时空行人重识别 Spatial-Temporal Person Re-identification
时空行人重识别
Spatial-Temporal Person Re-identification
GuangcongWang1,JianhuangLai1;2;3,PeigenHuang1,XiaohuaXie1;2;3
中山大学数据与计算机科学学院,中国广东省信息安全技术重点实验室
教育部机器智能与高级计算重点实验室
摘 要:目前大多数行人重识别方法忽略了时空约束。对于给定的查询图像,传统的方法计算查询图像与所有数据库图像之间的特征距离,并返回相似度排序表。当图库数据库在实际中非常大时,由于不同相机视图之间的外观模糊,这些方法无法获得良好的性能。本文提出了一种同时挖掘视觉语义信息和时空信息的双流时空行人重识别框架。为此,提出了一种基于逻辑平滑的联合相似度度量方法,将两类异构信息集成到一个统一的框架中。为了近似得出一个复杂的时空概率分布,我们提出了一种快速直方图Histogram-Parzen(HP)方法。在时空约束下,时空行人重识别模型消除了大量不相关的图像,从而缩小了库的范围。在没有任何附加条件的情况下,我们的时空行人重识别方法在Market-1501数据集上实现了98.1%的rank-1准确度,在DukeMTMC-行人重识别数据集上达到了94.4%,比基线91.2%和83.8%有所提高,大大超过了之前所有最先进的方法。代码可在https://github.com/Wanggcong/Spatial-Temporal-Re-identification获得。
关键词:行人重识别 双流时空行人重识别框架 时空约束
介 绍
行人重识别的目标是在给定查询图像的非重叠相机视图中重新定位行人图像。最近,最先进的行人重识别方法(Wang et al. 2016;Zhong et al. 2017a; Bai, Bai, and Tian 2017; Tang et al.2017; Zhuo et al. 2018; Lin et al. 2017a)通过使用深度学习进行特征表示,准确率获得了显著的提高(例如,在Market-1501数据集上,rank-1准确度达到80-90%)。然而,这些方法还远远不能应用于可能包含大量图像的真实场景中。由于外观模糊,仅使用一般的视觉特征很难进一步提高性能。例如,不同的人可能有相似的外观、光照条件或者身体的姿势。如何利用额外的信息来绕过这个瓶颈,是行人重识别社区的一个热门话题。

图1:传统的行人重识别与我们的时空行人重识别(a)常规行人重识别检索结果。没有时空信息的帮助,传统的行人重识别很难处理外观模糊的行人(红色框表示错误的结果)。(b)我们时空行人重识别的检索结果。
利用时空信息,时空行人重识别可以剔除不相关的图像。此外,时空行人重识别的时空信息(相机ID和时间戳)在视频监控中广泛存在,无需人工标注即可轻松采集(彩色效果最佳) 。
最近的研究试图利用人的结构信息来提高行人重识别方法的性能。他们认为,人的结构信息,如身体部位、身体姿势、人的属性和背景上下文信息,可以帮助行人重识别方法捕捉有辨别能力的局部视觉特征。例如,part-based methods (Liet al. 2017; Zhao et al. 2017b)假设一个人的形象从上到下由头部、上半身、下半身和脚组成。考虑到人的结构信息,可以共同学习人的全局全身特征和局部身体部位特征。Pose-based methods (Su et al. 2017; Zhao et al. 2017a)的目的是通过利用关键点注释对姿态进行定位和对齐,提取位置不变的特征。其他方法利用挖掘属性、语义分割或背景上下文线索(Kalayeh et al. 2018; Song et al.2018)来进行行人重识别。然而,这些模型对于行人重识别解决外观模糊问题的效果有限.
