mysql 数据库字符集转换_字符集介绍及mysql数据库编码转换
一、字符集介绍:
1、ASCII
ASCII是英文American Standard Code for Information Interchange的缩写,美国标准信息交换代码是由美国国家标准学会(American National Standard Institute , ANSI )制定的,标准的单字节字符编码方案,用于基于文本的数据。是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。
其中:
0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符),如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(响铃)等;通信专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等;ASCII值为8、9、10 和13 分别转换为退格、制表、换行和回车字符。它们并没有特定的图形显示,但会依不同的应用程序,而对文本显示有不同的影响。
32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字
65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。

扩展ASCII 字符是从128 到255(0x80-0xff)的字符。
2、GBK
GBK即汉字内码扩展规范,K为扩展的汉语拼音中“扩”字的声母。英文全称Chinese Internal Code Specification。GBK编码标准兼容GB2312,共收录汉字21003个、符号883个,并提供1894个造字码位,简、繁体字融于一库。GB2312码是×××国家汉字信息交换用编码,全称《信息交换用汉字编码字符集——基本集》,1980年由国家标准总局发布。基本集共收入汉字6763个和非汉字图形字符682个,通行于中国大陆。新加坡等地也使用此编码。GBK是对GB2312-80的扩展,也就是CP936字码表 (Code Page 936)的扩展(之前CP936和GB 2312-80一模一样)。
3、latin1
Latin1是ISO-8859-1的别名,有些环境下写作Latin-1。
ISO-8859-1
ISO-8859-1编码是单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。
ISO-8859-1收录的字符除ASCII收录的字符外,还包括西欧语言、希腊语、泰语、阿拉伯语、希伯来语对应的文字符号。欧元符号出现的比较晚,没有被收录在ISO-8859-1当中。
因为ISO-8859-1编码范围使用了单字节内的所有空间,在支持ISO-8859-1的系统中传输和存储其他任何编码的字节流都不会被抛弃。换言之,把其他任何编码的字节流当作ISO-8859-1编码看待都没有问题。这是个很重要的特性,MySQL数据库默认编码是Latin1就是利用了这个特性。ASCII编码是一个7位的容器,ISO-8859-1编码是一个8位的容器。
4、UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码。由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到4个字节编码UNICODE字符。用在网页上可以同一页面显示中文简体繁体及其它语言(如日文,韩文)
UTF-8以字节为单位对Unicode进行编码。从Unicode到UTF-8的编码方式如下:Unicode编码(十六进制)UTF-8 字节流(二进制)
000000 - 00007F0xxxxxxx
000080 - 0007FF110xxxxx 10xxxxxx
000800 - 00FFFF1110xxxx 10xxxxxx 10xxxxxx
010000 - 10FFFF11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
UTF-8的特点是对不同范围的字符使用不同长度的编码。对于0x00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同。UTF-8编码的最大长度是4个字节。从上表可以看出,4字节模板有21个x,即可以容纳21位二进制数字。Unicode的最大码位0x10FFFF也只有21位。
例1:“汉”字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用用3字节模板了:1110xxxx 10xxxxxx 10xxxxxx。将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
例2:Unicode编码0x20C30在0x010000-0x10FFFF之间,使用用4字节模板了:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx。将0x20C30写成21位二进制数字(不足21位就在前面补0):0 0010 0000 1100 0011 0000,用这个比特流依次代替模板中的x,得到:11110000 10100000 10110000 10110000,即F0 A0 B0 B0。
二、MySQL字符集设置
1、系统变量:
–character_set_server:默认的内部操作字符集
–character_set_client:客户端来源数据使用的字符集
–character_set_connection:连接层字符集
–character_set_results:查询结果字符集
–character_set_database:当前选中数据库的默认字符集
–character_set_system:系统元数据(字段名等)字符集
–还有以collation_开头的同上面对应的变量,用来描述字符序。
2、MySQL的字符集支持(Character Set Support)有两个方面:1.字符集(Character set)和排序方式(Collation)。
对于字符集的支持细化到四个层次:
服务器(server),数据库(database),数据表(table)和连接(connection)。
MySQL对于字符集的指定可以细化到一个数据库,一张表,一列,应该用什么字符集。
但是,传统的程序在创建数据库和数据表时并没有使用那么复杂的配置,它们用的是默认的配置,那么,默认的配置从何而来呢?
