Seaborn 基本使用
文章目录
- 一、 Seaborn----绘制统计图形
-
- 1. 可视化数据的分布
- 2. 绘制单变量分布
- 3. 绘制双变量分布
-
- 3.1 绘制散点图
- 3.2 绘制二维直方图
- 3.3 绘制核密度估计图形
- 4. 绘制成对的双变量分布
- 5. 小结
- 二、用分类数据绘图
-
- 1 .类别散点图
- 2. 类别内的数据分布
-
- 2.1 绘制箱形图
- 2.2 绘制提琴图
- 3 类别内的统计估计
-
- 3.1 绘制条形图
- 3.2 绘制点图
- 4. 小结
一、 Seaborn----绘制统计图形
Matplotlib虽然已经是比较优秀的绘图库了,但是它有个今人头疼的问题,那就是API使用过于复杂,它里面有上千个函数和参数,属于典型的那种可以用它做任何事,却无从下手。
Seaborn基于 Matplotlib核心库进行了更高级的API封装,可以轻松地画出更漂亮的图形,而Seaborn的漂亮主要体现在配色更加舒服,以及图形元素的样式更加细腻。
不过,使用Seaborn绘制图表之前,需要安装和导入绘图的接口,具体代码如下:
# 安装
pip3 install seaborn
# 导入
import seaborn as sns
接下来,我们正式进入 Seaborn库的学习
若报错
OSError: Failed to open file b‘C:\\\...AppData\\Local\\Temp\\scipy-...’:https://blog.csdn.net/qq_42127961/article/details/123927453
1. 可视化数据的分布
当处理一组数据时,通常先要做的就是了解变量是如何分布的。
- 对于单变量的数据来说 采用直方图或核密度曲线是个不错的选择,
- 对于双变量来说,可采用多面板图形展现,比如 散点图、二维直方图、核密度估计图形等。
针对这种情况, Seaborn库提供了对单变量和双变 量分布的绘制函数,如 displot()函数、 jointplot()函数,下面来介绍这些函数的使用,具体内容如下:
2. 绘制单变量分布
可以采用最简单的直方图描述单变量的分布情况。 Seaborn中提供了 distplot()函数,它默认绘制的是一个带有核密度估计曲线的直方图。 distplot()函数的语法格式如下。
seaborn.distplot(a, bins=None, hist=True, kde=True, rug=False, fit=None, color=None)
上述函数中常用参数的含义如下:
-
(1) a:表示要观察的数据,可以是 Series、一维数组或列表。
-
(2) bins:用于控制条形的数量。
-
(3) hist:接收布尔类型,表示是否绘制(标注)直方图。
-
(4) kde:接收布尔类型,表示是否绘制高斯核密度估计曲线。
-
(5) rug:接收布尔类型,表示是否在支持的轴方向上绘制rugplot。
通过 distplot())函数绘制直方图的示例如下。
import numpy as np
sns.set()
np.random.seed(0) # 确定随机数生成器的种子,如果不使用每次生成图形不一样
arr = np.random.randn(100) # 生成随机数组
ax = sns.distplot(arr, bins=10, hist=True, kde=True, rug=True) # 绘制直方图