不同于使用人的结构信息,各种各样的方法也试图利用时空信息。最直接的方法是利用视频中的时空信息。Image-to-videoarXiv:1812.03282v1 [cs.CV] 8 Dec 2018and video-based person ReID methods (Wang, Lai, and Xie2017; Li et al. 2018)的目标是学习空间和时间不变的视觉特征。然而,这些方法仍然关注视觉特征表示,而不是跨不同相机的时空约束。例如,一个在t时刻被Camera 1捕获的人,不应该被距离Camera 1较远的Camera 2在t+∆t处捕获(∆t为一个很小的值)。这种时空约束消除了图像数据集中大量不相关的目标图像,从而显著缓解了外观模糊问题。为了区分基于视频的方法的时空概念,我们将其称为时空人行人重识别 (st-ReID),如图1所示。
时空行人重识别曾在distributed camera network topology inference (Huang et al.2016; Cho et al. 2017) 和跨摄像机多目标跟踪中被研究过。然而,这些方法要么对模型简化做出了一些强有力的假设,要么没有关注如何建立一个有效的视觉相似性和时空分布的联合度量。从形式上看,时空行人重识别从训练集{(x_iv,x_iS,x_i^t,y_i)}学习映射f: X→Y,其中x_iv、x_iS、x_i^t和y_i分别表示一个视觉特征向量、一个相机ID(空间信息)、一个时间戳和一个人的ID。时空行人重识别有三个性质:1)时空行人重识别的额外信息(i.e., x_iS,x_it)广泛存在于视频监控中,无需人工标注即可轻松采集(见图1); 2)利用廉价的时空信息,可以显著提高行人重识别的性能(在Market-1501和DukeMTMC-reID数据集中的准确率分别提高6.9%和10.6%); 3) 时空行人重识别可以被认为类似于更困难的跨摄像机多目标跟踪,它会漏掉很多帧之间的帧。时空行人重识别在传统的行人重识别和跨摄像机多目标跟踪之间架起了桥梁。

图2:(a)DukeMTMC-reID的摄像机拓扑结构 (b)时空分布,i.e,相对于时间间隔的正图像对的频率(具有相同身份的图像对表示正图像对)(彩色效果最佳)
对行人重识别的时空模式进行建模有三个关键的挑战。首先,要估计行人重识别的时空模式是极其困难的,它遵循一个复杂的分布。以DukeMTMC-reID数据集为例(图2(a)),相机1和相机6之间存在多条路径,因此相机1到相机6的时空分布中存在多个峰值(图2 (b))。其次,虽然我们可以找到一个很好的公式来描述复杂的时空分布基于有限数据集,但因为行人具有不确定的步行轨迹和速度,所以它仍然是不可靠的。也就是说,一个人可以随时随地出现。第三,由于时空分布不可靠,且具有可靠的视觉相似性和不可靠的时空分布,因此很难建立可靠的联合度量,并且很难为这两种度量分配合适的权重因子。
针对这些难以解决的问题,提出了一种新的基于逻辑平滑的联合相似度度量方法,将视觉特征相似度和时空模式融合到一个统一的度量函数中。特别地,我们首先训练了一个基于PCB模型的深度卷积神经网络用于视觉特征表示(Sun et al. 2017b)。然后介绍了一种Histogram-Parzen方法(HP)来描述每一对相机的正片对相对于时差的概率。为了避免丢失低概率数据集图像,我们提出使用逻辑平滑(LS)来减弱行人重识别的行走轨迹和速度不确定对问题解决的影响。
总体而言,本文的主要贡献有三点:
第一,我们提出了一个新的双流时空行人重识别框架,该框架同时考虑了视觉语义信息和时空信息。时空行人重识别模型利用无需人工标注即可轻松采集的廉价时空信息,消除了大量不相关的图像,从而缓解了行人重识别的外貌模糊问题。
第二,我们提出了一种与Logistic平滑(LS)相结合的相似性度量方法,将两类异构信息集成到一个统一的框架中。此外,我们提出了一种Histogram-Parzen (HP)方法来近似模拟时空概率分布。
第三,在没有任何附加条件的情况下,我们的时空行人重识别方法在Market-1501和DukeMTMC-ReID数据集上分别实现了98.1%和94.4%的rank-1准确度,较基线91.2%和83.8%有了较大的提高,大大超过了之前所有最先进的方法。
相 关 工 作
最近的行人重识别方法集中在视觉特征表示的深度学习。基本上,这些深度模型要么试图设计有效的卷积神经网络,要么采用不同类型的损失函数,如classification loss (Zheng et al. 2016; Feng, Lai, and Xie2018; Liang et al. 2018), verification loss (Li et al. 2014;Chen, Guo, and Lai 2015), and triplet loss (Ding et al. 2015;Wang, Lai, and Xie 2017; Hermans, Beyer, and Leibe 2017;Wang et al. 2016)。由于CNN表现能力的卓越,最先进的方法取得了良好的性能,例如,。然而,这些方法很难解决外观模糊问题。
为了实现这一目标,许多研究试图利用人的结构信息(Li et al. 2017; Zhao et al.2017b; Su et al. 2017; Zhao et al. 2017a; Kalayeh et al. 2018;Song et al. 2018)。例如,a multi-scale context-aware network (Li et al. 2017)被用来学习整个身体和身体部分,以捕获本地上下文信息。A pose-driven deep convolutional model (Suet al. 2017),从全局图像和不同局部区域学习鲁棒特征表示,缓解姿态变化产生的影响。A human parsing method (Song et al. 2018),利用像素级精度提高行人重识别的性能。
另一组研究人员没有使用人的结构信息,而是关注时空信息。根据注释的不同,时空方法可分为两大类。在第一个子组中,时空信息隐藏在视频中,如image-to-video (Wang,Lai, and Xie 2017) 和video-based person ReID (Li et al. 2018; Zheng et al. 2016).
