JAVA混合使用函数式接口(BiPredicate和Consumer)、泛型、lambda表达式、stream流,优化List求交集和差集后的通用处理

文章目录
- 前言
- 项目场景
- 两个List求交集和差集
- BiPredicate和Consumer基本介绍
- 优化目标
- 一步步优化代码
- 最后
前言
本文主要讲的是一个小的功能代码的优化案例,用到的知识点主要包括函数式接口(BiPredicate和Consumer)、泛型、lambda表达式、stream流。主要目的是提高代码质量,减少 “流水账” 的重复代码,提高可读性和可维护性。实现的功能是:对比两个嵌套List,求交集和差集,并对交集和差集做对应的消费处理。希望能以此抛转引玉,扩展大家使用 函数式接口的场景。
项目场景
项目场景比较像俄罗斯套娃,我用例子模拟的类嵌套关系如下:
A1里有List
A2里有List
@Data
public class A1 {
private Integer id;
// 其它字段...
private List<B1> b1List;
@Data
public static class B1 {
private Integer id;
// 其它字段...
private List<C1> c1List;
@Data
public static class C1 {
private Integer id;
// 其它字段...
private List<D1> d1List;
@Data
public static class D1 {
private Integer id;
// 其它字段...
}
}
}
}
实际情况是:A1 a1是前端调用API的参数对象, A2 a2是后端获取的数据库对象,然后对比a1和a2(包括对比嵌套的List中的对象),凡是a1比a2少则新增,多则删除。
为什么会有这么变态的需求?
实际这是一个设计问题:产品和交互的设计。常规做法是界面的操作都会直接调用后端API,但这个案例有点特殊:界面上的操作不直接调用API,而是仅当点击【保存】按钮时才提交API,前端传给后端的是最终操作结果,所以后端需要对比处理界面最新结果与数据库结果,从而得到上面提到的逻辑。
两个List求交集和差集
咱们先实现功能,再谈代码如何优化!
如下图,交集和差集简单带一下,我们要做的是:根据集合A和集合B得到以下3个集合,然后做对应处理!
集合A和集合B的交集:5,6集合A独有:集合C集合B独有:集合D
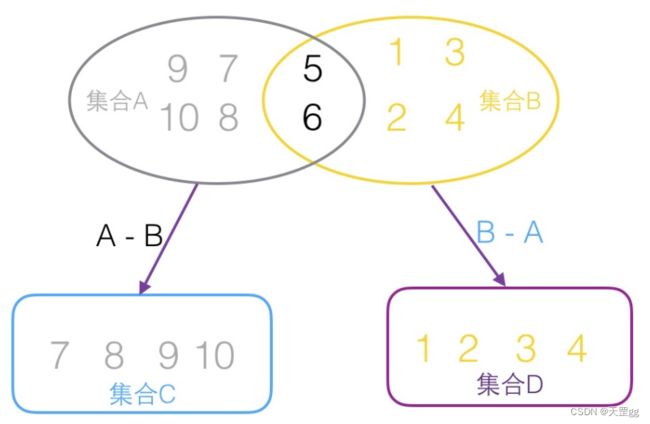
实现例子是对象,不是简单的数字,另外因为是不同对象类型,所以我们需要明确一下不同对象类型如何“相等”,这里的“相等”是指:id相等即对象相等: p1.getId().equals(p2.getId())。
处理方式,可以使用stream方式,也可以使用传统的for循环,因为stream方式更简洁,所以推荐使用。
求集合A(aList)和集合B(bList)的交集,2个stream代替2个for循环,filter是过滤,anyMatch是有任意匹配
// 循环aList, 过滤出id在bList里的对象
aList.stream().filter(p1 -> bList.stream().anyMatch(p2 -> p1.getId().equals(p2.getId())))
求aList独有的,不在bList中的,noneMatch是没有任何匹配,与anyMatch刚好相反
// 循环aList, 过滤出id不在bList里的对象
aList.stream().filter(p1 -> bList.stream().noneMatch(p2 -> p1.getId().equals(p2.getId())))
求bList独有的,不在aList中的,和上例类似:
// 循环bList, 过滤出id不在aList里的对象
bList.stream().filter(p1 -> aList.stream().noneMatch(p2 -> p1.getId().equals(p2.getId())))
BiPredicate和Consumer基本介绍
凡是带有@FunctionalInterface注解的接口都属于函数式接口,主要作用是可以将方法当做方法的参数,并且可以被隐式转换为 lambda 表达式,所以很常用,这里主要使用BiPredicate和Consumer:
-
BiPredicate 两个参数的断言,返回boolean类型,原型:
boolean test(T t, U u);这里主要用于
断言两个对象是否相等,所以只需要1个BiPredicate -
Consumer 消费一个对象参数,原型:
void accept(T t);这里主要用于
消费结果,因为最终有3个集合,所以需要3个Consumer
优化目标
从上面的代码,我们就可以求出交集和差集,也就很容易写出具体实现的代码,但是如果不加任何技巧的话,可能写出的就会是“流水账”代码,不仅长,还带有大量的类似代码,在CV开发时一不小心就容易写错,写完自测、修改、维扩等都是很不好的体验。所以,我们优化一下代码,提高可读性和可维护性,这里定2个目标:
-
目标1:对现有定义好的类对象无侵入,像类A1,A2,B1,B2,C1,C2,D1,D2
-
目标2:通用,不能写死类型,也不能写死要对比的字段;
一步步优化代码
先定义通用方法,这里为了通用就需要使用泛型方法,因为是两个List,所以定义两个类型:T1, T2。
方法需要的参数:
- 2个List:aList,bList
- 1个BiPredicate:isEqualPredicate,用于判断T1和T2是否相等
- 3个Consumer:用于消费得到的3个集合
最终方法定义如下:
public <T1, T2> void compareList(List<T1> aList, List<T2> bList
, BiPredicate<T1, T2> isEqualPredicate
, Consumer<List<T1>> onlyAListHaveConsumer