上述示例中,首先导入了用于生成数组的numpy库,然后使用 seaborn调用set()函数获取默认绘图,并且调用 random模块的seed函数确定随机数生成器的种子,保证每次产生的随机数是一样的,接着调用 randn()函数生成包含100个随机数的数组,最后调用 distplot()函数绘制直方图。
运行结果如下图所示。
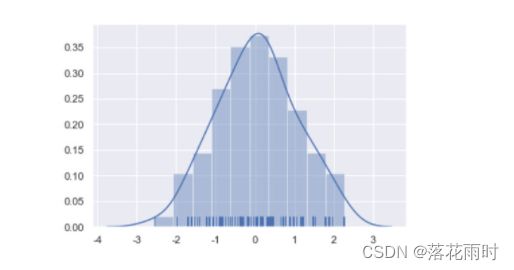
从上图中看出:
- 直方图共有10个条柱,每个条柱的颜色为蓝色,并且有核密度估计曲线。
- 根据条柱的高度可知,位于-1-1区间的随机数值偏多,小于-2的随机数值偏少。
通常,采用直方图可以比较直观地展现样本数据的分布情况,不过,直方图存在一些问题,它会因为条柱数量的不同导致直方图的效果有很大的差异。为了解决这个问题,可以绘制核密度估计曲线进行展现。
- 核密度估计是在概率论中用来估计未知的密度函数,属于非参数检验方法之一,可以比较直观地看出数据样本本身的分布特征。
通过 distplot()函数绘制核密度估计曲线的示例如下。
# 创建包含500个位于[0,100]之间整数的随机数组
array_random = np.random.randint(0, 100, 500)
# 绘制核密度估计曲线
sns.distplot(array_random, hist=False, rug=True)
上述示例中,首先通过 random.randint()函数返回一个最小值不低于0、最大值低于100的500个随机整数数组然后调用 displot()函数绘制核密度估计曲线。
运行结果如图所示。

从上图中看出,图表中有一条核密度估计曲线,并且在x轴的上方生成了观测数值的小细条。
3. 绘制双变量分布
两个变量的二元分布可视化也很有用。在 Seaborn中最简单的方法是使用 jointplot()函数,该函数可以创建一个多面板图形,比如散点图、二维直方图、核密度估计等,以显示两个变量之间的双变量关系及每个变量在单坐标轴上的单变量分布。
jointplot()函数的语法格式如下。
seaborn.jointplot(x, y, data=None,
kind='scatter', stat_func=None, color=None,
ratio=5, space=0.2, dropna=True)
上述函数中常用参数的含义如下:
- (1) kind:表示绘制图形的类型。
- (2) stat_func:用于计算有关关系的统计量并标注图。
- (3) color:表示绘图元素的颜色。
- (4) size:用于设置图的大小(正方形)。
- (5) ratio:表示中心图与侧边图的比例。该参数的值越大,则中心图的占比会越大。
- (6) space:用于设置中心图与侧边图的间隔大小。
下面以散点图、二维直方图、核密度估计曲线为例,为大家介绍如何使用 Seaborn绘制这些图形。
3.1 绘制散点图
调用 seaborn.jointplot()函数绘制散点图的示例如下。
import numpy as np
import pandas as pd
import seaborn as sns
# 创建DataFrame对象
dataframe_obj = pd.DataFrame({"x": np.random.randn(500),"y": np.random.randn(500)})
# 绘制散布图
sns.jointplot(x="x", y="y", data=dataframe_obj)