例如,Wang et al. (Wang, Lai, and Xie 2017)提出了一个点对集的网络,用于图像到视频的行人重识别。Li等(Li et al. 2018)引入时空注意模型,为基于视频的行人重识别发现了一组不同的独特身体部位。在第二个子组中,明确使用时空信息作为约束,剔除不相关的数据集图像(Cho et al. 2017;Huang et al. 2016; Lv et al. 2018)。例如,camera network topology inference methods (Cho et al. 2017;Lv et al. 2018)的目标是以在线或无监督学习的方式交替进行行人重识别和摄像头网络拓扑推断。给定一个时间戳为t的人的图像,他们假设这个人应该出现在(t-∆t,t+∆t)。与这些方法不同的是,我们的时空行人重识别方法寻求一种有效的联合度量方法,将时空信息自然地集成到监督行人重识别的视觉特征表示中。此外,引入了基于摄像机网络的行人重识别 (CNPR) (Huang et al. 2016)来考虑视觉特征表示和时空约束。然而,CNPR模型做出了一个强有力的假设:摄像机之间转换的时间差遵循一个包含峰值的Weibull分布,因此在复杂的场景中是不可用的,例如DukeMTMC-reID。此外,CNPR不能解决行走轨迹和速度不确定的问题。与CNPR模型不同,本文提出了概率密度函数近似的Histogram-Parzen window方法,并引入了一种逻辑平滑方法来解决不确定性问题。
建议方法
时空行人重识别的目标是在一个统一的框架中利用视觉特征相似性和时空约束。为此,我们提出了一个由三个子模块组成的两流体系结构,即视觉特征流、时空流和联合度量子模块。图3显示了时空行人重识别的两流体系结构。
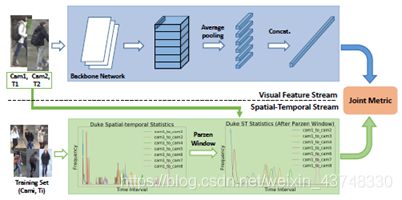
图3:提议的两流架构。它由三个子模块组成,即视觉特征流、时空流和联合度量子模块。(彩色效果最佳)
视觉特征流
视觉特征表示方法在很多相关的文章中都得到了研究。在本文中我们不关注如何提取一个有区别的、鲁棒的特征表示。因此,我们使用了一个清晰的基于部件的Part-based Convolutional Baseline (PCB) (Sun et al. 2017b)作为视觉特征流,而没有考虑细化的部件池。该流包含一个ResNet骨干网络、一个基于条带的平均池化层、6个1×1内核大小的卷积层、6个全连接层和6个分类器(交叉熵损失)。
在训练阶段,每个分类器用于预测给定图像的类(人的身份)。通过部件级特征表示学习方案,PCB可以学习局部判别特征,从而达到具有竞争力的精度。在测试阶段,六个基于条带的特性被连接到一个列向量中,用于可视化特性表示。在图3中,我们只显示了可视化特性流的测试阶段。
给定两幅图像I_i和I_j(I_i和I_i表示数据集中的图像索引),利用PCB模型提取视觉特征,得到分别表示x_i和x_j的两个特征向量。我们根据余弦距离计算相似度评分
s(x_i,x_j )=(x_i⋅x_j)/‖x_i ‖‖x_j ‖ (1)
时空流
时空流是为了捕获时空互补信息,辅助视觉特征流。我们没有使用遵循强假设的封闭形式概率分布函数(Huang et al. 2016),而是使用非参数估计方法估计时空分布,即Parzen Window。然而,由于有太多的时空数据点,直接估计PDF要花费很多时间。
为了解决计算量大的问题,我们提出了一种Histogram-Parzen方法。也就是说,我们首先估计时空直方图,然后使用Parzen Window方法对其进行平滑。设(ID_i,c_i,t_i)和(ID_j,c_j,t_j) (t_i
其中k表示直方图的第k个bin,即时间间隔t_j-t_i∈((k-1)∆t,k∆t).n_(c_i c_j)^k表示从c_i到c_j时间差位于第k个bin的人员图像对的数量。y=1表示I_i和I_j (即ID_i=ID_j)共享相同的人物标识,而y=0表示不同的人物标识(即ID_i≠ID_j)。
使用Parzen Window方法,我们借助平滑直方图
p(y=1│k,c_i,c_j )=1/Z ∑_l▒p ̂ (y=1│l,c_i,c_j )K(l-k) (3)
