JAVA语言入门
JAVA语言入门
1. 语言简介
计算机语言的分类:
- 机器语言
- 汇编语言
- 高级语言
- 第一代:C语言,面向过程为编程思想,它是唯一一门可以直接操作计算机硬件的语言。
- 第二代:C++,面向对象为编程思想,没有默认的垃圾回收机制(GC)。
- 第三代:Java,面向对象为编程思想,有默认的GC。
- 第四代:自然语言,面向问题为编程思想。
2. Java语言简介
为什么要学习Java语言?
-
Java是使用最广泛,且用法简单的语言。
-
Java是一门强类型的语言(对数据类型的划分很精细)。
-
Java有非常严谨的异常处理机制。
-
Java提供了对于大数据的基础性支持。hadoop的底层使用java编写。
1995年由SUN公司推出,Java之父:詹姆斯·高斯林,SUN公司在2009年被Oracle收购。
2.1 平台版本
- J2SE:标准版,也是其他两个版本的基础。在JDK1.5时正式更名为JavaSE。
- J2ME:小型版,一般用来开发嵌入式程序,已经被andorid替代。在JDK1.5时正式更名为JavaME。
- J2EE:企业版,一般开发企业级互联网程序。在JDK1.5时正式更名为JavaEE。
2.2 特点
开跨两多面:开源跨平台,多线程多态面向对象。
- 开源
- 源代码是开源的。
- 跨平台
- 用Java编写的程序可以在不同的操作系统上运行。
- 原理:有JVM保证Java程序的跨平台性,但是JVM本身不跨平台。
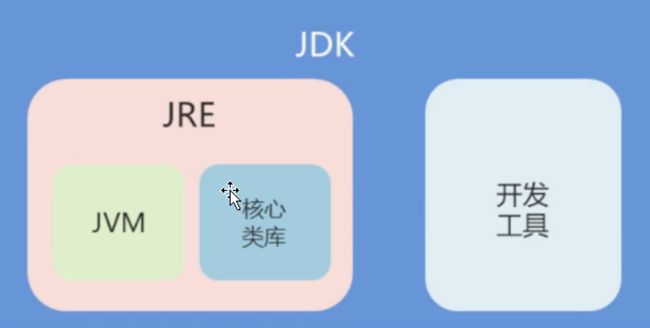
3. JDK和JRE
3.1 概述
- JDK:Java开发工具包(Java Development Kit),包含开发工具和JRE。
- 常用的开发工具:javac,java
- JRE:Java运行时环境(Java Runtime Environment),包含运行Java程序所需的核心类库和JVM。
- 核心类库:java.lang, java util, java.io
- JVM:Java虚拟机(Java Virtual Machine)
- 作用:用来保证Java程序跨平台,但是JVM本身不能跨平台
- 作用:用来保证Java程序跨平台,但是JVM本身不能跨平台
3.2 Java环境搭建
- JDK的下载
- www.oracle.com
Library->Java->JavaVirtualMachines->jdk1.8.0_301.jdk
- 目录解释
- bin:存放编译器和工具
- db:存放数据
- include:编译本地方法
- jre:java运行时文件
- lib:类库文件
- src.zip:源代码
4. Path环境的配置
目的:在任何路径下都可以使用JDK提供的工具。例如java,javac。
vim ~/.bash_profile
添加变量名,变量值。
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_301.jdk/Contents/Home
export CLASSPAHT=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
验证:
在terminal中输入:java -version
5. Hello World案例
程序的开发:编写->编译->执行
- 编写源代码:在后缀为.java的文件中编写。
- 编译:把我们能看懂的文件编译成计算机能看懂的文件。
- .java -> .class(字节码文件,给计算机看的)
- 运行:计算机运行字节码文件,用过java指令实现。
javac HelloWorld.java
会产生一个HelloWorld.class文件
java HelloWorld #由于设计规范,此处无需后缀,实际执行.class文件
显示运行结果
6. IDEA
6.1 IDEA中模块和项目之间的关系
方式:新建一个JavaSE项目,每天新增一个模块(推荐)

6.2 HelloWorld案例
- 创建一个空的项目
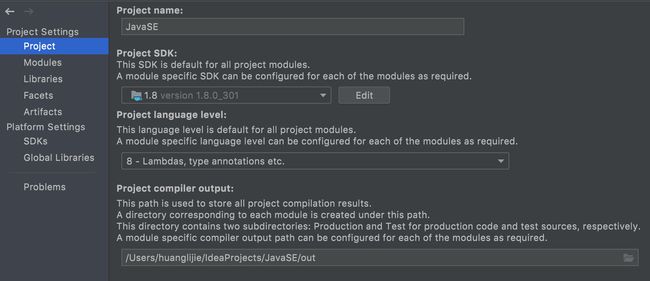
在project选项中设置SDK和Project Language Level
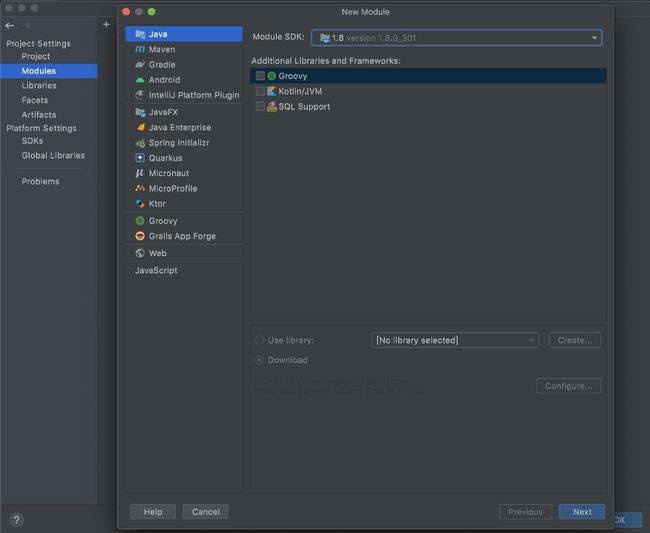
- 在该项目下创建Day01模块
Modules->Java->Moduel SDK设置
- 在Day01模块的src(源代码包)下创建:自定义包
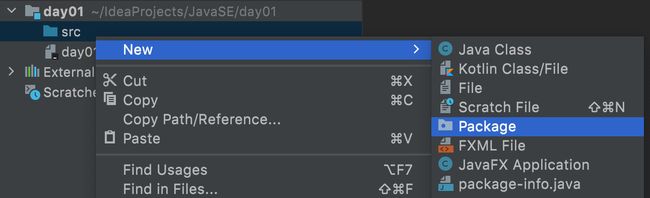
-
在自定义包下创建Java类

-
在Java类中写代码
-
运行
6.3 快捷键

7. 关键字
关键字:被java赋予了特殊含义的单词。
- 特点
- 关键字有纯英文小写字母组成
- 常用开发工具会highlight关键字
7.1 常用关键字
- public:公共的权限
- class:表示创建一个类
- static:静态
- void:表示方法的返回值类型
7.2 定义java源代码文件的格式
public class 类名{
public static void main(String[] args){
System.out.println(这里的内容随便写);
}
}
8. 常量
概述
在程序的执行中,其值不能发生改变的量。
分类
- 自定义常量
- 字面值常量
- 整数常量 直接写
- 小数常量 直接写
- 字符常量 值要用’ '包裹
- 字符串常量 值要用“ ”包裹
- 布尔常量 值只有true和false
- 空常量 值只有null
9. 变量
9.1 概述
在程序的执行中,其值可以在某个范围内发生改变的量。从本质上讲,变量其实是内存中的一小块区域,例如:
- 商品的价格(1元,5元,100元)
- 钟表的时间(5点,6点,10点半)
- 人的年龄(10岁,20岁,50岁)
- 程序员生涯的职位(开发工程师,开发经理,项目经理,CTO)
java中要求每个变量每次只能保存一个数据,而且必须要明确保存数据的数据类型。
9.2 变量的限制
-
变量的值在某一个范围内发生变化。(通过数据类型来限制)
-
能找到这一块区域。(通过变量名实现)
-
区域内必须有数据。(初始化值)
形式:
数据类型 变量名 = 初始化值;
9.3 数据类型
java是一门强类型语言。其对数据的划分很精细。
| 整型 | ||
|---|---|---|
| byte | 1个字节 | -128~127 |
| short | 2个字节 | |
| int | 4个字节 | |
| long | 8个字节 | |
| 浮点型 | ||
| float | 4个字节 | |
| double | 8个字节 | |
| 字符型 | ||
| char | 2个字节 | |
| 布尔型 | ||
| boolean | 1个字节 |