(1)编译MySQL 时,指定了一个默认的字符集,这个字符集是 latin1;
(2)安装MySQL 时,可以在配置文件 (my.cnf) 中指定一个默认的的字符集,如果没指定,这个值继承自编译时指定的;
(3)启动mysqld 时,可以在命令行参数中指定一个默认的的字符集,如果没指定,这个值继承自配置文件中的配置,此时character_set_server被设定为这个默认的字符集;
(4)当创建一个新的数据库时,除非明确指定,这个数据库的字符集被缺省设定为character_set_server;
(5)当选定了一个数据库时,character_set_database被设定为这个数据库默认的字符集;
(6)在这个数据库里创建一张表时,表默认的字符集被设定为character_set_database,也就是这个数据库默认的字符集;
(7)当在表内设置一栏时,除非明确指定,否则此栏缺省的字符集就是表默认的字符集;
简单的总结一下,如果什么地方都不修改,那么所有的数据库的所有表的所有栏位的都用 latin1 存储,不过我们如果安装 MySQL,一般都会选择多语言支持,也就是说,安装程序会自动在配置文件中把default_character_set设置为 UTF-8,这保证了缺省情况下,所有的数据库的所有表的所有栏位的都用 UTF-8 存储。
2.查看默认字符集(默认情况下,mysql的字符集是latin1(ISO_8859_1)通常,查看系统的字符集和排序方式的设定可以通过下面的两条命令:
mysql> SHOW VARIABLES LIKE 'character%';+--------------------------+---------------------------------+| Variable_name | Value |+--------------------------+---------------------------------+| character_set_client | latin1 || character_set_connection | latin1 || character_set_database | latin1 || character_set_filesystem | binary || character_set_results | latin1 || character_set_server | latin1 || character_set_system | utf8 || character_sets_dir | D:"mysql-5.0.37"share"charsets" |+--------------------------+---------------------------------+mysql> SHOW VARIABLES LIKE 'collation_%';+----------------------+-----------------+| Variable_name | Value |+----------------------+-----------------+| collation_connection | utf8_general_ci || collation_database | utf8_general_ci || collation_server | utf8_general_ci |+----------------------+-----------------+
从上例中我们可以看出字符集utf8,其中默认的排序方式为utf8_general_ci。排序方式的命名规则为:字符集名字_语言_后缀,其中各个典型后缀的含义如下:1)_ci:不区分大小写的排序方式2)_cs:区分大小写的排序方式3)_bin:二进制排序方式,大小比较将根据字符编码,不涉及人类语言,因此_bin的排序方式不包含人类语言
3、MySQL中的字符集转换过程
(1). MySQL Server收到请求时将请求数据从character_set_client转换为character_set_connection;
(2).进行内部操作前将请求数据从character_set_connection转换为内部操作字符集,其确定方法如下:
使用每个数据字段的CHARACTER SET设定值;
若上述值不存在,则使用对应数据表的DEFAULT CHARACTERSET设定值(MySQL扩展,非SQL标准);
若上述值不存在,则使用对应数据库的DEFAULT CHARACTERSET设定值;
若上述值不存在,则使用character_set_server设定值。
(3).将操作结果从内部操作字符集转换为character_set_results。

4、常见问题解析
向默认字符集为utf8的数据表插入utf8编码的数据前没有设置连接字符集,查询时设置连接字符集为utf8
–插入时根据MySQL服务器的默认设置,character_set_client、character_set_connection和character_set_results均为latin1;