其中K(.)是核,Z=∑_k▒〖p(y=1│k,c_i,c_j ) 〗是一个归一化因子。在这项工作中,我们使用高斯函数做核K,即
K(x)=1/(√2π σ) e((-x2)/(2σ^2 )) (4)
联合度量
在得到两种异构模式后,直观地假设视觉相似性概率与时空概率无关。联合概率可以简单地表示为
p(y=1│x_i,x_j,k,c_i,c_j )=s(x_i,x_j)p(y=1|k,c_i,c_j) (5)
然而,Eqn.5忽略了两点。首先,直接使用相似度评分作为视觉相似度概率是不合理的,即p(y=1│x_i,x_j )≠s(x_i,x_j)其次,时空概率p(y=1│k,c_i,c_j )是不可靠的,无法控制,因为人的行走轨迹和速度是不确定的,即一个人可以随时随地出现。直接使用p(y=1│k,c_i,c_j )作为时空概率函数,在保持相同精度的前提下,召回率较低。例如,给定一个查询图像,一个图像的相似度为0.9,时空概率为0.01,而另一个图像的相似度为0.3,0.1。Eqn. 5趋向于返回第二个图像。时空概率较低的可能被认为是不相关的图像。然而,这在现实场景中是不切实际的,尤其是视频监控系统。例如,当检索小偷的图像时,他可能不会被检索到,因为他可能比普通人走得快,并且具有较低的时空概率。那么,我们可以将相似性得分转换为视觉相似性概率,还是构建一个鲁棒的时空概率呢?我们的观察是双重的:
Observation 1:拉普拉斯平滑。拉普拉斯平滑是一种广泛应用于朴素贝叶斯估计先验概率的方法
p_λ (Y=d_k )=(m_k+λ)/(M+Dλ) (6)
其中d_k表示第k类标签,m_k表示第k类的个数,M是例子的总数,D是类别总数,λ是平滑参数。作为一种特殊情况,类别的数量D为2且λ=1,我们得到
p_λ (Y=d_k )=(m_k+1)/(M+2) (7)
我们可以看到拉普拉斯平滑被用来调整罕见(但并非不可能)事件的概率,因此这些概率不完全为零,并且避免了零频率问题。作为一种收缩估计量,其平滑结果介于经验估计m_k/M和均匀概率1/2之间。
Observation 2:Logistic函数。logistic模型在二分类问题中得到了广泛的应用。特别地,它被定义为
f(x;λ,γ)=1/(1+λe^(-γx) ) (8)
常系数λ和γ, λ是一个平滑因子, γ是萎缩的因素。
Observation 1给出了平滑算子的基本思想,以减轻不可靠的概率估计。Observation 2表明,logistic函数可用于二元分类问题。在此基础上,我们提出了一种逻辑平滑方法,在给定一定信息的情况下,既可以调整罕见事件的概率,又可以计算属于同一ID的两幅图像的概率。我们修改了Eqn.(5):
p_joint=f(s;λ_0,γ_0 )f(p_st;λ_1,γ_1 ) (9)
为了表示简单,我们使用p_joint,s和p_st分别来表示p(y=1│x_i,x_j,k,c_i,c_j ),s(x_i,x_j)和p(y=1│k,c_i,c_j )。根据Eqn.(1)和(3)我们可以看到,s∈(-1,1)被逻辑函数收缩了,就像拉普拉斯平滑一样,但没有收缩那么多。不同的是,p∈(0,1)被截短,并且大部分被提升。甚至时空概率也趋近于零,即f(p_st;λ_1,γ_1 )≥f(0)=1/(1+λ_1 )。使用逻辑平滑,Eqn.(9)对罕见的时间非常稳定。这是合理的,因为如上所述时空概率是不可靠的,而视觉相似性是相对可靠的。此外,利用logistic函数将相似度得分(时空概率)转化为二元分类概率(正对或负对)是直观且不言自明的,如Observation 2所示。
实现细节
对于视觉特征流,我们按照PCB方法(Sun et al. 2017b)设置超参数,没有考虑细化池方案。对训练图像进行水平翻转和归一化增强,调整为384×192。我们使用的SGD的小批量大小为32。我们训练了60个时代的视觉特征流。学习速率由0.1开始,经过40个世代后衰减为0.01。骨干模型在ImageNet上进行预训练,所有预训练层的学习率均设置为基础学习率的0.1×。对于时空流,我们将时间间隔∆t设为100帧。我们设置了高斯核参数σ- 50和使用西格玛规则进一步减少计算。至于联合度规,我们将λ_0,λ_1,γ_0与γ_1分别设置为1,2,5,5。
