什么不直接使用商品信息还要到数据库中查询?
不在一个项目中传输数据麻烦,也起不到提高效率的作用;而且修改数据时也要修改静态页面
十一、Nginx
负载均衡,反向代理。集群。
反向代理:
反向代理服务器决定哪台服务器提供服务。返回代理服务器不提供服务器。也是请求的转发。
负载均衡:
如果一个服务由多条服务器提供,需要把负载分配到不同的服务器处理,需要负载均衡。可以根据服务器的实际情况调整服务器权重。权重越高分配的请求越多,权重越低,请求越少。默认是都是1
高可用:
nginx作为负载均衡器,所有请求都到了nginx,可见nginx处于非常重点的位置,如果nginx服务器宕机后端web服务将无法提供服务,影响严重。
为了屏蔽负载均衡服务器的宕机,需要建立一个备份机。主服务器和备份机上都运行高可用(High Availability)监控程序,通过传送诸如“I am alive”这样的信息来监控对方的运行状况。当备份机不能在一定的时间内收到这样的信息时,它就接管主服务器的服务IP并继续提供负载均衡服务;当备份管理器又从主管理器收到“I am alive”这样的信息时,它就释放服务IP地址,这样的主服务器就开始再次提供负载均衡服务。
keepalived
keepalived是集群管理中保证集群高可用的一个服务软件,用来防止单点故障。
Keepalived的作用是检测web服务器的状态,如果有一台web服务器死机,或工作出现故障,Keepalived将检测到,并将有故障的web服务器从系统中剔除,当web服务器工作正常后Keepalived自动将web服务器加入到服务器群中,这些工作全部自动完成,不需要人工干涉,需要人工做的只是修复故障的web服务器。
keepalived工作原理
keepalived是以VRRP协议为实现基础的,VRRP全称Virtual Router Redundancy Protocol,即虚拟路由冗余协议。
虚拟路由冗余协议,可以认为是实现路由器高可用的协议,即将N台提供相同功能的路由器组成一个路由器组,这个组里面有一个master和多个backup,master上面有一个对外提供服务的vip(VIP = Virtual IP Address,虚拟IP地址,该路由器所在局域网内其他机器的默认路由为该vip),master会发组播,当backup收不到VRRP包时就认为master宕掉了,这时就需要根据VRRP的优先级来选举一个backup当master。这样的话就可以保证路由器的高可用了。
keepalived主要有三个模块,分别是core、check和VRRP。core模块为keepalived的核心,负责主进程的启动、维护以及全局配置文件的加载和解析。check负责健康检查,包括常见的各种检查方式。VRRP模块是来实现VRRP协议的。
十二、SSO
流程图
登录的处理流程:
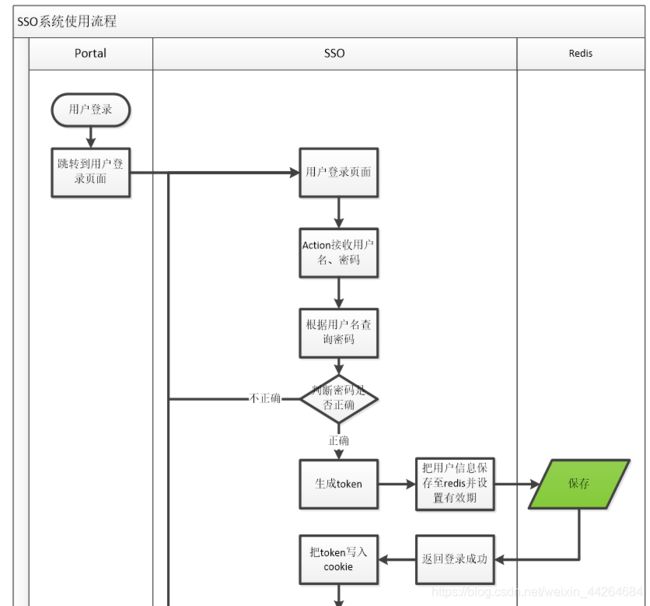
1、登录页面提交用户名密码。
2、登录成功后生成token。Token相当于原来的jsessionid,字符串,可以使用uuid。