- byte类型的取值范围是:-128~127,char类型的取值范围是0~65535
- 默认的整型是int,默认的浮点是double
- 定义long型时,数据后面要加字母L
- 定义float型时,数据后面要加字幕F
方式一:直接初始化变量
int a = 10;
方式二:先声明,后赋值
int a;
a = 10;
9.4 注意事项
- 变量未赋值不能使用。
- 变量只在它所属的范围内有效(代码块内)。
- 一行可以定义多个变量,但是不建议。
10. 标识符
10.1 概述
标识符就是用来给类,接口,方法,变量,包等起名字的规则。
10.2 命名规则
- 标识符只能包含52个英文字母(区分大小写)、数字、$和_。
- 标识符不能以数字开头。
- 标识符不能和关键字重名。
- 最好做到见名知其意。
10.3 命名规范
- 类,接口:每个单词的首字母大写,其他小写(大驼峰命名法)。
- 变量,方法:从第二个单词开始,每个单词的首字母都大写,其他小写(小驼峰命名法)。
- 常量:所有字母都大写,单词之间用下划线连接。
- 包:所有字母全小写,多级包之间用.隔开,一般是把公司的域名反写。
hust.edu.cn -> cn.edu.hust
11. 数据类型转换
11.1 自动类型转换
小类型转大类型,会自动提升为大类型,运算结果时大类型。
double a = 10;
- int和double相加,为double
- char和int相加,为int
- boolean和int相加,报错
- 转换规则
- 范围小的类型向范围大的类型提升,byte, short, char运算时直接提升为int
- boolean类型不能参与数值转换
11.2 强制类型转换
手动将大类型转换成小类型,运算结果是小类型
short s = 1;
s = (short)(s+1);
System.out.println(s);//结果为2,short类型
12. 常量和变量相加
Java中对于常量,有常量优化机制。
- 针对于byte类型:
- 常量相加:常量相加会直接运算,然后判断结果在不在左边的数据范围内
- 变量相加:会自动提升数据类型,然后运算,提升规则
byte, short, char -> int -> long -> float -> double
- 针对于string类型:
- 后边API解释
13. 运算符
运算符:连接常量和变量的符号。
表达式:用运算符把常量或者变量连接起来符合java语法的式子。
不同运算符连接的表达式体现的是不同类型的表达式。
13.1 算数运算符
整数相除,结果还是整数。除非有浮点型参与。
加号运算符在字符串之间表示连接。
System.out.println("Hello" + 5 + 5)//Hello55
System.out.println("Hello" + (5 + 5))//Hello10
System.out.println(5 + 5 + "Hello" + 5 + 5)//10Hello55
13.2 自增和自减运算符
i++,先运算后自增
++i,先自增后运算
++和–都隐含了强制类型转换。
byte a = 1;
a = a++;//包含了强制类型转换,等价于下行代码
a = (byte)(a + 1);
13.3 赋值运算符
基本的赋值运算符:=
拓展的赋值运算符:+=, -=, *=, /=, %=
a += b; 等价于 a = a + b;
赋值运算符的左边不能为常量。
拓展的赋值运算符默认包含了强制转换。
byte a = 1;
a += 1;//包含了强制类型转换,等价于下行代码
a = byte(a + 1);
13.4 关系运算符
==, !=, >, <, <=, >=,返回true或者false
13.5 逻辑运算符
&, |, !,^异或
短路逻辑运算符
| 符号 | 作用 | 说明 |
|---|---|---|
| && | 短路与 | 作用和&相同,但是有短路效果,前面如果出现false,后面不执行 |
| || | 短路与 | 作用和|相同,但是有短路效果,前面如果出现true,后面不执行 |
13.6 三元运算符
(关系表达式)? 表达式1 : 表达式2;
首先执行关系表达式,如果true执行表达式1,如果false执行表达式2
14 键盘录入 Scanner类
14.1 使用步骤
- 导包
写在类上面,package下面
import java.util.Scanner;
- 创建Scanner类的对象
Scanner sc = new Scanner(System.in);
- 通过Scanner类的nextInt()方法接收用户录入的数据
int a = sc.nextlnt();
15 流程控制
15.1 概述
某些代码在满足特定条件下才会执行;有些代码在满足特定条件下重复执行。这些都需要用到流程控制语句。
15.2 分类
- 顺序结构
- 选择结构(if语句,switch.case语句)
- 循环结构(for循环,while循环,do.while循环)
15.3 顺序结构
代码按照从上往下从左往右的顺序依次逐行执行。是java程序的默认结构。
System.out.println(10+10+"Hello"+10+10);
20Hello1010
15.4 选择结构
15.4.1 if语句
if语句一般用为范围的判断
- if语句(单分支)单分支结构一般用来判断一种情况
if(条件语句){
//语句体;
}
- if.else语句(双分支)
一般用来判断两种情况
if(条件语句){
//语句体1;
}else{
//语句体2;
}
- if.else if语句(多分支)
if(条件语句1){
//语句体1
}else if(条件语句2){
//语句体2
}else if(条件语句3){
//语句体3
}
···
else{
//语句体
}
15.4.2 switch语句
一般用于固定值判断
switch(表达式){ //表达式的取值类型:byte, short, int, char, JDK5以后可以是枚举,JDK7以后可以是String
case 值1: //case后面跟的是要和表达式进行比较的值
语句体1; //语句体可以使一条或者多条语句
break; //break表示中断,结束switch语句
case 值2:
语句体2;
break;
case 值3:
语句体3;
break;
···
default: //default表示所有情况都不匹配时执行,写在任何位置都是最后才执行
语句体n;
break;
}
case穿透:
在switch语句中,如果case后面不写break,将出现case穿透现象,也就是不会在判断下一个case的值,直接向后运行,知道遇到break,或者整体switch结束。
switch(month){
case 1:
case 2:
case 12:
String season = "Winter";
break;
···
}
思考题:break关键字可以省略吗?
