详解ASR语音标注场景下的VAD语音端点检测丨曼孚科技
20世纪50年代,人类开启了对机器语音识别的探索历程。
60年后的2016年,在深度神经网络技术的帮助下,机器语音识别的准确率第一次达到了与人类相近的水准,智能语音产品进入大规模商业化应用阶段。
目前,语音识别技术已深入日常生活的方方面面,语音助手、智能音箱、智能客服等都是较为典型的应用场景。未来随着IoT设备的逐渐普及,人机语音交互场景将向更多方向延伸,在识别精度、场景优化等层面,对语音识别技术提出了更高要求。
一.语音识别技术
语音识别技术又被称为“机器的听觉系统”,即通过特定方式将语音信号转换成相应的文本或命令,以供机器识别与学习,最终产出可实用语音算法模型的过程。
目前,常见的语音识别方法主要为模式匹配法。这种方法下,语音识别过程可分为两部分:
第一部分为训练阶段,将收集到的语音数据或特定用户的场景化语音数据,经标注处理,提取出特征矢量作为模板存入特定数据模型库中;
第二部分为识别阶段,将输入语音的特征矢量依次与数据模型库中模板进行特征比对,并将相似度最高者作为识别结果输出。
这套语音识别方法对数据库的“量级”要求较高,原因在于语音识别系统的准确度受诸多因素影响,包括但不限于不同说话人、说话方式、环境噪音、传输信道等。
提高系统鲁棒性,尽可能扩充数据模型库中特征矢量种类,使系统可以在不同应用环境、条件下均可以稳定运行且有效识别,是提升语音识别模型适配性的关键。
这就需要在数据库搭建环节,尤其是语音标注处理环节提供更为精准且覆盖场景更为多样的训练数据集。
二.VAD语音端点检测
一段语音数据经过处理后,会呈现出如下的波形曲线:
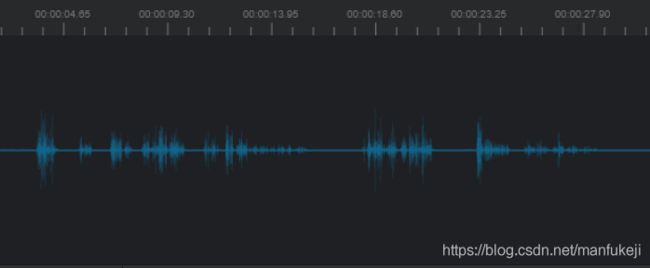
在这段语音数据中,不同的波动幅度代表着不同的情感特征。当波动幅度较大时,讲话者可能正处于情绪激动的状态中,音量会增加,音调也会发生改变;当波动幅度较小时,讲话者则可能处于情绪平和的状态中,音量会变小,语速也会变慢;而当无波动时,讲话者则处于沉默的状态。
因此,振幅的结构、发音的持续时间、说话速度等语音信号都是语音处理过程中需要着重关注的特征点。
在进行语音识别的过程中,系统的处理对象是有效语音信号,即有波动的部分,无波动的沉默部分因不具备语音信号所具备的特征点而需要被舍弃。
所以,在语音标注处理的过程中,往往需要从一段语音数据中找到语音部分的起点和终止点,从中抽取语音情感识别所需的信号特征,这样的“切分”过程就被称为语音端点检测,也即VAD。
VAD的英文全称为Voice Activity Detection,中文名称为语音活动检测、语音端点检测或语音边界检测、静音抑制等。
VAD处理的目的是从声音信号流里识别和消除长时间的静音期,将有效的语音信号和无用的语音信号或者噪音信号进行分离,以使后续的语音转写、语音情感分析等工作更加高效,是语音数据标注过程中常见的处理方式。
三.标注场景下的VAD
在语音标注,尤其是ASR语音转录标注场景下,VAD切片通常是需要率先完成的工作内容。
我们以曼孚科技SEED数据服务平台为例,详细展示在语音转录的标注场景下,如何完成VAD切片的处理。
SEED数据服务平台在语音标注模块下,提供手动与AI自动两种VAD切片处理方式。
手动模式下,标注员需要自行判断语音的起始点,并根据具体需求,决定是否预留相应的静默音部分,具体操作如下:

AI模式下,可一键自动处理整条数据,同时完成VAD自动切片与自动文本转录。目前,SEED数据服务平台在语音标注场景下提供的AI辅助为“全局辅助”,即AI会自动处理一整条数据,完成全部切片内容以及转录内容。
此外,AI辅助也会自行判断语音信号,并在切片前后预留一定的静默音部分,以供后续调整:

经过VAD切割处理后的语音数据,即可在此基础上完成下一步的语音转录处理。