, Consumer<List<T2>> onlyBListHaveConsumer
, Consumer<List<T1>> bothHaveConsumer) {
}
方法没有返回值,主要是处理Consumer。
结合上面的基础代码,我们先实现一个 集合A独有的Consumer: onlyAListHaveConsumer
if (onlyAListHaveConsumer != null) {
// aList独有的,不在bList中的
List<T1> onlyAListHaveList = aList.stream().filter(p1 ->
bList.stream().noneMatch(p2 -> isEqualPredicate.test(p1, p2)))
.collect(Collectors.toList());
if (onlyAListHaveList.size() > 0) {
onlyAListHaveConsumer.accept(onlyAListHaveList);
}
}
一共就2步:过滤出onlyAListHaveList,再调用onlyAListHaveConsumer.accept(onlyAListHaveList)
同理,完整的通用封装代码如下:
public <T1, T2> void compareList(List<T1> aList, List<T2> bList
, BiPredicate<T1, T2> isEqualPredicate
, Consumer<List<T1>> onlyAListHaveConsumer
, Consumer<List<T2>> onlyBListHaveConsumer
, Consumer<List<T1>> bothHaveConsumer) {
if (onlyAListHaveConsumer != null) {
// aList独有的,不在bList中的
List<T1> onlyAListHaveList = aList.stream().filter(p1 ->
bList.stream().noneMatch(p2 -> isEqualPredicate.test(p1, p2)))
.collect(Collectors.toList());
if (onlyAListHaveList.size() > 0) {
onlyAListHaveConsumer.accept(onlyAListHaveList);
}
}
if (onlyBListHaveConsumer != null) {
// bList独有的,不在aList中的
List<T2> onlyBListHaveList = bList.stream().filter(p2 ->
aList.stream().noneMatch(p1 -> isEqualPredicate.test(p1, p2)))
.collect(Collectors.toList());
if (onlyBListHaveList.size() > 0) {
onlyBListHaveConsumer.accept(onlyBListHaveList);
}
}
if (bothHaveConsumer != null) {
// aList和bList的交集
List<T1> bothHaveList = aList.stream().filter(p1 ->
bList.stream().anyMatch(p2 -> isEqualPredicate.test(p1, p2)))
.collect(Collectors.toList());
if (bothHaveList.size() > 0) {
bothHaveConsumer.accept(bothHaveList);
}
}
}
调用的代码如下:
private void compareAndUpdateB(List<A1.B1> b1List, List<B2> b2List) {
compareList(b1List, b2List, (p1, p2) -> p1.getId().equals(p2.getId())
, onlyB1HaveList -> {
// 具体处理代码
}, onlyB2HaveList -> {
// 具体处理代码
}, bothHaveList -> {
// 具体处理代码
});
}
这里也可以将每个consumer单独提成一个方法,然后传入方法,例如定义一下方法(与Consumer方法签名相同):
public void handleOnlyB1HaveList(List<A1.B1> onlyB1HaveList) {
// 具体逻辑
}
调用时传入this::handleOnlyB1HaveList,代码如下:
private void compareAndUpdateB(List<A1.B1> b1List, List<B2> b2List) {
compareList(b1List, b2List, (p1, p2) -> p1.getId().equals(p2.getId())
, this::handleOnlyB1HaveList
, onlyB2HaveList -> {
// 具体处理代码
}, bothHaveList -> {
// 具体处理代码
});
}
最后
函数式接口(Predicate、Consumer、Function、Supplier,以及相应扩展)、泛型、lambda表达式、stream流,这些在实际开发中非常常用,所以掌握它并灵活应用非常重要!有很多混合应用的场景,本文只以一个小的功能优化代码为例,希望能对大家有所帮助!
❤️ 博客主页:https://blog.csdn.net/scm_2008
❤️ 欢迎点赞 收藏 ⭐留言✏️ 如有错误敬请指正!
❤️ 本文由 天罡gg 原创,首发于 CSDN博客
❤️ 停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活