答:最后一个分支的break可以省略,其他分支如果省略break可能对结果有影响。
15.5 循环结构
- for循环
一般适用于循环次数固定的情况。 - while循环
一般适用于循环次数不固定的情况。 - do.while循环
实际开发中基本不用,适用于先执行一次然后判断的情况。
15.5.1 for循环
for(初始化条件;判断条件;控制条件){
//循环体
}
先执行初始化条件,然后执行判断条件,查看结果true还是false,如果true执行循环体,执行控制条件。
15.5.2 while循环
初始化条件;
while(判断条件){
//循环体;
//控制条件;
}
15.5.3 do.while循环
初始化条件;
do{
循环体;
控制条件;
}while(判断条件);
15.6 三种循环区别
- for和其他两个循环的区别
for循环结束后,初始化条件就不能继续使用了。而while和dowhile可以。 - do.while和其他两个循环的区别
先执行一次再判断,而其他两个循环是先判断再执行。
15.7 循环跳转
- break:用来终止循环,循环不再继续执行。
- continue:用来结束本次循环,进行下一次循环,循环还会继续。
15.8 循环嵌套
用得最多的是for循环的嵌套
for(初始条件;判断条件;控制条件){ //外循环
for(初始条件;判断条件;控制条件){ //内循环
//循环体
}
}
16 Math生成随机数
Math类似Scanner,是Java提供好的API(Application Programming Interface),内部提供了产生随机数的工程。
16.1 格式
int num = (int)(Math.random()*100 + 1) //获取1到100之间的随机数
- 可以直接使用,不需要调包。
- 取值范围为[0.0, 1.0)
17 数组
如果需要同时存储多个同类型的数据,我们可以通过数组来实现。
数组就是用来存储多个同类型元素的容器。
17.1 格式
- 动态初始化:给定长度,由系统给出默认初始化值。
//格式一
数据类型[] 数组名 = new 数据类型[长度]; //数组名小驼峰命名法,推荐使用
//格式二
数据类型 数组名[] = new 数据类型[长度];
//上述两种定义方式只是写法不同,并无其他区别。格式一应用的多一些。
- 静态初始化:给定初值,系统给定长度
//格式一
数据类型[] 数组名 = new 数据类型[]{元素1, 元素2, 元素3, ...};
//格式二 语法糖(简化语法的格式)
数据类型[] 数组名 = {元素1, 元素2, 元素3, ...};
初始化数组不可同时给定长度和初值。
int[] arr = new int[3];
解释:
- 数据类型:数组中存储元素的数据类型。如这里的int说明数组中只能存储int类型的数据。
- []:表示是数组
- 数组名:类似于变量名,要符合小驼峰
- new:指创建数组对象
17.2 数组特点及基本用法
17.2.1 特点
- 数组中的元素编号(索引)从0开始。
- 数组中每个元素都有默认值。
类型 元素默认值 int 0 double 0.0 boolean false String null
17.2.2 基本用法
- 通过数组名[索引]的形式,可以快速获取数组中的指定元素。
- 通过数组名[索引]=值;的形式,可以修改数组中的指定元素值。
- 通过数组名.length的方式可以获取数组的长度。
17.3 数组的内存图
17.3.1 内存解释
内存是计算机中的重要元件,也是临时存储区域,作用是运行程序。我们编写的程序是存放在硬盘当中的,在硬盘中的程序是不会运行的,必须放入内存中才能运行,运行完毕后会清空内存。
即:Java虚拟机要运行程序,必须要对内存进行空间的分配和管理。为例提高运算效率,就对空间进行了不同区域的划分,因为每一片区域都有特定的处理数据方式和内存管理方式。
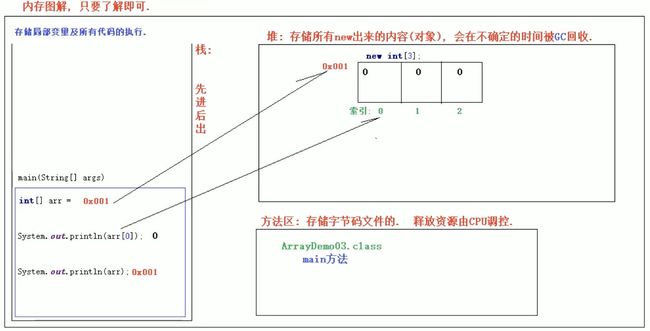
JVM的内存划分
- 栈:存储局部变量以及所有代码执行的。
局部变量:定义在方法中,或者方法声明上的变量。
特点:先进后出 - 堆:存储所有new出来的内容,即对象
特点:堆中的内容会在不确定的时间被GC回收。 - 方法区:存储字节码文件。
字节码文件:后缀为.class的文件。 - 本地方法区:和系统相关,了解即可。
- 寄存器:和CPU相关,了解即可。
内存图解,示意图(并不严格)
public class ArrayDemo{
public static void main (String[] args){
int[] arr = new int[3];
System.out.println(arr[0]);
System.out.println(arr);//打印的是存储地址
}
}
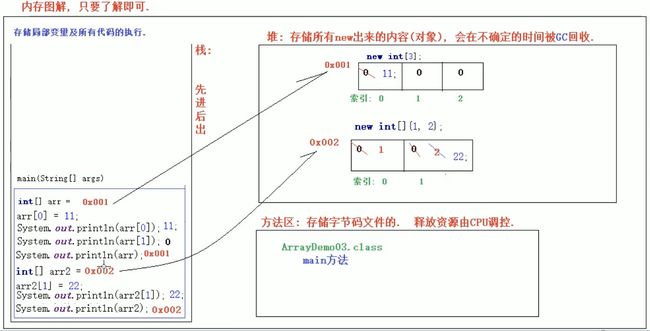
17.3.2 两个数组的内存图
public class StoragePic {
public static void main(String[] args) {
int[] arr = new int[3];
arr[0] = 11;
System.out.println(arr[0]);
System.out.println(arr[1]);
System.out.println(arr);
int[] arr2 = {1, 2};
arr2[1] = 22;
System.out.println(arr2[1]);
System.out.println(arr2);
}
}
17.4 数组的两个小问题
17.4.1 数组索引越界异常
产生原因:访问了数组中不存在的索引
解决方案:访问数组中存在的索引即可
17.4.2 空指针异常
产生原因:访问了空对象
解决方案:对对象赋具体的值
17.5 遍历数组
int[] arr = {11, 22, 33, 44, 55};
for(int i : arr) System.out.println(i);
17.6 获取数组的最值
public class ArrayDemo02 {
public static void main(String[] args) {
int[] arr = {55, 22, 66,77, 33, 44, 55};
int max = arr[0];
for(int i : arr){
if (i >= max) max = i;
}
System.out.println(max);
}
}
17.7 反转数组
public class ReverseArray {
public static void main(String[] args) {
int[] arr = {11, 22, 33, 44, 55};
int temp;
for (int i = 0; i <= arr.length/2; i++){
temp = arr[i];
arr[i] = arr[arr.length-1-i];
arr[arr.length-1-i] = temp;
}
for(int i : arr) System.out.println(i);
}
}
18 方法
方法也叫函数,是将具有独立功能的代码块组织成为一个整体,使其具有特殊功能的代码集。
18.1 定义格式
修饰符 返回值的数据类型 方法名(参数类型 参数名1, 参数类型 参数名2){//这里可以写多个参数
//方法体;
return 具体的返回值;
}
- 修饰符:目前记住这里是固定格式public static
- 返回值的数据类型:用于限定返回值数据类型,如果没有具体的返回值,数据类型用void修饰
- 方法名:方便调用方法
- 参数类型:限定调用方法时传入数据的数据类型