3、把用户信息保存到redis。Key就是token,value就是TbUser对象转换成json。
4、使用String类型保存Session信息。可以使用“前缀:token”为key
5、设置key的过期时间。模拟Session的过期时间。一般半个小时。
6、把token写入cookie中。
7、Cookie需要跨域。例如www. itrip.com\sso.itrip.com\order. itrip.com,可以使用工具类。
8、Cookie的有效期。关闭浏览器失效。
9、登录成功。
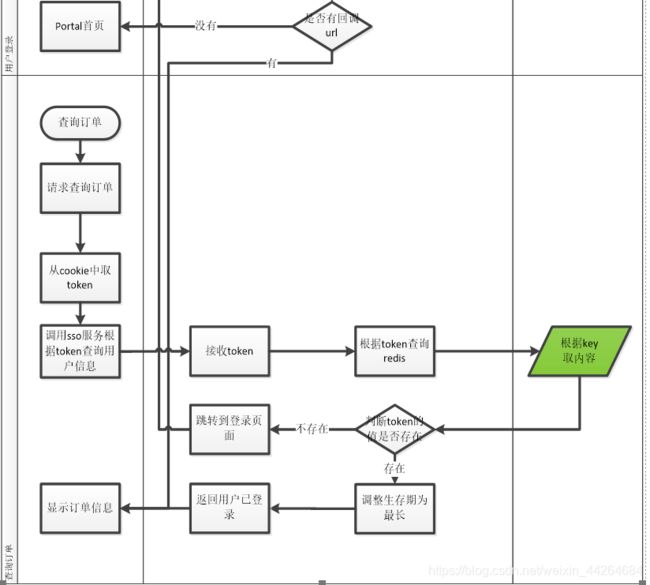
其他系统验证登陆的流程:
1、从cookie中取token,未取到说明没有登陆过
2、根据token去Redis中查value,如果有则说明登陆过,获取登陆信息对象并重置Redis中的存在时间。如果没有则说明登陆时间过久已经过期,重新登陆。
关于登陆后页面的跳转:
1、跳转登录页面时在url后设置一个returnurl
![]()
2、在跳转到登陆页面的jsp时把参数带过去

3、在登陆页面登陆成功后判断是否有returnurl,如果没有则跳转到主页,有的话就跳转到该url
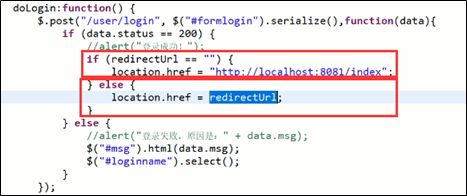
JsonP:
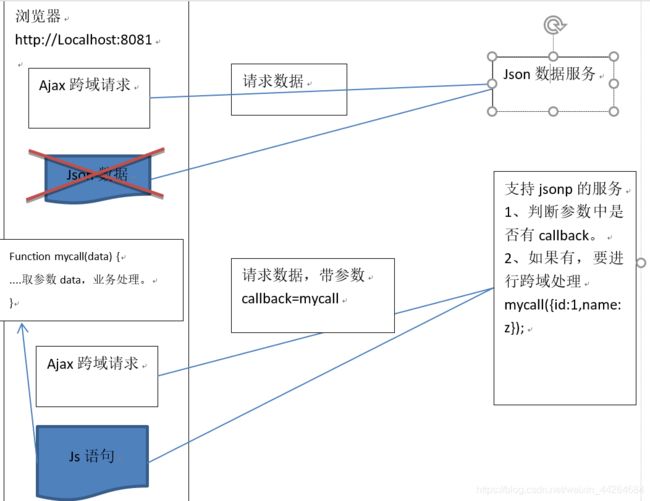
Jsonp的第一种处理方式(对spring无版本要求,用的少):
判断前台是否有callback,如果有则说明是jsonp请求,把响应结果转换为js语句,交给前台解析
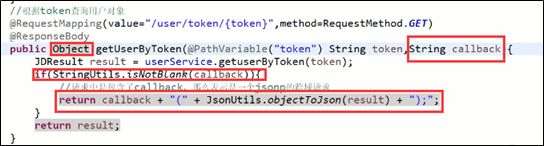
Ajax请求类型为jsonp,用JSON.stringify()解析结果
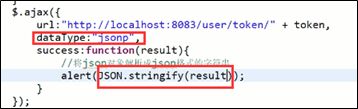
JsonP的第二种处理方式(spring版4.1以上,用的多):
十三、购物车
购物车的本质是存放商品的List,由于从cookie中取值和设值要涉及到request对象与response对象,所以该过程最好在Controller中实现。
在操作购物车时先试图从cookie中取购物车,如果有就把取到的json转成List<对象>集合使用,如果没有就创建一个购物车List<对象>。并把该创建出的对象写到cookie中。
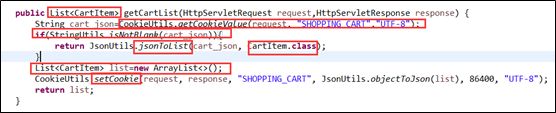
在购物车中的业务逻辑:
每次操作从cookie中取,操作完成后写入到cookie
添加:
1、从cookie中查询商品列表。
2、判断商品在商品列表中是否存在。
3、如果存在,商品数量相加。
4、不存在,根据商品id查询商品信息。
5、把商品添加到购车列表。
6、把购车商品列表写入cookie。
修改:
请求的url:/cart/update/num/{itemId}/{num}
参数:long itemId、int num
