【论文简述】Multiview Stereo with Cascaded Epipolar RAFT(arxiv 2022)
一、论文简述
1. 第一作者:Zeyu Ma
2. 发表年份:2022
3. 发表期刊:arxiv
4. 关键词:MVS、RAFT、级联、极线
5. 探索动机:3D卷积在计算和内存方面成本很高,在有限资源条件下限制重建质量。
However, a drawback of MVSNet is that regularizing the 3D plane-sweeping cost volume using 3D convolutions can be costly in terms of computation and memory, potentially limiting the quality of reconstruction under finite resources. Subsequent variants of MVSNet have attempted to address this issue by replacing 3D convolutions with recurrent sequential processing of 2D slices. Despite significant empirical improvements, however, such sequential processing can be suboptimal because the 3D cost volume does not have a natural sequential structure.
6. 工作目标:结合RAFT结构,解决上述问题。
7. 核心思想:
- We propose CERMVS (Cascaded Epipolar RAFT Multiview Stereo), a new approach based on the RAFT (Recurrent All-Pairs Field Transforms) architecture developed for optical flow.
- CERMVS introduces five new changes to RAFT: epipolar cost volumes, cost volume cascading, multiview fusion of cost volumes, dynamic supervision, and multiresolution fusion of depth maps. CER-MVS is significantly different from prior work in multiview stereo. Unlike prior work, which operates by updating a 3D cost volume, CER-MVS operates by updating a disparity field.
- Furthermore, we propose an adaptive thresholding method to balance the completeness and accuracy of the reconstructed point clouds.
8. 实验结果:SOTA
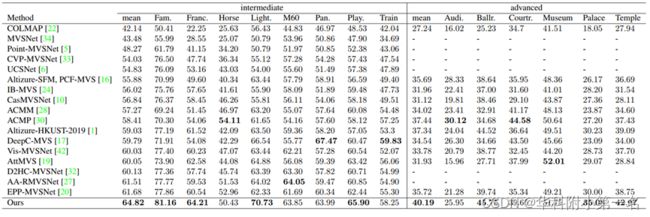
On DTU, CERMVS achieves performance competitive to the current state of the art (the second best among published results). On Tanks-and-Temples, CER-MVS significantly advances the state of the art of the intermediate set from a mean F1 score of 61:68 to 64:82, and the advanced set from 37:44 to 40:19.
9.论文&代码下载:
https://arxiv.org/pdf/2205.04502.pdf
http:// https://github.com/princeton-vl/CER-MVS
二、实现方法
1. CERMVS概述
CER-MVS的结构和流程如下图,给定参考视图和一组相邻视图:
- 使用一组卷积网络提取特征
- 使用特征构建级联极线代价体
- 通过循环迭代更新来预测视差(逆深度)图
- 融合多分辨率深度
- 所有参考视图的深度图融合以产生最终的点云
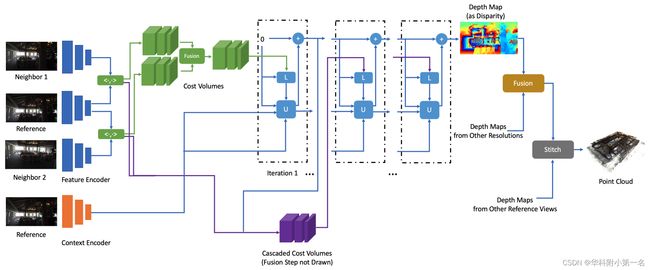
2. 代价体构建
图像特征。从参考视图和相邻视图中提取图像特征,来构造代价体;GRU需要来自参考视图的上下文特征。使用RAFT的卷积编码器: H×W×3→RH/2k×W/2k×Df,其中k和Df决定特征分辨率和维度的超参数。
极线代价体。提取特征图{fi,i = 0,……,N+1},其中f0是参考视图,其他是相邻视图,每个都有分辨率(Df,Hf,Wf) = (Df,H/2k,W/2k),通过计算参考视图中每个像素与相邻视图中沿其极线的像素之间的相关来构建3D代价体,输出一个体Cl∈N×Hf×Wf×D。
Specifically, for a pixel in the reference view, we backproject it to D 3D points with disparity (inverse depth) uniformly spaced in the range from 0 to dmax (after proper scaling as described in Sec. 4.1), reproject the 3D points to the epipolar line in the neighbor view, and
use differentiable bilinear sampling to retrieve the features from the neighbor view.