- 参数名:用于接收调用方法时传入的数据的变量
- 方法体:完成特定功能的代码
- return 返回值:用来结束方法并把返回值返回给调用者。如果没有明确的返回着,return关键字可以不写
18.2 注意事项
- 方法与方法之间时平级关系,不能嵌套定义
- 方法必须先创建才可以使用
- 方法自身不运行,需要调用
- 方法的功能越单一越好
- 定义方法的时候写在参数列表中的参数都是形参
- 形参:形容调用方法的时候需要传入什么类型的参数
- 调用方法的时候,传入的具体的值,是实参
- 实参:调用方法时实际参与运算的数据
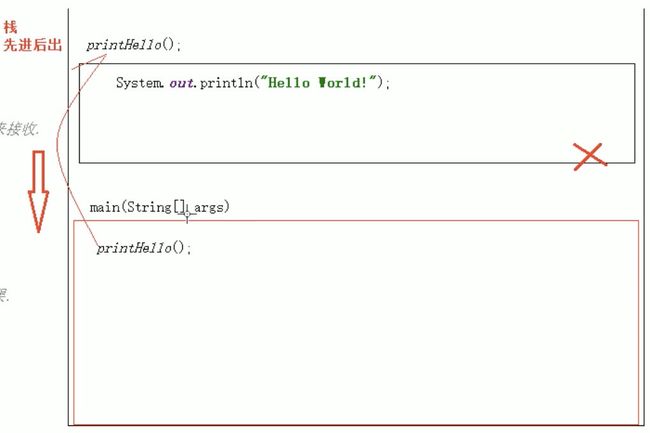
18.3 无参无返回值的方法
public static void 方法名(){
//方法体;
}
图解
18.4 有参无返回值的方法
public static void printNum(int number){
System.out.println("The number is "+ number);
}
18.5 无参有返回值的方法
public static String getSchool(){
return "Huazhong University of Science and Technology";
}
18.6 有参有返回值的方法
public static int getAdd(int a, int b){
return a+b;
}
18.7 方法重载
同一个类中,出现方法名相同,但是参数列表不同的两个或多个的方法时,称为方法重载,方法重载与方法的修饰符、返回值的数据类型无关。
参数列表不同分为两种类型:
- 参数的个数不同
- 对应参数的数据类型不同
18.8 基本类型、引用类型作为形参的情况
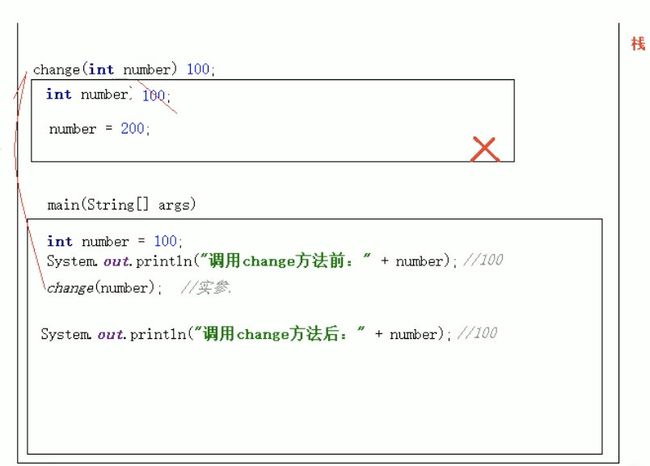
形参如果是基本类型,形参的改变不影响实参。
public class demo01 {
public static void main(String[] args) {
int num = 100;
change(num);
System.out.println(num);//打印结果仍然是100
}
public static void change(int num){
num = 200;
}
}
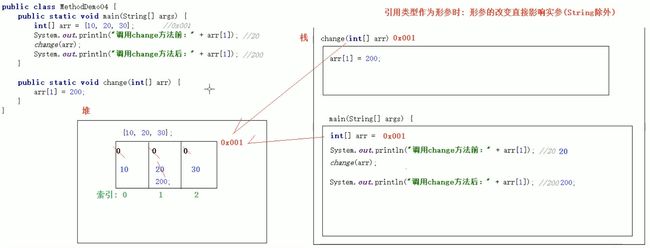
引用类型作为参数时,形参的改变直接影响实参(String类型除外,String类型当作形参使用时,用法和基本类型一致,后续API详解)
public class demo02 {
public static void main(String[] args) {
int[] arr = {10, 20, 30};
System.out.println(arr[1]);//打印结果为20
change(arr);
System.out.println(arr[1]);//打印结果为200
}
public static void change(int[] arr){
arr[1] = 200;
}
}
19 Debug调试
步骤:
- 加断点,哪里不会点哪里
- 运行加了断点的程序,选择debug
- 开始调试
debugger:看代码执行到哪里了
console:控制台,查看程序运行结果
variable:查看变量的变化过程 - 进行下一步
F7:逐过程调试
F8:逐行调试
F9:逐断点调试 - 删除断点
方式一:一个一个删除
方式二:批量删除,选择breakpoints(双红点),移除断点即可
20 面向过程与面向对象
20.1 面向过程
- 明确目的
- 分析过程
- 通过代码一步步实现
以上每一个步骤我们都是参与者,需要面对具体的每一个步骤和过程,
代表语言:C
20.2 面向对象
当需求单一且简单,一步一步操作没有问题效率也挺高。但是如果需求更改、增多,把这些步骤和功能进行封装。封装时根据不同的功能进行不同的封装,功能类似的用一个类封装在一起。使用的时候找到对应的类。
思想特点:
- 是一种符合我们思考习惯的思想
- 可以将复杂的事情简单化
- 让我们从执行者变成了指挥者
小结
面向对象是一种编程思想,它是基于面向过程的,强调的是以对象为基础完成各种操作。
面试题:什么是面向对象?
思路:概述,思想特点,举例,总结
21 类和对象
我们是如何表示现实世界的事物的呢?
- Java语言是用来描述现实世界事物的,最基本的单位是:类
- 类:是一个抽象的概念,看不见也摸不着,它是属性和行为的集合
- 对象:类(该事物)的具体体现,实现
- 属性(成员变量)
- 属性指的就是事物的描述信息(名词)
- 属性在Java中被称为成员变量
- 行为(成员方法)
- 用来指事物能够做什么
- 也叫成员方法,和以前定义方法类似,先不写static
举例
类:学生;大象
对象:张三,23;北京动物园叫图图的大象
属性(成员变量):年龄,性别,专业;年龄,性别,品种
行为(成员方法):学习、吃饭、睡觉;吃饭、睡觉、迁徙
21.1 类的定义格式
定义类其实就是定义类的成员(成员变量和成员方法)
- 成员变量:
- 和以前定义变量是一样的,只不过位置发生了改变,写到类中,方法外
- 成员变量还可以不用赋值,因为它有默认值
- 成员方法:
- 和以前定义方法是一样的,只不过把static关键字去掉
- 这点记忆即可,后面再讲解static关键字的用法
public class student {
//属性(成员变量):姓名,年龄,性别
String name;
int age;
String sex;
//行为(成员方法):学习,吃饭,睡觉
public void study(){
System.out.println("学习");
}
public void eat(){
System.out.println("吃饭");
}
public void sleep(){
System.out.println("睡觉");
}
}
21.2 类的使用
类的使用就是使用类中定义的成员(成员变量和成员方法)
格式
- 创建该类的对象
类名 对象名 = new 类名(); - 通过对象名.的形式,调用类中的指定成员
//成员变量
对象名.成员变量
//成员方法
对象名.成员方法(参数列表中各数据类型对应的值)
示例
public class StudentTest {
public static void main(String[] args) {
Student s = new Student();
System.out.println(s.name);//null(默认值)
System.out.println(s.age); //0(默认值)
System.out.println(s.sex); //null(默认值)
s.name = "Nick";
s.age = 22;
s.sex = "Male";
System.out.println(s.name);//Nick
System.out.println(s.age); //22
System.out.println(s.sex); //Male
}
}
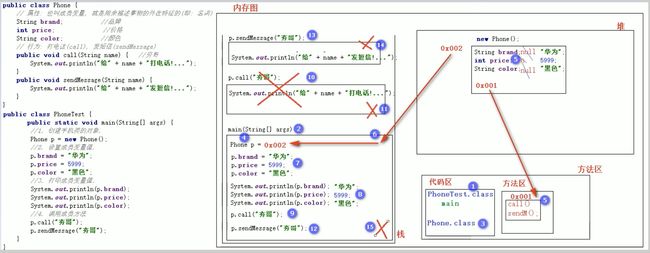
21.3 一个对象的内存图
21.4 两个对象的内存图
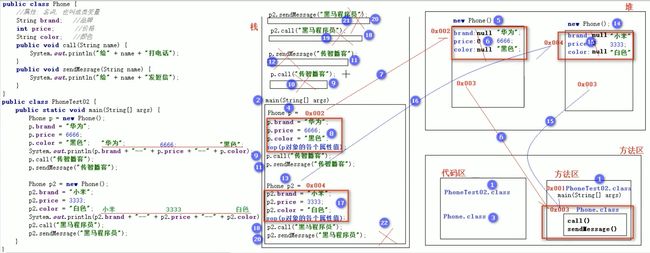
21.5 两个引用指向同一个对象的内存图
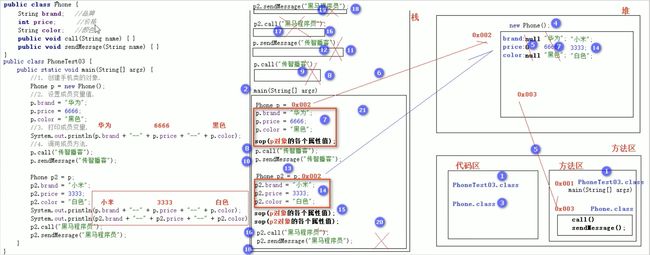
21.6 成员变量和局部变量的区别
- 成员变量:定义在类中,方法外的变量。
- 局部变量:定义在方法中或者方法声明上的变量。
他们的区别如下:
- 定义位置不同
- 成员变量定义在类中,方法外
- 局部变量定义在方法中或者方法声明上
- 在内存中的存储位置不同
- 成员变量:存储在堆内存
- 局部变量:存储在栈内存
- 生命周期不同
- 成员变量随着对象的创建而存在,随着对象的消失而消失
- 局部变量随着方法的调用而存在,随着方法的调用完毕而消失
- 初始化值不同
- 成员变量有默认值
- 局部变量没有默认值,必须定义赋值才能使用
22 封装
上述的代码中,我们可以任意的设置属性的值,包括我们可以设置一些非法值,例如把年龄设置成负数,这样做程序就容易出问题,针对这种情况,我们可以通过private关键字来优化。
22.1 private关键字
private是一个关键字,也是访问权限修饰符的一种,它可以用来修饰类的成员(成员变量和成员方法)
被private修饰的内容只能在本类中直接使用。
应用场景
- 在实际开发中成员变量基本上都是用private关键字来修饰的
- 如果明确知道类中的某些内容不想被外部访问
public class Phone{
private int age;
public int getAge(){
return age;
}
public void setAge(int a){
age = a;
}
}
22.2 封装的概述
封装是面向对象编程思想的三大特征之一,所谓的封装就是隐藏对象的属性和细节,仅对外提供一个公共的访问方式。
面向对象的三大特征:封装、继承、多态
隐藏:private修饰符
公共访问方式:public成员方法
原则
- 把不需要对外提供的内容都隐藏起来
- 把属性隐藏,并提供公共方法对其访问
解释:成员变量都用private修饰,并提供对应的公共方法,其他都用public修饰
好处 - 提高代码的安全性:由private保证
- 提高代码的复用型:由方法保证
22.3 this关键字
this表示本类当前对象的引用,即谁调用,this就代表谁
用来解决局部变量和成员变量重名的问题
使用变量的原则:就近原则(局部位置有就使用,没有就去本类的成员位置找,有就使用,没有就报错)(不严谨,还会去父类找)
package cn.edu.hust.demo;
public class Student {
int x = 1;
public void method(){
int x = 2;
System.out.println(this.x);
System.out.println(x);
}
}
package cn.edu.hust.demo;
public class StudentTest {
public static void main(String[] args) {
Student s = new Student();
s.method();//1,2 this.x等价于s.x
s.x = 10;
s.method();//10,2
}
}
加入this关键字后标准额度JavaBean类的编写方法
public class Student {
private String name;
private int age;
public void setName(String name){
this.name = name;
}
public String getName(){
// return this.name;//能不多写就不写
return name;
}
public void setAge(int age){
this.age = age;
}
public int getAge(){
return age;
}
public void study(){
System.out.println("好好学习,天天向上!");
}
public void sleep(){
System.out.println("为了保证精力,请好好休息!");
}
}
public class StudentTest {
public static void main(String[] args) {
Student s = new Student();
s.setAge(22);
s.setName("Nick");
System.out.println(s.getAge());
System.out.println(s.getName());
s.study();
s.sleep();
}
}
22.4 构造方法
构造方法是用来创建对象的,可以给对象的各个成员变量赋值。
构造方法就是用来快速对对象的各个属性赋值的。
格式
- 构造方法名必须和类名完全一致
- 构造方法没有返回值类型,void也不用
- 构造方法没有具体的返回值,但是可以写return(实际开发中一般不写)
- 构造方法可以重载
public 类名(参数类型 参数名1,参数类型 参数名2){
//给对象的各个属性复制
}
注意事项
- 如果我们没有给出构造方法,系统将给出一个默认的空参构造
- 如果我们给出了构造方法,系统不会给默认的构造方法
给成员变量赋值有两种方式 - setXXX(),不会创建新对象
- 构造方法,会创建新对象
public class Student{
private String name;
private int name;
public Student(String name, int age){
this.name = name;
this.age = age;
}
}
public class StudentTest{
String name = "Nick";
int age = 22;
Student s = new Student(name, age);
}
22.5 JavaBean
JavaBean也可以称为实体类,其对象可以用于在程序中封装数据。
标准JavaBean必须满足如下要求:
- 成员变量全部用private修饰
- 提供成员变量对应的getter和setter方法
- 必须提供一个无参构造器,有参构造器可写可不写
23 继承
多个类中存在相同属性和行为时,将这些内容抽取到单独的一个类中,那么这个类就无需再定义这些属性和行为了,只要继承那个类即可。这个关系就叫继承。
有了继承以后,我们在定义一个类的时候,可以在一个已经存在的类的基础上,还可以定义新的成员。
格式
public class 类A extends 类B{ //A是子类,B是父类
}
好处:
-
提高了代码的复用型
-
提高了代码的可维护性
-
让类与类之间产生关系,是多态的前提
弊端:
- 让类与类之间产生关系,也就让类的耦合性增强了。开发原则:高内聚,低耦合。内聚指类自己独立完成某些事情的能力。耦合指类与类之间的关系。
23.1 继承的特点
- 在java中,类与类之间只能单继承,不能多继承。
- 在Java中,类与类之间可以多层继承。
23.2 继承关系中的成员变量的特点
使用变量遵循“就近原则”,局部位置有就使用,没有就去本类的成员位置查找,有就使用,没有就去父类的成员位置查找,有就使用,没有就报错。
23.3 super关键字
super的用法和this很像
- this代表本类对象的引用
- super代表当前对象的父类的内存空间标识
解释:可以理解为父类对象引用
用法
|功能|本类|父类|
|-|-|-|
|访问成员变量|this.成员变量名|super.成员变量名|
|访问构造方法|this(…)|super(…)|
|访问成员方法|this.成员方法名(参数值…)|super.成员方法名(参数值…)|
23.4 继承中构造方法的特点
-
子类中所有的构造方法默认都会访问父类的空参构造
问:为什么这样设计?
答:用于子类对象访问父类数据前,对父类数据进行初始化
即每一个构造方法的第一行都有一个:super() -
如果父类没有空参构造怎么办?