业务逻辑:
1、接收两个参数
2、从cookie中取商品列表
3、遍历商品列表找到对应商品
4、更新商品数量
5、把商品列表写入cookie。
6、响应JdResult。Json数据。
删除:
请求的url:/cart/delete/{itemId}
参数:商品id
返回值:展示购物车列表页面。Url需要做redirect跳转。
业务逻辑:
1、从url中取商品id
2、从cookie中取购物车商品列表
3、遍历列表找到对应的商品
4、删除商品。
5、把商品列表写入cookie。
返回逻辑视图:在逻辑视图中做redirect跳转。
登陆:
在用户登录后,我们面临着两个购物车对象,一个是cookie中未登陆状态的购物车,另一个是用户本身在redis中存在的购物车,那么在用户登录后我们需要把两个购物车合并成一个购物车对象后存入reids。并清楚cookie中的购物车。
十四、登陆拦截器
Xml配置
mvc:interceptors
mvc:interceptor
类的编写
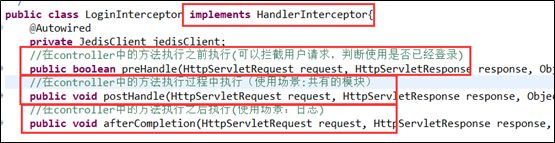
//1.从cokie中取出token
//获取到浏览器中的所有的cookie
String token = CookieUtils.getCookieValue(request, “SESSION_TOKEN”);
if(StringUtils.isBlank(token)){
//浏览器中连token都没有,那么肯定是没有登录的
response.sendRedirect(“http://localhost:8084/login”);
return false;
}
//2.token在浏览器中找到了,那么直接从redis中查询
String user_str = jedisClient.get(“USER_SESSION:” + token);
if(StringUtils.isBlank(user_str)){
//登录过期
response.sendRedirect(“http://localhost:8084/login”);
return false;
}
//表示登录上了
TbUser user = JsonUtils.jsonToPojo(user_str, TbUser.class);
//request.setAttribute(“user”, user);
//System.out.println(user.getUsername());
//如果返回false表示拦截用户请求,不会让用户的请求到达contorller中的方法,
//如果返回的是true表示放行
return true;
关于拦截器与controller之间的对象传输:
可以将拦截器得到的对象存入request对象中,由于拦截器与controller之间共用一个request,所以可以在controller中通过request对象取到存取的值。
request.setAttribute(“user”, tbUser);