实验
在本节中,我们将在两个大型行人重识别基准数据集上(Market-1501和DukeMTMC-reID)评估时空行人重识别方法,并说明时空行人重识别模型与其他先进方法相比的优越性。然后我们提出消融研究,以揭示我们的方法的每个主要成分/因素的好处。
数据集。Market-1501数据集是在清华大学的一个超市前收集的。共使用6台摄像机,包括5台高分辨率摄像机和1台低分辨率摄像机。不同相机之间存在重叠现象。总的来说,这个数据集包含32,668个带注释的边界框,包含1,501个身份。其中,751个身份的12936幅图像用于培训,750个身份的19732幅图像加上干扰物用于测试。
Methods R-1 R-5 R-10 mAP
BoW+kissme 44.4 63.9 72.2 20.8
KLFDA 46.5 71.1 79.9 -
Null Space 55.4 - - 29.9
WARCA 45.2 68.1 76 -
PAN 82.8 - - 63.4
SVDNet 82.3 92.3 95.2 62.1
HA-CNN 91.2 - - 75.7
SSDAL 39.4 - - 19.6
APR 84.3 93.2 95.2 64.7
Human Parsing 93.9 98.8 99.5 -
Mask-guided 83.79 - - 74.3
Background 81.2 94.6 97 -
PDC 84.1 92.7 94.9 63.4
PSE+ECN 90.3 - - 84
MultiScale 88.9 - - 73.1
Spindle Net 76.9 91.5 94.6 -
Latent Parts 80.3 - - 57.5
Part-Aligned 81 92 94.7 63.4
PCB(*) 91.2 97 98.2 75.8
TFusion-sup 73.1 86.4 90.5 -
st-ReID 97.2 99.3 99.5 86.7
st-ReID+RE 98.1 99.3 99.6 87.6
st-ReID+RE+re-rank 98 98.9 99.1 95.5
表1:所建议的方法在Market-1501上的表现与最先进的方法的比较。比较的方法分为七组。第1组:手工特性方法。第二组:明确基于深度学习的方法。第三组:基于属性的方法。第四组:面罩引导法。第5组:基于部分的方法。第六组:基于位置的方法。第七组:时空方法。表示我们复制的方法。
对于查询,使用了750个身份的3368个手绘边界框。在这个开放的系统中,每个身份的图像最多由6个摄像机捕捉。每个带注释的标识至少出现在两个摄像机中。每个图像包含它的相机id和帧数(时间戳)。
DukeMTMC-reID是DukeMTMC数据集的子集,用于基于图像的重识别。有1404个身份出现在两个以上的摄像机中,408个身份(干扰者ID)只出现在一个摄像机中。其中,选取702个ID作为训练集,其余的702个ID作为测试集。在测试集中,每个相机的每个ID选择一个查询图像,其余的图像放入测试集中。这样,有16522张702个身份的训练图像、2228张其他702个身份的查询图像和17661张图库图像(702 ID + 408 distraction actor ID)。每个图像包含它的相机id和帧数(时间戳)。
评估协议。对于每个查询,算法计算查询图像和所有图像之间的距离,并从小到大返回一个排序表。Top-k精度是通过检查Top-k库图像是否包含查询标识来计算的。对于每个单独的查询标识,由于在ReID中设置了跨视图匹配,因此排除了来自同一摄像机的某个人的库样本
Methods R-1 R-5 R-10 mAP
BoW+kissme 25.1 - - 12.2
LOMO+XQDA 30.8 - - 17
PAN 71.6 - - 51.5
SVDNet 76.7 - - 56.8
HA-CNN 80.5 - - 63.8
APR 70.7 - - 51.9
Human Parsing 84.4 91.9 93.7 71
PSE+ECN 85.2 - - 79.8
MultiScale 79.2 - - 60.6
PCB() 83.8 91.7 94.4 69.4