–插入操作的数据将经过latin1=>latin1=>utf8的字符集转换过程,这一过程中每个插入的汉字都会从原始的3个字节变成6个字节保存;
–查询时的结果将经过utf8=>utf8的字符集转换过程,将保存的6个字节原封不动返回,产生乱码……
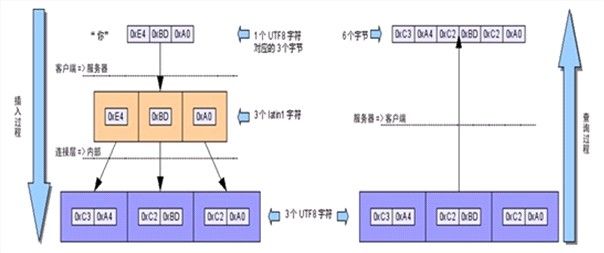
向默认字符集为latin1的数据表插入utf8编码的数据前设置了连接字符集为utf8
–插入时根据连接字符集设置,character_set_client、character_set_connection和character_set_results均为utf8;
–插入数据将经过utf8=>utf8=>latin1的字符集转换,若原始数据中含有\u0000~\u00ff范围以外的Unicode字 符,会因为无法在latin1字符集中表示而被转换为“?”(0×3F)符号,以后查询时不管连接字符集设置如何都无法恢复其内容了。

5、检测字符集问题的一些手段
SHOW CHARACTER SET;
SHOW COLLATION;
SHOW VARIABLES LIKE ‘character%’;
SHOW VARIABLES LIKE ‘collation%’;
SQL函数HEX、LENGTH、CHAR_LENGTH
SQL函数CHARSET、COLLATION
6、使用MySQL字符集时的建议
建立数据库/表和进行数据库操作时尽量显式指出使用的字符集,而不是依赖于MySQL的默认设置,否则MySQL升级时可能带来很大困扰;
数据库和连接字符集都使用latin1时虽然大部分情况下都可以解决乱码问题,但缺点是无法以字符为单位来进行SQL操作,一般情况下将数据库和连接字符集都置为utf8是较好的选择;
使用mysql C API时,初始化数据库句柄后马上用mysql_options设定MYSQL_SET_CHARSET_NAME属性为utf8,这样就不用显式地用 SET NAMES语句指定连接字符集,且用mysql_ping重连断开的长连接时也会把连接字符集重置为utf8;
对于mysql PHP API,一般页面级的PHP程序总运行时间较短,在连接到数据库以后显式用SET NAMES语句设置一次连接字符集即可;但当使用长连接时,请注意保持连接通畅并在断开重连后用SET NAMES语句显式重置连接字符集。
7、其他注意事项
my.cnf中的default_character_set设置只影响mysql命令连接服务器时的连接字符集,不会对使用libmysqlclient库的应用程序产生任何作用!
对字段进行的SQL函数操作通常都是以内部操作字符集进行的,不受连接字符集设置的影响。
SQL语句中的裸字符串会受到连接字符集或introducer设置的影响,对于比较之类的操作可能产生完全不同的结果,需要小心!
三、修改mysql默认字符集
下面介绍下几个MYSQL命令:
1.show character set;或show char set;
查看数据库支持的所有字符集
2.status;或\s;
查看当前状态 里面包括当然的字符集设置
3.show variables like 'char%';
查看系统字符集设置,包括所有的字符集设置
4.show table status from sqlstudy like '%countries%';
查看sqlstudy数据库中表的字符集设置
5.show full columns from countries;
查看表列的字符集设置,关键是在同一个表中,每列可以设置成不同的字符集
知道怎么查看字符集了,下面我来说下如何设置这些字符集(当然全是我这几天从网上整理的,呵呵)
1.修改服务器级
a. 临时更改:
mysql>SET GLOBAL character_set_server=utf8;
b. 永久更改:
修改my.cnf文件
[mysqld]
default-character-set=utf8
2.修改数据库级
a. 临时更改:
mysql>SET GLOBAL character_set_database=utf8;
b. 永久更改:
改了服务器级就可以了
3.修改表级
mysql>ALTER TABLE table_name DEFAULT CHARSET utf8;
更改了后永久生效
4.修改列级
修改示例:
mysql>alter
table `products` change `products_model` `products_model` varchar( 20 )
character set utf8 collate utf8_general_ci null default null;
更改了后永久生效
5.更改连接字符集
a. 临时更改:
mysql> set names utf8;
b. 永久更改:
修改my.cnf文件
在[client]中增加:
default-character-set=utf8
执行SQL语句时信息的路径是这样的
信息输入路径:client→connection→server;
信息输出路径:server→connection→results.