十五、支付
支付流程:
商城===>第三方===>银行===>第三方===>商城
安全保证:
HMAC的一个典型应用是用在“质疑/应答”(Challenge/Response)身份认证中。
认证流程
(1) 先由客户端向服务器发出一个验证请求。
(2) 服务器接到此请求后生成一个随机数并通过网络传输给客户端(此为质疑)。
(3) 客户端将收到的随机数提供给ePass,由ePass使用该随机数与存储在ePass中的密钥进行HMAC-MD5运算并得到一个结果作为认证证据传给服务器(此为响应)。
(4) 与此同时,服务器也使用该随机数与存储在服务器数据库中的该客户密钥进行HMAC-MD5运算,如果服务器的运算结果与客户端传回的响应结果相同,则认为客户端是一个合法用户
微信支付
步骤:
1、 生成订单(完成)
2、 调用微信统一下单的API,生成预支付链接code_url,这个地址用于生成二维码
3、 获取用户的支付状态(成功、失败等)
a) 手动调用订单查询的API来获取,调用时,传递订单编号
b) 在调用统一下单API的时候,我们会指定一个回调URL,在支付成功之后,微信平台会调用这个url,来通知支付结果
在得到成功的状态后,我们在系统后台更新订单的状态、通知发货、修改库存等操作。
前台: 递归发送ajax请求,查询订单的状态是否修改,后台需要根据订单id查询数据库中订单状态,这种方式称为“ajax轮询”,通过ajax轮询来获取订单的支付状态。支付成功就跳转页面。
十六、定时任务quartz
execute

配置中的类名与方法名要与编写的类对应。
十六、秒杀
高并发、负载压力大(解决方案:nginx、redis缓存/页面静态化技术、activemq消息队列)
竞争资源是有限的(加锁:数据库悲观锁、通过redis)
对其他业务的影响
提防“黄牛党”(解决方案:ip地址、数据挖掘、接口加密)、
- 架构原则
(1)尽量将压力拦截在上游
系统的瓶颈往往在数据层,数据库的并发能力是有限的。相对于高流量,真正的有效地数据库访问时微乎其微
(2)充分利用缓存
读多写少意味着必须充分利用缓存
(3)热点隔离
业务隔离(预售报名、分时段等)
系统隔离
数据隔离
2.技术维度
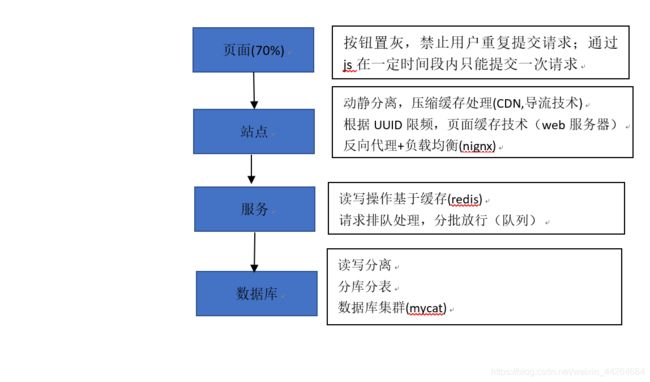
3.从技术难点上看:
1)业务核心在于商品表中的减少与购买成功表中的增加要控制在同一个事务当中,可以使用自定义的异常来进行业务逻辑上的事务回滚
2)数据库的行几所严重影响数据写入的效率,可以利用Redis的单线程机制在Redis中完成业务上的数据读写后再同步到MySql数据库中
3)在保证接口安全上,在前台请求时会根据后台的时间判断是否返回加密后的md5字符串,前台根据后台返回的md5字符串拼凑到请求的url中,到后台判断该md5字符串是否与后台生成的MD5字符串一致来保证接口的安全
4)关于高并发,为了避免前台jsp页面频繁请求后台数据,可以使用freemarker技术实现页面的静态化,静态化的时机选择在添加秒杀商品后