上述示例中,首先创建了一个 DataFrame对象 dataframe_obj作为散点图的数据,其中x轴和y轴的数据均为500个随机数,接着调用 jointplot0函数绘制一个散点图,散点图x轴的名称为“x”,y轴的名称为“y”。
运行结果如图所示。
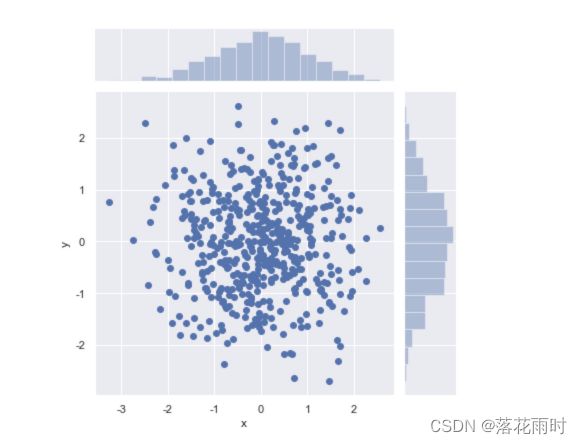
3.2 绘制二维直方图
**二维直方图类似于“六边形”图,主要是因为它显示了落在六角形区域内的观察值的计数,适用于较大的数据集。**当调用 jointplot()函数时,只要传入kind=“hex”,就可以绘制二维直方图,具体示例代码如下。
# 绘制二维直方图
sns.jointplot(x="x", y="y", data=dataframe_obj, kind="hex")
运行结果如图所示。
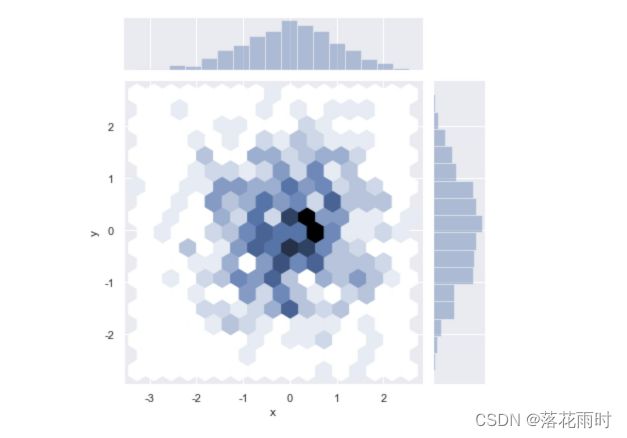
**从六边形颜色的深浅,可以观察到数据密集的程度,**另外,图形的上方和右侧仍然给出了直方图。注意,在绘制二维直方图时,最好使用白色背景。
3.3 绘制核密度估计图形
利用核密度估计同样可以查看二元分布,其用等高线图来表示。当调用jointplot()函数时只要传入ind=“kde”,就可以绘制核密度估计图形,具体示例代码如下。
sns.jointplot(x="x", y="y", data=dataframe_obj, kind="kde")
上述示例中,绘制了核密度的等高线图,另外,在图形的上方和右侧给出了核密度曲线图。
运行结果如图所示。

通过观等高线的颜色深浅,可以看出哪个范围的数值分布的最多,哪个范围的数值分布的最少
4. 绘制成对的双变量分布
要想在数据集中绘制多个成对的双变量分布,则可以使用pairplot()函数实现,该函数会创建一个坐标轴矩阵,并且显示Datafram对象中每对变量的关系。另外,pairplot()函数也可以绘制每个变量在对角轴上的单变量分布。
接下来,通过 sns.pairplot()函数绘制数据集变量间关系的图形,示例代码如下
# 加载seaborn中的数据集
dataset = sns.load_dataset("iris")
dataset.head()

上述示例中,通过 load_dataset0函数加载了seaborn中内置的数据集,根据iris数据集绘制多个双变量分布。
# 绘制多个成对的双变量分布
sns.pairplot(dataset)
结果如下图所示。
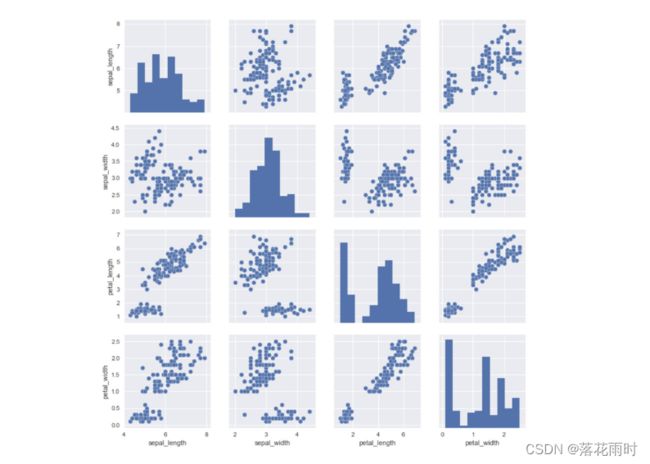
5. 小结
- seaborn的基本使用【了解】
- 绘制单变量分布图形【知道】
- seaborn.distplot()
- 绘制双变量分布图形【知道】
- seaborn.jointplot()
- 绘制成对的双变量分布图形【知道】
- Seaborn.pairplot()
二、用分类数据绘图
数据集中的数据类型有很多种,除了连续的特征变量之外,最常见的就是类别型的数据了,比如人的性别、学历、爱好等,这些数据类型都不能用连续的变量来表示,而是用分类的数据来表示。
Seaborn针对分类数据提供了专门的可视化函数,这些函数大致可以分为如下三种:
- 分类数据散点图: swarmplot()与 stripplot()。
- 类数据的分布图: boxplot() 与 violinplot()。
- 分类数据的统计估算图:barplot() 与 pointplot()。
下面两节将针对分类数据可绘制的图形进行简单介绍,具体内容如下
1 .类别散点图