st-ReID 94 97 97.8 82.8
st-ReID+RE 94.4 97.4 98.2 83.9
st-ReID+RE+re-rank 94.5 96.8 97.1 92.7
表2:所建议的方法在DukeMTMC-reID上的表现与最先进的方法的比较。比较的方法分为七组。第一组:手工特性方法。第二组:明确基于深度学习的方法。第三组:基于属性的方法。第四组:面罩引导法。第5组:基于部分的方法。第六组:基于位置的方法。第七组:时空方法。*表示我们复制的方法。
平均平均精度(mAP)用于评估总体性能。对于每个查询,我们计算精度召回曲线下的面积,即平均精度(AP)。然后所有查询的ap均值,即mAP的计算,考虑了算法的精度和查全率,从而提供了更全面的评价。
与最先进水平的比较
在这一小节中,我们将时空行人重识别方法与现有的许多方法在两个大型的行人重识别基准数据集上进行比较,以显示时空行人重识别方法的优越性。
在Market-1501数据集上的评估。 我们根据现有的20种最先进的方法对所提出的时空行人重识别模型进行了评估。 1) handcrafted feature methods including BoW+kissme (Zheng et al. 2015), KLFDA (Karanam et al. 2016), Null Space (Zhang, Xiang, and Gong 2016) and WARCA (Jose and Fleuret 2016); 2) clear deep learning based methods including PAN (Zheng, Zheng, and Yang 2016), SVDNet (Sun et al. 2017a), and HA-CNN; 3) attribute-based methods including SSDAL (Su et al. 2016) and APR (Lin et al. 2017b); 4) mask-guided methods including Human Parsing (Kalayeh et al. 2018), Mask-guided (Song et al. 2018), and Background (Tian et al. 2018); 5) part-based methods including TFusion-sup (Lv et al. 2018)。
其中,基于属性的方法使用person属性注释,掩码引导方法使用person mask或人体解析注释,基于部件的方法使用person body assumption或body part检测器,基于位置的方法使用keypoint注释。与手工的特征方法和基于深度学习的清晰方法相比,这些方法获得了较好的性能,但是它们需要昂贵的注释,并且非常耗时,例如像素级的人工解析注释、18个关键点和身体部分注释。
我们的时空行人重识别方法使用廉价的时空信息(即相机ID与时间戳)并达到了97.2%的rank-1精度和87.6%的mAP精度,远远超过了所有现有的最先进的方法。通过random erase (RE) (Zhong et al. 2017c),我们的时空行人重识别实现了98.1%的rank-1精度和87.6%的mAP精度。 通过re-ranking scheme (Zhong et al. 2017b),我们的时空行人重识别得到了95.5%的mAP精度。TFusion-sup也使用时空约束,但是它有一个强有力的假设,当给定一个时间戳为t的查询图像时,一个图像中的人物总是出现在(t -∆t, t+∆t)中。这种方法在复杂的场景中可能并不有效,尤其是在DukeMTMC-reID数据集中。此外,TFusion-sup通过在学习视觉特征表示和估计时空模式之间交替迭代,为行人重识别实现跨数据集的无监督学习。因此,TFusion-sup实际上并没有研究如何估计时空概率分布,以及如何建模视觉相似性与时空概率分布的联合概率。