1)可以通过super(参数)的方式访问父类的带参构造
2)可以this(参数)的方式访问本类的其他构造
3)但是这样做比较麻烦,所以建议永远手动给出空参构造和带参构造。子类的空参构造访问父类的空参构造super();(可以省略不写,默认已有)。子类的带参构造访问父类的带参构造super(成员变量); -
所有的类都间接继承自Object类,Object类是所有类的父类
public class Father {
public Father(int age){
System.out.println("Father带参构造");
}
public Father(){
System.out.println("Father空参构造");
}
}
public class Son extends Father {
public Son(int age){
super(age);
System.out.println("Son带参构造");
}
public Son(){
System.out.println("Son空参构造");
}
}
public class FatherTest {
public static void main(String[] args) {
Son s = new Son(10);
Son s2 = new Son();
}
}
打印结果为:
Father带参构造
Son带参构造
Father空参构造
Son空参构造
23.5 继承中成员方法的特点
继承关系中,调用成员方法时,遵循“就近原则”,本类中有就直接使用,本类中没有就去父类查找。有就调用,没有就报错。
public class Father {
public Father(){
System.out.println("Father空参构造");
}
public Father(int age){
System.out.println("Father带参构造");
}
public void show(){
System.out.println("Father show");
}
}
public class Son extends Father{
public Son(){
System.out.println("Son空参构造");
}
public Son(int age){
super(age);
System.out.println("Son带参构造");
}
public void method(){
System.out.println("Son method");
}
}
public class FamilyTest {
public static void main(String[] args) {
Son s = new Son();
s.method();
s.show();
}
}
打印结果为:
Father空参构造
Son空参构造
Son method
Father show
方法重写
子类中出现和父类一模一样的方法时,称为方法重写,要求返回值的数据类型也必须一样
应用场景
当子类需要使用父类的功能,而功能主题又有自己独有需求的时候,就可以考虑重写父类中的方法了,这样既沿袭了父类的功能,又定义了子类特有的内容
注意事项
- 子类重写父类方法时要用@overwrite注解来修饰
- 父类中私有的方法不能被子类重写
- 子类重写父类方法时,访问权限不能更低
private < 默认
public class Phone {
public Phone(){}
public Phone(String name){}
public void call(String name){
System.out.println("Calling "+name);
}
}
public class NewPhone extends Phone{
public NewPhone(){}
public NewPhone(String name){
super();
}
@Override
public void call(String name){
super.call(name);
System.out.println("播放彩铃");
}
}
public class PhoneTest {
public static void main(String[] args) {
Phone p = new Phone();
NewPhone np = new NewPhone();
p.call("Nick");
np.call("Nick");
}
}
打印结果:
Calling Nick
Calling Nick
播放彩铃
24 多态
多态指的是同一个事物(或者对象)在不同时刻表现出来的不同状态。
前提条件
- 要有继承关系
- 要有方法重写
- 要有父类引用指向子类对象
Person p = new Teacher();
24.1 多态中的成员访问特点
- 成员变量:编译看左边,运行看左边
编译的时候看左边的数据类型有没有这个变量,有不报错,没有报错
运行的时候具体运行的是左边的数据类型里边的:此变量 - 成员方法:编译看左边,运行看右边
编译的时候看左边的数据类型有没有这个方法,有不报错,没有报错
运行的时候具体运行的是左边的数据类型里边的:此方法
原因:方法有重写,而变量没有。
public class Person{
int age = 50;
public void eat(){
System.out.println("Eat.")
}
}
public class Student extends Person{//条件之一:要有继承
int age = 20;
@Override//条件之二:要有方法重写
public void eat(){
System.out.println("Eat hamburgers.")
}
}
24.2 多态的好处和弊端
好处:提高了程序的拓展性
坏处:父类引用不能访问子类的特有功能
处理方法:向下转型
假设Student.class增加一个成员方法
public void study(){
System.out.println("Study.")
}
那么主类需要这样写
public class PersonTest{
public static void main(String[] args){
Person p = new Student();
//p.study() //会报错,因为p是Person类的引用,没有study()成员方法
Student s = (Student)p;
/*
向下转型,类似于强制类型转换
强制类型转换:int a = (int)10.3;
*/
s.study();
}
}
24.3 向上转型和向下转型
向上转型:
Person p = new Student();
向下转型:
Student s = (Student)p;
bug:
Person p = new Student();
Student s = (Student)p;//正确
Teacher t = (Teacher)p;//报错
24.4 实际开发中多态的应用
实际开发中,方法的形参一般都是父类型,这样可以接受其任意子类对象,然后通过多态调用成员方法的规则调用指定子类对象的方法。
public class Animal {
public void eat(){
System.out.println("eat");
}
}
public class Cat extends Animal{
@Override
public void eat(){
System.out.println("cats eat fish");
}
}
public class Dog extends Animal{
@Override
public void eat(){
System.out.println("dogs eat meat");
}
}
public class AnimalTest {
public static void main(String[] args) {
Animal a1 = new Cat();
Animal a2 = new Dog();
show(a1);
show(a2);
}
public static void show(Animal a){
a.eat();
}
}
cats eat fish
dogs eat meat
24.5 instanceof关键字
格式
引用(对象) instanceof 数据类型
返回true或者false
作用
用来判断前边的引用(对象)是否是后边的数据类型
假设Cat类和Dog类分别增加成员方法:
public void catchMouse(){
System.out.println("catch mouse")
}
public void guardHome(){
System.out.println("guard home")
}
主类show方法改变为:
public static void show(Animal a){
a.eat();
if(a instanceof Cat){
Cat c = (Cat) a;
c.catchMouse();
}
else if(a instanceof Dog){
Dog d = (Dog) a;
d.guardHome();
}
}
打印结果为:
cats eat fish
catch mouse
Dogs eat meat
guard home
24.6 final关键字
final是一个关键字,表示最终的意思,可以修饰类,成员变量,成员方法
- 修饰的类:不能被继承,但是可以继承其他的类
- 修饰的变量:是一个常量,只能被赋值一次
- 修饰的方法:不能被子类重写
final常见面试题
final修饰的变量是一个常量,那如果修饰的是基本类型或者引用类型的数据,有区别吗?
如果final修饰的是基本类型的常量,数值不能发生变化
如果final修饰的是引用类型的常量,地址值不能发生变化,但是该对象的属性值可以发生变化
final, finally, finalize这三个关键字之间的区别是什么?
25 static关键字
static是一个关键字,表示静态的意思,可以修饰成员变量和成员方法。
static 修饰成员变量表示该成员变量只在内存中存储一份,可以共享和修改。
特点
-
随着类的加载而加载
-
优先于对象存在
-
被static修饰的内容,能被该类下所有的对象共享
这也是我们判断是否用静态关键字的条件
-
可以通过**类名.**的形式调用
示例
public class Student {
String name;
static String school; //static修饰成员变量
public void show(){
System.out.println("Name:"+name+" School:"+school);
}
}
public class Test {
public static void main(String[] args) {
Student s1 = new Student();
Student s2 = new Student();
s1.name = "Nick";
Student.school = "HUST"; //通过“类名.”调用,所有对象共享
s2.name = "Eva";
s1.show();
s2.show();
}
}
Name:Nick School:HUST
Name:Eva School:HUST
访问特点及注意事项
- 静态方法只能访问静态的成员变量和静态的成员方法(静态只能访问静态)
- 在静态方法中没有this,super关键字
因为静态的内容是随着类的加载而加载,而this和super是随着对象的创建而存在
即先进内存的不能访问后进内存的
26 抽象类
回想前面我们的猫狗案例,提取出了一个动物类,这个时候我们可以通过Animal an = new Animal();来创建动物对象,但其实这是不对的。因为我说动物,你并不知道我说的是什么动物。只有看到了具体的动物,才知道是什么动物。所以说,动物本身不是一个具体的事物,而是一个抽象的事物。只有真正的猫、狗才是动物。同理,我们也可以对象,不同的动物吃的东西是不一样的,所以我们不应该在动物类中给出具体的体现,而是一个声明即可。
在Java中,一个没有方法体的方法定义为抽象方法(用abstract修饰),而类中如果有抽象方法,该类必须定义为抽象类(用abstract修饰)。
26.1抽象类的特点
- 抽象类和抽象方法法必须用abstract关键字修饰
- 抽象类不一定有抽象方法,有抽象方法的类一定是抽象类
- 抽象类不能是实例化,可以通过多态的方式,创建其子类对象,来完成抽象类的实例化,这也叫:抽象类多态
- 抽象类的子类
- 如果是普通类,则必须重写父抽象类中的所有抽象方法
- 如果是抽象类,则可以不用重写父抽象类中的抽象方法
public abstract class Animal {
public abstract void eat();
public void sleep(){
System.out.println("Sleep");
}
}
public class Cat extends Animal{
@Override
public void eat(){
System.out.println("Eat");
}
}
public class Test {
public static void main(String[] args) {
//Animal an = new Animal(); 抽象类不能实例化
Animal an = new Cat();
an.eat();
an.sleep();
}
}
26.2 抽象类的成员特点
抽象类中可以有变量、常量、构造方法、抽象方法和非抽象方法(比普通类多了抽象方法)
思考:既然抽象类不能实例化,那要构造方法有什么用?