通过 stripplot()函数可以画一个散点图, stripplot0函数的语法格式如下。
seaborn.stripplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, jitter=False)
上述函数中常用参数的含义如下
- (1) x,y,hue:用于绘制长格式数据的输入。
- (2) data:用于绘制的数据集。如果x和y不存在,则它将作为宽格式,否则将作为长格式。
- (3) jitter:表示抖动的程度(仅沿类別轴)。当很多数据点重叠时,可以指定抖动的数量或者设为Tue使用默认值。
为了让大家更好地理解,接下来,通过 stripplot()函数绘制一个散点图,示例代码如下。
# 获取tips数据
tips = sns.load_dataset("tips")
sns.stripplot(x="day", y="total_bill", data=tips)
运行结果如下图所示。
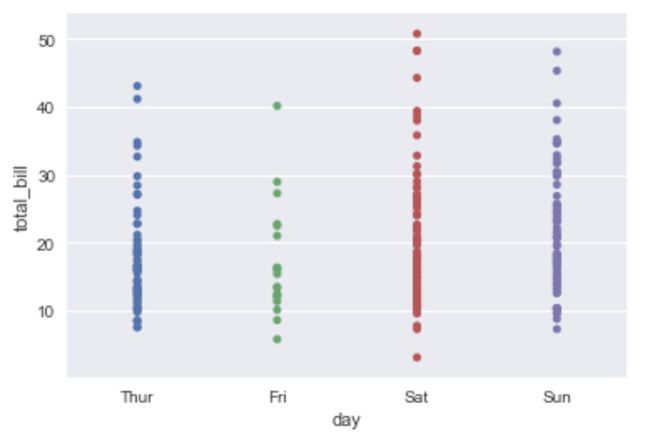
从上图中可以看出,图表中的横坐标是分类的数据,而且一些数据点会互相重叠,不易于观察。为了解决这个问题,可以在调用striplot()函数时传入jitter参数,以调整横坐标的位置,改后的示例代码如下。
sns.stripplot(x="day", y="total_bill", data=tips, jitter=True)
运行结果如下图所示。
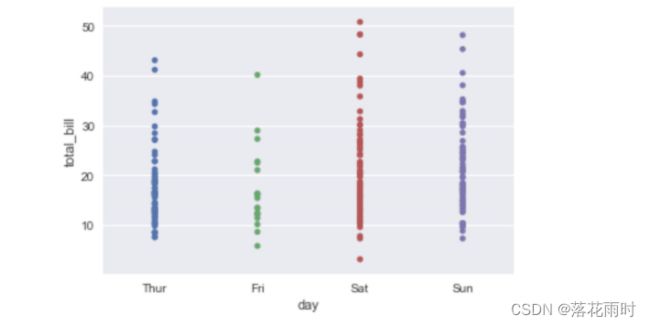
除此之外,还可调用 swarmplot0函数绘制散点图,该函数的好处是所有的数据点都不会重叠,可以很清晰地观察到数据的分布情况,示例代码如下。
sns.swarmplot(x="day", y="total_bill", data=tips)
运行结果如图所示。

2. 类别内的数据分布
要想查看各个分类中的数据分布,显而易见,散点图是不满足需求的,原因是它不够直观。针对这种情况,我们可以绘制如下两种图形进行查看:
- 箱形图:
- 箱形图(Box-plot)又称为盒须图、盒式图或箱线图,是一种用作显示一组数据分散情况资料的统计图。因形状如箱子而得名。
- 箱形图于1977年由美国著名统计学家约翰·图基(John Tukey)发明。它能显示出一组数据的最大值、最小值、中位数、及上下四分位数。

- 小提琴图:
- 小提琴图 (Violin Plot) 用于显示数据分布及其概率密度。
- 这种图表结合了箱形图和密度图的特征,主要用来显示数据的分布形状。
- 中间的黑色粗条表示四分位数范围,从其延伸的幼细黑线代表 95% 置信区间,而白点则为中位数。
- **箱形图在数据显示方面受到限制,简单的设计往往隐藏了有关数据分布的重要细节。**例如使用箱形图时,我们不能了解数据分布。虽然小提琴图可以显示更多详情,但它们也可能包含较多干扰信息。

接下来,针对 Seaborn库中箱形图和提琴图的绘制进行简单的介绍。
2.1 绘制箱形图
seaborn中用于绘制箱形图的函数为 boxplot(),其语法格式如下:
seaborn.boxplot(x=None, y=None, hue=None, data=None, orient=None, color=None, saturation=0.75, width=0.8)
常用参数的含义如下:
- (1) palette:用于设置不同级别色相的颜色变量。---- palette=[“r”,“g”,“b”,“y”]