像RAFT一样,通过重复的平均池化计算多尺度代价体的CP,即CP={C0,C1,……,CL−1},其中Cl∈N×Hf×Wf×D/2l, l = 0,……,L-1。
代价体级联。与RAFT不同,极线代价体的大小不仅取决于图像分辨率,还取决于采样的视差值的数量。大量视差值的密集采样有效地提高了代价体沿深度维度的分辨率,有助于重构精细细节。然而,使用大量的视差值会占用太多的GPU内存。因此引入了级联设计。基本思想是以当前视差预测为中心沿着视差维度构建粒度更细的额外代价体。
具体来说,在T1迭代更新之后,构建了一个新的代价体堆栈,CfP={Cf0,Cf1,……,CfL−1},其中Cfl∈N×Hf×Wf×Df/2l, l = 0,……,L-1,其中Df是均匀采样的视差值的数量,以当前预测的视差为中心,增量小于在初始代价体堆栈中使用的增量。具体地说,Df的值由2L−1*R决定,其中R是控制邻域大小的超参数,因子2L−1进行重复池化。在实验中使用了2个阶段,但设计可以简单地扩展到更多阶段。这与以前的MVS工作有很大的不同,因为代价体不被更新,只被作为静态查找表。
3. 迭代更新
迭代更新在整体结构上遵循RAFT。迭代更新初始化为零的视差场d∈Hf×Wf。在每次迭代中,更新算子的输入包括隐藏状态h∈Hf×Wf×Dh、当前视差场、来自参考视图的上下文特征i∈Hf×Wf×Dh,以及使用当前视差场从代价体中检索到的像素特征。更新算子的输出包括一个新的隐藏状态和视差场的增量。
代价体的多视图融合。不同于RAFT,在MVS中,需要考虑多个相邻视图。对于参考视图中的每个像素,针对每个邻居视图生成一个相关特征向量。给定来自多个邻居视图的这样的特征向量,将元素的均值作为最终向量。这个操作符背后的直觉是,平均值更健壮,因为邻居视图的数量可以在测试时间内变化。
为了针对单个邻居视图为每个像素生成相关特征向量,执行与RAFT相同的查找过程。给定像素的当前视差估计和相对于邻居视图的代价体堆栈CP={C0,C1,……,CL−1},从每个代价体中检索对应于以当前视差为中心的长度为R的局部1D整数网格的相关值。对于堆栈的每一层都重复这样做,来自所有层级的值被连接起来形成一个单一的特征向量。
更新算子。使用基于GRU的更新算子来对视差场提出一系列增量更新。
首先,从当前视差估计dt中提取特征。通过将每个像素的视差减去其7x7邻域,然后将结果重新塑造为49维向量,从而形成特征向量。这个操作的效果是使特征向量对视差场的不变性达到一个移位因子,因为检索到的向量只依赖于相邻像素之间的相对视差。
其次,因为有一个代价体的级联,并且更新算子在级联的不同阶段访问不同的代价体,尽管更新算子仍然是循环的,但被赋予灵活性,以便在级联的不同阶段有不同的行为。因此,修改RAFT的权重绑定方案,使一些权重在所有迭代中绑定,而另一些权重仅在级联的单个阶段中绑定。特别地,除了从GRU的隐藏状态解码视差更新的解码器层之外,在迭代中绑定了所有权重。解码层的权重仅在级联的每个阶段内绑定。
第三,RAFT使用上采样层对流场进行最终预测,而本文没有使用任何上采样层。
更新方程如下,第1阶段为2级联,迭代次数为T1。

这里i是上下文特征,Encoderc是一个使用两个卷积层转换相关特征的编码器。
4. 多分辨率深度融合
在高分辨率下操作通常有助于构造更精细的细节,但GPU内存限制了网络可以访问的最高分辨率,特别是在使用大型小批量训练时。绕过这一限制的一种方法是在推理过程中将网络应用到更高的分辨率,这是之前工作中采用的常见方法。
然而,文中发现虽然在推理过程中使用更高的分辨率可以有所帮助,但更好的方法是在两个输入分辨率上应用相同的网络,用于训练网络的“低”分辨率W × H和更高分辨率2W × 2H,并结合两个视差图LR和HR,形成具有控制参数t的融合视差图MR:
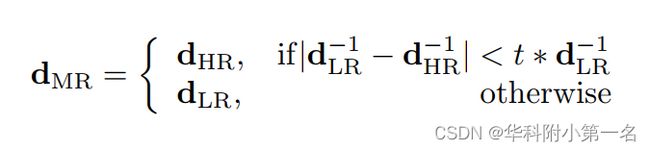
即,如果低分辨率预测和高分辨率预测在一个像素处相似,则使用高分辨率预测;否则我们使用低分辨率预测。这是由于观察到低分辨率的预测在没有纹理的大型结构(如平面)方面更可靠,而高分辨率的预测在细节方面更可靠,这些细节往往不会与低分辨率的预测有很大的偏差。注意,当控制参数t从0变化到无穷大时,dMR从dLR变化到dHR。
5. 自适应点云连接
作为最后一步,将来自参考视图的深度图连接在一起,形成单个点云。使用D2HC-RMVSNet中提出的基于动态一致性检查(DCC)的自适应阈值方法。DCC硬编码了重投影误差的两个阈值t1和t2,但是,使用阈值kt1和kt2,其中每个场景的k是不同的,以确保一个固定的百分比,所有像素的p%通过一致性测试。p通过验证集得到优化。
6. 监督
监督网络的损失由两部分组成。第一部分在每次迭代中测量预测视差相对于真实的L1误差,并在后续迭代中以指数级增加权重。这部分可以加快所有视差范围的训练,而不考虑开始时的异常值。损失的第二部分与第一部分相似,只是(1)测量深度的误差(即逆视差),以便更符合点云评估;(2)误差上限为常数κ,以防止异常值主导损失。
给定每次迭代的预测视差为dt,t =1,……,T1+T2和真实视差dgt,综合损失定义如下:
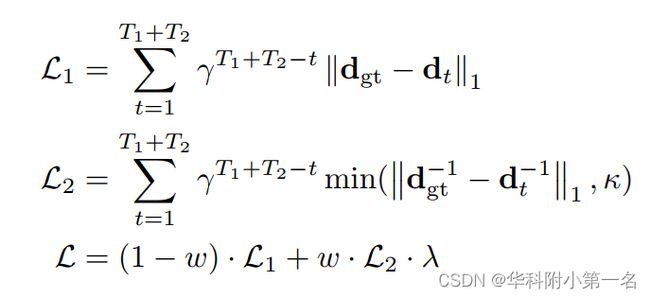
其中γ控制迭代中的权重,λ使两部分具有大致相同的范围。参数w平衡了这两个部分,并随着训练的进行线性地从0到1变化,以更加关注深度误差,例如,对于总共16个训练周期,当8个epoch结束时w为0.5。
7. 实验
7.1. 数据集
DTU Dataset、Tanks and Temples
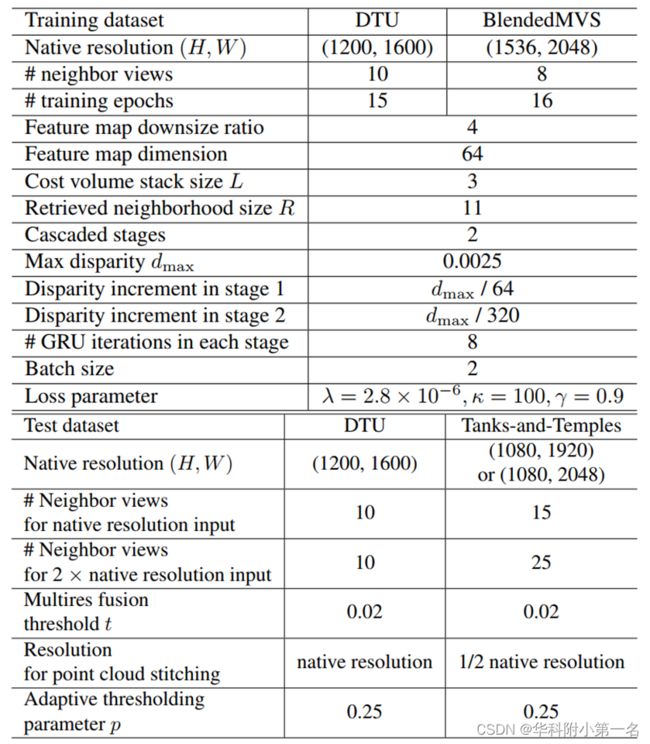
7.2. 实现
通过PyTorch实现,使用DTU数据集训练,在DTU上测试。在blenddmvs数据集上训练,在Tanks-and-Temples上测试。
没看懂,In BlendedMVS, which is used for training only, the scenes have large variations in the range of depth values, we scale each reference view, along with its neighbor views, so that its ground-truth depth has a median value 600 mm. When we evaluate on Tanks-andTemples, due to lack of ground-truth and noisy background, we scale each reference view, along with its neighbor views, so that its minimum depth of a set of reliable feature points (computed by COLMAP [22] as in MVSNet [34]) is 400 mm. To stitch the predicted depth maps from multiple reference views, we simply scale back each depth map to its original scale.
7.3. 基准结果
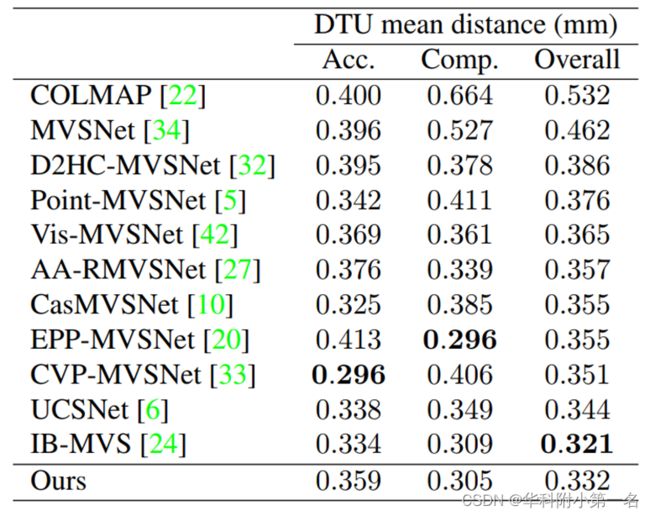
DTU数据集基准:SOTA
Tanks & Temples:SOTA