四、mysql字符集转换实例:
以原来的字符集为latin1为例,升级成为utf8的字符集。原来的表: databasename (default charset=latin1),新表:new_databasename(default charset=utf8)。
mysql> show create database databasename;
+--------------+-------------------------------------------------------------------------+
| Database | Create Database |
+--------------+-------------------------------------------------------------------------+
| databasename | CREATE DATABASE `databasename` /*!40100 DEFAULT CHARACTER SET latin1 */ |
+--------------+-------------------------------------------------------------------------+
1 row in set (0.00 sec)
背景:某个系统的mysql数据库dnname采用默认的latin1字符集,系统升级需要将所有数据转换成utf-8格式,目标数据库为newdbname(建库时使用utf8)
方法一:
1、命令行执行:mysqldump --opt -hlocalhost -uroot -p*** --default-character-set=lantin1 dbname > /usr/local/dbname.sql
2、将 dbname.sql文件中的create table语句的CHARSET=latin1改为CHARSET=utf8
3、在dbname.sql文件中的insert语句之前加一条'set names utf8;'
4、将dbname.sql转码为utf-8格式,建议使用UltraEditor,可以直接使用该编辑器的'转换->ASCII到UTF-8(Unicode编辑)',或者将文件另存为UTF-8(无BOM)格式
5、创建新数据库
CREATE DATABASE new_dbname CHARACTER SET utf8 COLLATE utf8_general_ci;
6、命令行执行:mysql -hlocalhost -uroot -p*** --default-character-set=utf8 new_dbname < /usr/local/dbname.sql
总结:这种方法有个致命之处就是当数据中有大量中文字符和其他特殊符号字符时,很有可能导致在[步骤五]时报错导致无法正常导入数据,如果数据库比较大可以分别对每张表执行上述步骤
方法二(推荐大家使用):
为了解决第一种方法中总结时说到的问题,在网上苦苦查找了一天资料才东拼西凑的搞出一个比较稳妥的解决方法
1、将待导出的数据表的表结构导出(可以用Phpmyadmin、mysqldump等,很简单就不说了),然后将导出的create table语句的CHARSET=latin1改为CHARSET=utf8,在目标库newdbname中执行该create table语句把表结构建好,接下来开始导出-导入数据
2、命令行:进入mysql命令行下,mysql -hlocalhost -uroot -p*** dbname
3、执行SQL select * from tbname into outfile '/usr/local/tbname.sql';
4、将tbname.sql转码为utf-8格式,建议使用UltraEditor,可以直接使用该编辑器的'转换->ASCII到UTF-8(Unicode编辑)',或者将文件另存为UTF-8(无BOM)格式
5、在mysql命令行下执行语句 set character_set_database=utf8; 注:设置mysql的环境变量,这样mysql在下一步读取sql文件时将以utf8的形式去解释该文件内容
6、在mysql命令行下执行语句 load data infile 'tbname.sql' into table newdbname.tbname;
注意:千万不要忘了第四步
采用第二种方法,所有数据均正常导入,且格式转换成功没有乱码,要注意最好是源字符的超级,或者确定比源字符集的字库更大。