- (2) saturation:用于设置数据显示的颜色饱和度。---- 使用小数表示
使用 boxplot()函数绘制箱形图的具体示例如下。
sns.boxplot(x="day", y="total_bill", data=tips)
上述示例中,使用 seaborn中内置的数据集tips绘制了一个箱形图,图中x轴的名称为day,其刻度范围是 Thur~Sun(周四至周日),y轴的名称为 total_bill,刻度范围为10-50左右
运行结果如图所示。

从图中可以看出,
- Thur列大部分数据都小于30,不过有5个大于30的异常值,
- Fri列中大部分数据都小于30,只有一个异常值大于40,
- Sat一列中有3个大于40的异常值,
- Sun列中有两个大于40的异常值
2.2 绘制提琴图
seaborn中用于绘制提琴图的函数为violinplot(),其语法格式如下
seaborn.violinplot(x=None, y=None, hue=None, data=None)
通过violinplot()函数绘制提琴图的示例代码如下
sns.violinplot(x="day", y="total_bill", data=tips)
上述示例中,使用seaborn中内置的数据集绘制了一个提琴图,图中x轴的名称为day,y轴的名称为total_bill
运行结果如图所示。

从图中可以看出,
- Thur一列中位于5~25之间的数值较多,
- Fri列中位于5-30之间的较多,
- Sat-列中位于5-35之间的数值较多,
- Sun一列中位于5-40之间的数值较多。
3 类别内的统计估计
要想查看每个分类的集中趋势,则可以使用条形图和点图进行展示。 Seaborn库中用于绘制这两种图表的具体函数如下
- barplot()函数:绘制条形图。
- pointplot()函数:绘制点图。
这些函数的API与上面那些函数都是一样的,这里只讲解函数的应用,不再过多对函数的语法进行讲解了。
3.1 绘制条形图
最常用的查看集中趋势的图形就是条形图。默认情况下, barplot函数会在整个数据集上使用均值进行估计。若每个类别中有多个类别时(使用了hue参数),则条形图可以使用引导来计算估计的置信区间(是指由样本统计量所构造的总体参数的估计区间),并使用误差条来表示置信区间。
使用 barplot()函数的示例如下
sns.barplot(x="day", y="total_bill", data=tips)
运行结果如图所示。
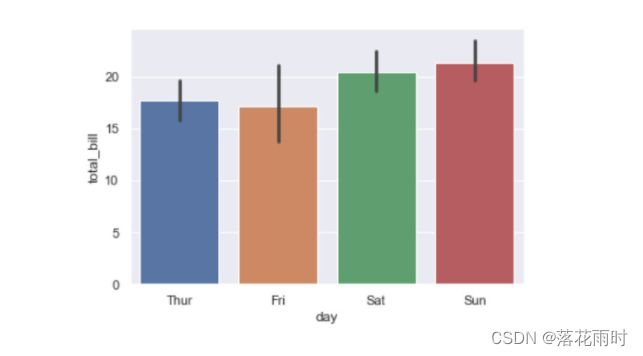
3.2 绘制点图
另外一种用于估计的图形是点图,可以调用 pointplot()函数进行绘制,该函数会用高度低计值对数据进行描述,而不是显示完整的条形,它只会绘制点估计和置信区间。
通过 pointplot()函数绘制点图的示例如下。
sns.pointplot(x="day", y="total_bill", data=tips)
运行结果如图所示。
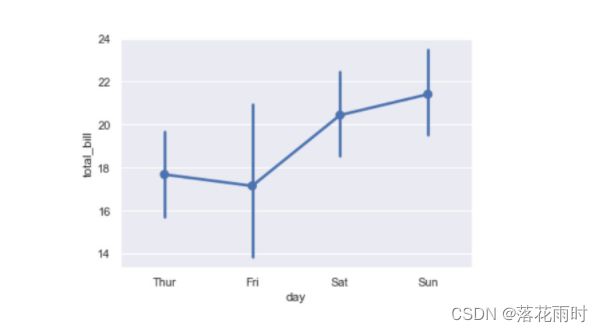
4. 小结
- 类别散点图
- seaborn.stripplot()
- 类别内的数据分布
- 箱线图
- seaborn.boxplot()
- 小提琴图
- seaborn.violinplot()
- 箱线图
- 类别内的统计估计
- 条形图
- barplot()
- 点图
- pointplot()
- 条形图