基于商品的协同过滤推荐算法与预测评分实践【matlab实现】
正如昨天所介绍的,我们之前介绍了基于用户的协同过滤推荐算法,但是这种算法存在一种重大缺陷,即:
我们计算的用户相似度是历史记录中的“老客户”,这种推荐算法对新注册用户,或者缺少行为记录的用户是极其不友好的,因为无法计算与其相似的用户,因而不能进行个性化推荐,因此,我们从商品的相似度出发,解决用户冷启动问题。


现在简单介绍基于基于商品的协同过滤推荐算法:
基于用户的协同过滤基本思想非常简单,就是找到志同道合的朋友,并把朋友感兴趣的而用户没有接触过的商品推荐给用户。
但是这有一个问题,由于新用户的注册量非常高,基于用户的协同过滤推荐需要计算新用户和之前的用户之间的相似度,这会将数据稀疏,延展性差等问题暴露的非常明显。
所以基于商品的协同过滤方法被提出,相较于用户之间的相似度,商品之间的相似度相对是静态的,当新用户注册并有了一些自己感兴趣的商品信息时,无需再进行计算,直接根据之前存储的商品之间的相似度,将用户可能感兴趣的商品推荐给用户。

可以看出基于商品的协同过滤推荐算法也是分为两步,第一步是根据数据库中已有的信息求出商品的相似度,第二步是利用求出的商品之间的相似度计算用户对某种商品可能的兴趣程度。
商品之间的相似度可以利用皮尔逊相似度,余弦相似度或是改进的余弦相似度来进行计算。
皮尔逊相似度:
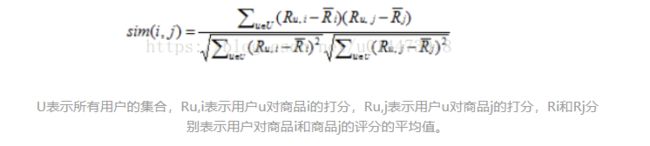
至于数据集,与昨日所采用的的数据集一致
我们要将得到的数据进行预处理,过程与昨日的相同。
%%1.数据读取
clc
clear all
[data1,~]=xlsread('user_order .xlsx','Sheet1','A2:C100001');%读取按照用户id排序的表格
[data2,~]=xlsread('movies_order.xlsx','Sheet1','A2:C100001');%读取按照电影id排序的表格
[row_data1,column_data1]=size(data1);
[row_data2,column_data2]=size(data2);
number_users=data1(row_data1,1);%读取有多少个用户
number_movies=data2(row_data2,2);%读取有多少个电影
users_ratings=zeros(number_users,number_movies);
%%2.转化为用户评分矩阵
User_sig=1;%设计其为标记
j=1;
for i=[1:1:row_data1]
if data1(i,1)==User_sig
users_ratings(User_sig,data1(i,2))=data1(i,3);
else
User_sig=User_sig+1;
users_ratings(User_sig,data1(i,2))=data1(i,3);
end
end
%%3.计算相似度矩阵
Sim=zeros(number_movies,number_movies);
for i=[1:1:number_movies]
for j=[1:1:number_movies]
if i==j
Sim(i,j)=1;
end
end
end
adv_item=zeros(1,number_movies);
for j=[1:1:number_movies]
adv_item(1,j)=sum(users_ratings(:,j));
end
for j=[1:1:number_movies]
adv_item(1,j)=adv_item(1,j)/number_users;
end
%上述过程是为了计算各个商品的平均分
users_ratings_subtraction=users_ratings;
for j=[1:1:number_movies]
users_ratings_subtraction(:,j)=users_ratings_subtraction(:,j)-adv_item(1,j);
end
%设置被减矩阵,方便计算
%由于一下子计算Sim不是很容易,因此我打算先算分子,再算分母
for i=[1:1:number_movies]
for j=[i+1:1:number_movies]
for k=[1:1:number_users]
Sim(i,j)=Sim(i,j)+users_ratings_subtraction(k,i)*users_ratings_subtraction(k,j);
end
end
end
for i=[1:1:number_movies]
for j=[1:1:number_movies]
Sim(j,i)=Sim(i,j);
end
end
%因为可能存在负数,因此要将分子绝对值化(因为向量的符号只代表方向)
for i=[1:1:number_movies]
for j=[1:1:number_movies]
Sim(i,j)=abs(Sim(i,j));
end
end
for i=[1:1:number_users]
for j=[1:1:number_movies]
users_ratings_subtraction(i,j)=users_ratings_subtraction(i,j)^2;
end
end
%计算平方分母阵,依然是为了简便计算
Sim_denominator=zeros(number_movies,number_movies);
for i=[1:1:number_movies]
for j=[1:1:number_movies]
if i==j
Sim_denominator(i,j)=1;
end
end
end
for i=[1:1:number_movies]
for j=[i+1:1:number_movies]
Sim_denominator(i,j)=sqrt(sum(users_ratings_subtraction(:,i))*sum(users_ratings_subtraction(:,j)));
end
end
for i=[1:1:number_movies]
for j=[1:1:number_movies]
Sim_denominator(j,i)=Sim_denominator(i,j);
end
end
%最后计算相似度
for i=[1:1:number_movies]
for j=[1:1:number_movies]
Sim(i,j)=Sim(i,j)./Sim_denominator(i,j);
end
end
for i=[1:1:number_users]
for j=[1:1:number_movies]
s=sum(Sim(:,j));
if users_ratings(i,j)==0;
for k=[1:1:number_movies]
users_ratings(i,j)=users_ratings(i,j)+Sim(k,j)*users_ratings(i,k);
end
users_ratings(i,j)=users_ratings(i,j)./s;
end
end
end由此,我们得到了商品相似度矩阵。

以及预测评分