答:用于子类对象访问父类数据前,对父类数据进行初始化
27 接口
继续回到我们的猫狗案例,我们想狗的一般行为就是看门,猫的一般行为是捉老鼠。但是有些狗猫可以训练出钻火圈、跳高、做算术等行为。这些行为并不是狗猫天生就具备的。所以这些额外的行为定义到动物类中就不合适,也不合适定义到猫类或者狗类中,因为只有部分猫和部分狗具备。
所以,为了体现事物功能的拓展性,Java就提供了接口来定义这些额外行为,并不给出具体实现,将来哪些猫狗需要被训练,只需要这部分猫狗把这些额外行为实现即可。
27.1 接口特点
- 接口用interface关键字修饰
- 类和接口之间是实现关系,用implements关键字表示
- 接口不能实例化。可以通过多态的方式,创建其子类对象,来完成接口的实例化。这也叫接口多态。
- 接口的子类
- 如果是普通类,则必须重写父接口中所有的抽象方法
- 如果是抽象类,则不用重写父接口中的抽象方法
27.2 接口成员特点
- 接口中有且只有常量或者抽象方法(适用JDK1.8以前),原因是:
- 成员变量有默认修饰符:public static final
- 成员方法有默认修饰符:public abstract
- 接口中是没有构造方法的,因为接口主要是扩展功能的,而没有具体存在。
- JDK1.8的时候,接口中加入了两个新的成员:静态方法、默认方法(必须用default修饰)。
27.3 类与接口之间的关系
- 类与类:继承关系,只能单继承,不能多继承,可以多层继承
- 类与接口:实现关系,可以单实现,可以多实现,可以在继承一个类的同时实现多个接口
- 接口与接口:继承关系,可以单继承,可以多继承
public abstract class Animal {
public abstract void eat();
}
public interface InterA{//父接口
public abstract void methodA();
}
public interface InterB extends InterA{//子接口
public abstract void methodB();
}
public class Cat extends Animal implements InterA, InterB{//由于InterB接口继承了InterA接口,所以这里只写InterB接口也可以
@Override//父类抽象方法要重写
public void eat(){
System.out.println("Eat fish.");
}
@Override//接口抽象方法要重写
public void methodA(){
System.out.println("A");
}
@Override//接口抽象方法要重写
public void methodB(){
System.out.println("B");
}
}
public class InterfaceTest {
public static void main(String[] args) {
//Animal an = new Animal();//**报错**。Animal是抽象类,不能实例化
Animal an = new Cat();
an.eat();//访问成员方法,编译看左(Animal类有eat方法),运行看右(Cat类有eat方法)
//an.methodA(); //**报错**。编译看左(Animal类没有methodA方法)
Cat c = (Cat) an;
c.methodB();
c.methodA();
}
}
27.4 抽象类和接口的区别
- 成员区别
抽象类可以写变量、常量、构造方法、抽象方法、非抽象方法
接口可以写常量、抽象方法,JDK1.8引入了静态方法和默认方法 - 关系区别
- 类与类:继承关系,只能单继承,不能多继承,可以多层继承
- 类与接口:实现关系,可以单实现,可以多实现,可以在继承一个类的同时实现多个接口
- 接口与接口:继承关系,可以单继承,可以多继承
- 设计理念的区别
抽象类:类中定义的是整个继承体系的共性内容
接口:定义的是整个继承体系的扩展内容
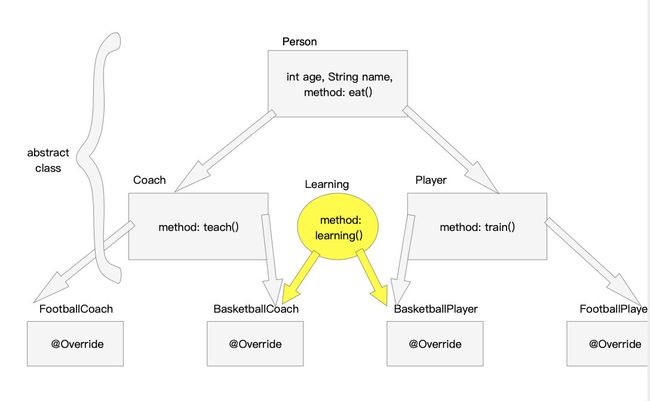
27.5 例题

28 包
包(package)就是文件夹,用来对类进行分类管理的,例如
- 学生的增加,删除,修改,查询
- 老师的增加,删除,修改,查询
- 其他类的增删改查
- 基本的划分:按照模块和功能划分
- 高级的划分
28.1 格式
package 包名1.包名2.包名3
package语句必须是程序的第一条可执行代码
package在一个程序中只能有一个
28.2 package, import, class三者在一个程序中的顺序
Package必须放在java文件的第一行有效代码处,且一个.java文件只有一个package
import表示导包,可以写多个,必须写在package和class之间
class表示在定义类,写在import后,建议只写一个
28.3 常见分类
- 按照功能分
- edu.hust.add
- AddStudent.java
- AddTeacher.java
- edu.hust.delete
- DeleteStudent.java
- DeleteTeacher.java
- edu.hust.update
- edu.hust.read
- edu.hust.add
- 按照模块分
- edu.hust.student
- AddStudent.java
- DeleteStudent.java
- edu.hust.teacher
- AddTeacher.java
- DeleteTeacher.java
- edu.hust.student
28.4 导包
不同包下的类之间的访问,都需要加包的全路径。解决方法是导包。
28.5 格式
import 包名;
- import java.util.* 导入java.util包下所有类,这样效率低不推荐
- import java.util.Scanner 导入java.util.Scanner类,推荐使用
28.6 注意事项
- java.lang包下的类可以直接使用,无需导入,如果使用其他包下的类,则必须先导包
- 用public修饰的类叫公共类,也叫顶级类。在一个.java文件中只能有一个顶级类,必须和文件名一致
- 全类名=包名+类名
29 权限修饰符
权限修饰符是用来修饰类、成员变量、构造方法、成员方法的,不同的权限修饰符对应的功能不同
| public | protected | 默认 | private | |
|---|---|---|---|---|
| 同一个类中 | √ | √ | √ | √ |
| 同一个包中的子类或者其他类 | √ | √ | √ | |
| 不同包中的子类 | √ | √ | ||
| 不同包中的其他类(无关类) | √ |
30 集合
集合是用来存储多个同类型数据的容器,其长度可变。
长度固定用数组,长度可变用集合。
集合的类别
集合分为Collection和Map。
集合的顶层都是接口。其中Collection是单列集合的顶层接口,Map接口是双列集合的顶层接口。
学习思路:学顶层,用底层。
顶层:是整个继承体系的共性内容
底层:具体的体现和实现
Collection:单列集合的顶层接口
- List:有序,可重复
ArrayList:
LinkedList:
Vector - Set:无序,唯一
HashSet:
TreeSet - Map:双列集合的顶层接口
HashMap:
HashTable
TreeMap
Collection集合
因为Collection是接口,不能用new关键字来创建。通过多态的方式创建其子类对象。
Collection<String> list = new ArrayList<String>();
泛型
概述:指某种特定的数据类型
作用:泛型一般是结合集合来一起使用的,用来限定集合中存储什么类型的数据
注意事项:1.前后泛型必须保持一致。2.后边的泛型可以不写,这是jdk1.7的新特性,叫菱形泛型。
例如
List<String> list = new ArrayList<>();
public class Demo01 {
public static void main(String[] args) {
Collection<String> list = new ArrayList<String>();
//或者Collection list = new ArrayList();
list.add("Hello");
list.add("World");
System.out.println(list);
}
}
Collection集合的方法
public boolean add(E e)添加元素//E指泛型
public boolean remove(Object obj)从集合中移除指定的元素
public void clear()清空集合
public boolean contains(Object obj)判断集合中是否包含指定的元素
public boolean isEmpty()判断集合是否为空
public int size()获取集合的长度
范型的小技巧:范型一般用字母E,T,K,V表示。E:Element;T:Type;Key Value
Iterator遍历集合
Iterator 是依赖集合存在,集合遍历的方式
public Iterator<E> iterator()//根据集合对象,获取其对应的迭代器对象
因为Iterrator是接口,所以在这里返回的是Iterator接口的子类对象。
迭代器是依赖于集合而存在的。
Iterator迭代器中的方法
public boolean hasNext()//判断迭代器中是否有下个元素
public E next()//获取迭代器中的下一个元素
public static void main(String[] args) {
Collection<String> coll = new ArrayList<>();
coll.add("Hello");
coll.add("World");
Iterator<String> it = coll.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
}
打印结果
Hello
World
总结:
集合遍历的使用分为四大步三小步
1.创建集合对象
2.创建元素对象
3.把元素对象添加到集合对象中
4.遍历集合
1.根据集合对象获取其对应的爹太器
2.判断迭代器中是否有下一个
3.有则获取
List集合
有序集合(俗称序列),该界面的用户可以精准控制列表中每个元素的插入位置,且用户可以通过整数索引(列表中的位置)访问元素,并搜索列表中的元素。与Collection集合不同,列表通常允许重复的元素。
简单记忆:有序,可重复,元素有索引
List集合特有的成员方法
void add(int i, E element)//使index为i的位置插入element
E set(int i, E element) //修改指定索引处的元素指定的值,并返回修改前的元素
E remove(int i)//根据索引移除指定元素,并返回此元素
E get(int i)//根据索引,获得相应的元素
遍历List集合:
- 增强for
- 通过for循环+size()+get()的形式,遍历List集合
快捷键:itli
列表迭代器 ListIterator
列表迭代器指的是ListIterator接口,它是List集合特有的迭代器
该迭代器继承了Iterator迭代器,所以我们可以直接使用
ListIterator<E> listIterator()
ListIterator<E> listIterator(int index)
成员方法:
boolean hasPrevious();
E previous();
int nextIndex();
int previousIndex();
List<String> list = new ArrayList<>();
list.add("Hello");
list.add("World");
list.add("Java");
//通过ListIterator正向遍历
ListIterator<String> it = list.listIterator();
while(it.hasNext()){
String s = it.next();
System.out.println(s);
}
//逆向遍历
while(it.hasPrevious()){
String s = it.previous();
System.out.println(s);
}
并发修改异常
当使用普通迭代器(Iterator)遍历集合的同时,又往集合中添加了元素,就会报并发修改异常。
List<String> list = new ArrayList<>();
list.add("Hello");
list.add("World");
list.add("Java");
Iterator<String> it = list.iterator();
while(it.hasNext()){
String s = it.next();
if("World".equals(s)){
it.add("JavaSE");//会报错并发修改异常
}
}
产生原因:
迭代器是依赖于集合而存在,当判断成功后,集合中添加了新的元素,而迭代器不知道,所以报错了。(计数器会计算剩下的元素个数,所以add报错而remove不报错)本质是,迭代器遍历集合中的元素是,不能使用集合对象去修改集合中的元素。
解决方案:
- 通过列表迭代器(ListIterator)解决
List<String> list = new ArrayList<>();
list.add("Hello");
list.add("World");
list.add("Java");
ListIterator<String> it = list.listIterator();
while(it.hasNext()){
String s = it.next();
if("World".equals(s)){
it.add("JavaSE");
}
}
- 通过for循环+size()方法解决
List<String> list = new ArrayList<>();
list.add("Hello");
list.add("World");
list.add("Java");
for(int i=0; i<list.size(); i++){
if("World".equals(list.get(i))){
list.add(i+1, "JavaSE");
}
}
for (int i = 0; i < list.size(); i++) {
String s = list.get(i);
System.out.println(s);
}
- 通过CopyOnWriteArrayList集合解决(它的底层已经解决了这个问题)
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
list.add("Hello");
list.add("World");
list.add("Java");
Iterator<String> it = list.iterator();//普通迭代器
while(it.hasNext()){
if("World".equals(it.next())){
list.add("JavaSE");//并发
}
}
面试题
什么是并发修改异常,怎么产生的,怎么解决
ConcurrentModificationException
增强for
增强for是JDK1.5的新特性,它是用来简化数组和Collection集合的遍历。
for(元素的数据类型 变量名:数组或Collection集合中的每一个元素)
for(int a: array)
for(Student l:list)
注意事项:数组或Collection集合不能为null;增强for的底层是迭代器
for(String elem : list){ }
常见的数据结构
数组:查询快,增删慢
链表:查询慢,增删快
List集合的子类(ArrayList和LinkedList)
List集合是一个接口,它的常用子类有两个ArrayList和LinkedList。
ArrayList的底层数据结构是数组,查询快,增删慢
LinkedList的底层数据结构是链表,查询慢,增删快
相同点:都是有序可重复的
LinkedList特有方法
void addFirst(E element)
void addLast(E element)
往链表的开头或末尾插入制定元素
E removeFirst()
E removeLast()
删除链表的开头或末尾元素,并返回这个元素
E getFirst()
E getLast()
返回链表的开头或末尾元素
Set集合
Set集合是Collection集合的子体系,它的元素特点是无序、唯一
- Set集合是一个接口,所以不能通过new的方式直接创建对象
- Set集合中没有带索引的方法,不能通过普通for进行遍历
- Set集合的常用子类有两个HashSet集合和TreeSet集合。
Set<String> set = new HashSet<>();//实际使用不用Set,直接用HashSet
set.add("Hello");
set.add("Java");
set.add("Hello");
for(String s : set){
System.out.println(s);
}
Java
Hello
HashSet集合
- 底层数据结构是哈希表
- 对集合的迭代顺序不做保证
- 没有带索引的方法
- 不包含重复的元素
总结:无序,唯一,元素无索引。底层数据结构是哈希表
HashSet<String> set = new HashSet<>();
set.add("Hello");
set.add("Java");
set.add("World");
for(String s : set){//遍历法1:增强for循环
System.out.println(s);
}
Iterator<String> it = set.iterator();
while(it.hasNext()){//遍历法2:普通迭代器
System.out.println(it.next());
}
LinkedHashSet集合
- 底层数据结构是哈希表+链表
- 保证元素有序
- 保证元素唯一
总结:有序,唯一。
可变参数
可变参数又称参数个数可变,它用作方法的形参出现,那么方法参数个数就是可变的了。
格式
修饰符 返回值类型 方法名(数据类型... 变量名){}
- 可变参数的底层是一个数组
- 如果一个方法有多个参数,将可变参数放在形参列表的最后。
public static void main(String[] args) {
System.out.println(getSum(1,2,3));
}
public static int getSum(int... nums){
return Arrays.stream(nums).sum();//可变参数的底层是数组
}
Map集合
public interface Map<K,V>{}
特点:
- 键具有唯一性,值可以重复
- 双列集合的数据结构只针对于键有效
- Set集合底层依赖的是Map集合
成员方法:
public V put (K key, V value)