李宏毅机器学习作业1-PM2.5预测
项目描述
- 本次作业的资料是从行政院环境环保署空气品质监测网所下载的观测资料。
- 希望大家能在本作业实现 linear regression 预测出 PM2.5 的数值。
数据集介绍
- 本次作业使用丰原站的观测记录,分成 train set 跟 test set,train set 是丰原站每个月的前 20 天所有资料。test set 则是从丰原站剩下的资料中取样出来。
- train.csv: 每个月前 20 天的完整资料。
- test.csv : 从剩下的资料当中取样出连续的 10 小时为一笔,前九小时的所有观测数据当作 feature,第十小时的 PM2.5 当作 answer。一共取出 240 笔不重複的 test data,请根据 feature 预测这 240 笔的 PM2.5。
- Data 含有 18 项观测数据 AMB_TEMP, CH4, CO, NHMC, NO, NO2, NOx, O3, PM10, PM2.5, RAINFALL, RH, SO2, THC, WD_HR, WIND_DIREC, WIND_SPEED, WS_HR。
数据集下载:
① 原始数据集 train.csv\rm train.csvtrain.csv 和 test.csv\rm test.csvtest.csv 文件
链接:https://pan.baidu.com/s/1_OtBbNJS2v3vIPbiaulNgQ
提取码:8i0u
② 重构后的数据集 r_train_X.csv\rmr\_train\_X.csvr_train_X.csv 和 r_ train_y.csv\rm r\_train\_y.csvr_train_y.csv
链接:https://pan.baidu.com/s/19A0YrxyBbmeRw9tAHDbaqA
提取码:6o5p
test_PM2.5预测01.py:进行数据集重构;
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import csv
#进行数据处理
data=pd.read_csv('./data/train.csv',encoding='big5')
# print(data)
data=data.iloc[:,3:] #去掉前三列的数据
#将 NR的数据替换为0
data[data == 'NR']=0
new_data=data.to_numpy() #转为numpy类型
# print(new_data.shape)
#按月重构数据,一个月有20天 x 24 =480个小时, 检测的指标有18个 就是够成18x480的数组;
"""
设置一个空字典来装一年12个月的数据, 设置一个空的列表装每个月的数据,列表里面是18x 180 数组;
"""
year_data={}
for month in range(12): #12个月;
month_data_list=np.empty([18,480]) #(18,480)
for day in range(20): #20天
month_data_list[:,day * 24 : (day + 1) * 24]=new_data[month * 18 * 20 + day * 18 :month * 18 * 20 +(day+1) * 18,:] #(4320,24)
# print(month_data_list)
year_data[month]=month_data_list # 一个月的数据添加进来
print(year_data[month])
#重构X,y
"""根据滑动创窗口,每连续的9个小时当做一个组, 一个月有480-9=471个数据"""
X_data=np.empty([12 * 471,18 * 9]) # 一共有12 * 417 行, 18 * 9列;
y_data=np.empty([12 * 471,1]) # 一共有12 * 417 行数据
for month in range(12):
for number in range(471):
X_data[month * 471 + number,:]=year_data[month][:,number: number +9].reshape(1,-1)
y_data[month * 471 + number]=year_data[month][9,number+9]
#写入数据,并保存数据:
with open('./data/x_train.csv',mode='w',newline='') as r_train_X:
csv_writer=csv.writer(r_train_X)
for i in range(12 * 471):
row=X_data[i][:] # 取一行数据
csv_writer.writerow(row)
with open('./data/y_train.csv',mode='w',newline='') as r_train_y:
csv_writer=csv.writer(r_train_y)
for i in range(12 * 471):
row=y_data[i]
csv_writer.writerow(row)