在DukeMTMC-reID数据集上的评估。DukeMTMC-reID是一个新的数据集,它是目前为止最具挑战性的行人重识别数据集之一。我们将时空行人重识别方法与DukeMTMC-reID数据集中的十种最先进的方法进行了比较。除LOMO+XQDA (Liao et al. 2015)外,所有的竞争方法都在Market-1501数据集上进行了评估。如表2所示,令人鼓舞的是看到我们的方法(没有任何评估方案)以很大的优势显著优于竞争方法,例如,通过改进先进的方法,rank-1精度从85.2%增加到94.0%,mAP从79.8%降至82.8%,PSE + ECN(评估方案)。通过随机擦除(RE),我们的时空行人重识别实现了94.4%的rank-1精度和83.9%的mAP精度。通过重新排序,我们的时空行人重识别得到了92.7%的mAP精度。
评价。在没有附加条件的情况下,我们的时空行人重识别模型比之前所有最先进的行人重识别方法都要好,例如,在Market-1501和DukeMTMC-reID数据集上的rank-1精度分别为98.1%和94.4%。虽然超出了这项工作的范围,但是我们期望许多这样的技术(例如改进池)能够适用于我们的技术。
消融研究和模型分析
为了对我们的方法的性能提供更多的见解,我们对最具挑战性的DukeMTMC-reID数据集进行了许多消融研究,分离了每个关键组件—视觉特征表示流、时空概率估计流和联合子模块。

图4:我们方法的有效性
视觉特征流的效果。为了显示视觉特征流(VIS流)的优点,我们通过分离该子模块进行消融研究。为了实现这一点,我们删除了视觉特征流,只使用时空流。从图4 (a)可以看出,去除VIS流后,rank-1的准确率下降了5.5%(从94.0%下降到88.5%)。在本实验中,我们证实了VIS流在时空行人重识别中起着关键作用。
时空流的影响。为了显示时空流(ST流)的好处,我们删除了这个子模块,看看时空流如何在时空行人重识别中产生影响。在这种情况下,时空行人重识别模型被降级为PCB模型。由图4 (a)可以看出,在没有时空概率估计流的情况下,rank-1的准确率下降了10.2%(从94.0%下降到83.8%)。
联合度量的有效性。为了证明联合度量的有效性,我们使用Eqn. 5设置了基线。在基线中,VIS流和ST流都是标准化的。为了公平的比较,我们使用相同的VIS和ST流。如图4 (b)所示,我们的联合度量方法将性能从86.9%提高到了94.0%。与VIS流(PCB模型)相比,由于融合了时空信息,基线也得到了3.1%的改善。
参数的影响。研究时空行人重识别中两个重要参数的影响。平滑因子λ和收缩因子γ,我们进行两个灵敏度分析实验。如图4所示©和(d),当λ在0.4∼2.8或γ在1∼7的范围时,我们的模型几乎保持了最好的性能。
Methods R-1 R-5 R-10 mAP
ResNet50 baseline 76.9 87.8 91 58.7
ResNet50+ST 87.7 94.1 95.8 72.2
DenseNet121 baseline 79.3 89.9 92.6 63.3
DenseNet121+ST 90.8 95.2 96.5 76.9
PCB(*) 83.8 91.7 94.4 69.4
PCB+ST 94 97 97.8 82.8
表3:时空行人重识别在DukeMTMC-reID上的推广
时空行人重识别的泛化。为了证明时空行人重识别的良好泛化,我们进一步使用不同的深度模型分别作为VIS流。深度模型为ResNet-50(交叉熵损失清晰模型)、DenseNet-121(交叉熵损失清晰模型)和PCB。如表3所示,可以看出,当将ST流添加到这些VIS流中并使用我们的联合度量时,我们可以获得超过10%的准确率提升。
结 论
本文提出了一种新的双流时空行人重识别(时空行人重识别)框架,该框架同时挖掘视觉语义相似性和时空信息。在没有任何附加条件的情况下,我们的时空行人重识别方法在Market-1501数据集上的rank-1准确度为98.1%,在DukeMTMC-reID数据集上的rank-1准确度为94.4%,分别比基准的91.2%和83.8%有所提高,大大超过了之前所有最先进的方法。
我们打算把这项工作扩大到两个方向。首先,时空行人重识别在传统的行人重识别和跨摄像机多目标跟踪之间架起了一座桥梁,可以方便地推广到跨摄像机多目标跟踪。其次,我们打算使用端到端训练的方式进一步提高时空行人重识别方法的性能。