test_PM2.5预测02.py:构建模型,进行数据训练
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import math
#加载数据信息:
x_train_data=pd.read_csv('./data/x_train.csv',encoding='big5')
y_train_data=pd.read_csv('./data/y_train.csv',encoding='big5')
X=x_train_data.to_numpy()
Y=y_train_data.to_numpy()
# print(x)
# print("====================================")
# print(y)
#划分数据集和验证集: 7 :3
x_rows,x_clos=X.shape
# print(x_rows,x_clos)
#得到测试集和验证集的索引;
train_index=np.random.choice(np.arange(x_rows),size=math.floor(x_rows * 0.7),replace=False)
val_index=np.delete(np.arange(x_rows),train_index) #删除train_index,剩下的就都是验证集的数据;
#得到真正的测试集
x_train=X[train_index,:]
y_train=Y[train_index,:]
#得到真正的验证集
x_val=X[val_index,:]
y_val=Y[val_index,:]
"""数据标准化处理"""
mean_x=np.mean(x_train,axis=0) #得到训练集的每一列的平均值
std_x=np.std(x_train,axis=0) #得到每一列的方差
x_train=x_train-mean_x # (x-u)/std
x_train=x_train / std_x
x_val=x_val-mean_x
x_val=x_val / std_x
print(x_train.shape) #矩阵维度 3953 x 162
# f(x)= w*x + b 计算目标函数
m,dim =x_train.shape
dim=dim+1
m_val=len(x_val) #验证集的行数;
#在x_train前增加一列;b
x_train=np.concatenate([np.ones([len(x_train),1]),x_train],axis=1).astype(float)
#在x_val前增加一列;
x_val=np.concatenate([np.ones([len(x_val),1]),x_val],axis=1).astype(float)
#设置 w参数:
w=np.zeros([dim,1]) #设置 163 x 1的列向量;
iter_number=2500 #设置迭代次数;
learning_rate=0.01 #设置学习率
loss_history=np.zeros([iter_number,1]) #设置损失矩阵;
#f(x) = w*x + b
for i in range(iter_number):
#目标函数 : h(x)= w * x +b ---->将简化成y= X * w
f=np.dot(x_train,w)
f_hat=f-y_train #计算真实值与预测值之间的误差
#损失函数
loss=(1/(2 * m)) * np.sum(np.power(f_hat,2))
loss_history[i]=loss #存储损失值;
#每100次输出一次 loss值
if i % 100 ==0 :
print("第",str(i) ,"次loss value is:",str(loss))
# 计算梯度 梯度求导:1/m (f_hat-f) * x
gradient = (1 / m) * np.dot(x_train.T, f_hat)
w = w - learning_rate * gradient # 更新梯度 w= w- learning_rate * w
#得到预测值和最后的权重:w
y_predict=np.dot(x_val,w)
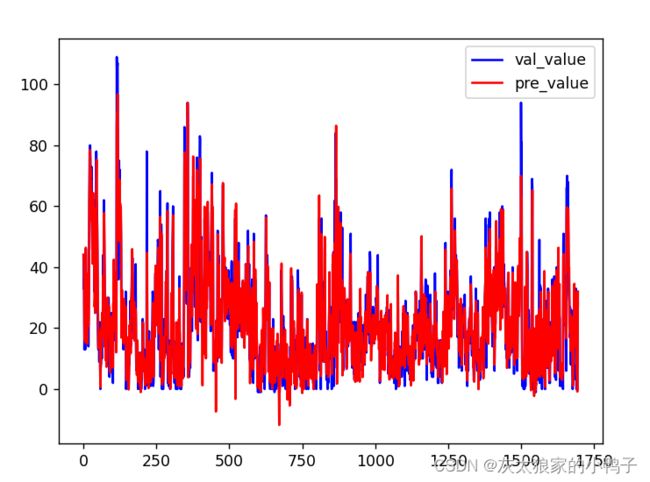
#预测值与真实之间的关系图像:
plt.plot(np.arange(len(y_val)),y_val,'b-',label='val_value')
plt.plot(np.arange(len(y_val)),y_predict,'r-',label='pre_value')
plt.legend()
plt.show()
# print(len(y_val))
# print(y_predict)
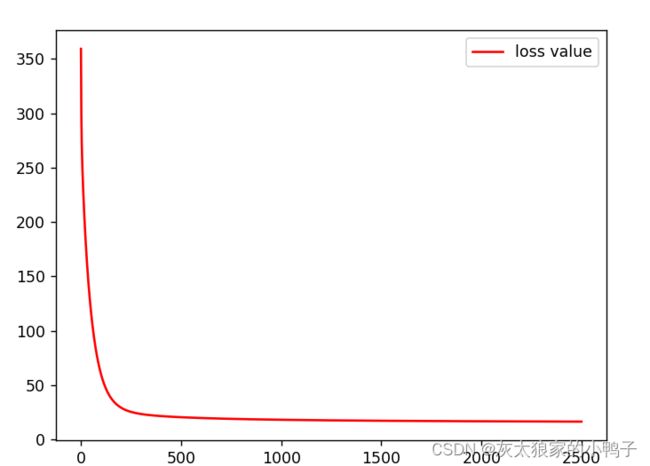
#绘制损失函数的图像:
item=np.arange(iter_number)
plt.plot(item,loss_history,'r-',label='loss value')
plt.legend()
plt.show()结果: