【Linux】文件系统及动静态库
目录
一、文件系统
1、基本知识
2、磁盘文件
3、磁盘结构(磁盘与OS的映射关系)
(1)物理结构
(2)磁盘的抽象
(3)、深入理解inode
4、软硬链接
二、动静态库
1、静态库
(1)、静态库的制作
(2)、静态库的使用
2、动态库
(1)、动态库的制作
(2)、动态库的使用
3、使用库的原因
总结
一、文件系统
1、基本知识
前面我们所提及的文件都是被打开的文件,是被加载到内存的文件,当然操作系统中存在大量没有被打开的文件,它们主要储存在磁盘中(磁盘级文件)
我们主要侧重点在于
单个文件:这个文件在哪里?文件有多大?文件的其它属性是什么?
站在系统角度:有多少文件?各自的属性在哪里?如何快速找到?我还可以存储多少文件?如何快速找到指定文件
2、磁盘文件
计算机存储介质主要分为:
掉电易失存储介质和永久性存储介质
内存:掉电易失存储介质
磁盘:永久性存储介质 SSD,U盘,flash卡,光盘,磁带
磁盘作为一个外设且是计算机中唯一一个机械设备,它是十分的慢的,所以OS一定会有一些提速的方式
3、磁盘结构(磁盘与OS的映射关系)
(1)物理结构

磁盘主要是由磁盘盘片,磁头,伺服系统,音圈马达等构成
磁盘是在它的盘面上存储数据-》磁盘是有磁性的(N,S极)正好对应了计算机的二进制
对磁盘进行写入就是改变磁盘上的极性
并且磁盘是由一摞盘面构成,每个盘面都会有磁头
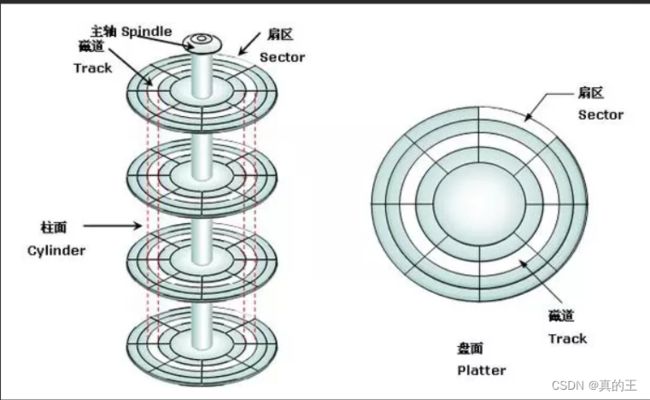
磁盘储存数据的基本单位是512字节
每一个扇区能够存储的数据大小一般都是512字节,通过控制磁盘密度不同使扇区物理大小不同,而存储相同大小的数据
在物理层面上,如何把数据写入到指定的扇区里?
CHS寻址方式:
首先要找到数据在哪个盘面上存储
接下啦寻找在哪个磁道(柱面)上
最后确定在哪个扇区
① CHS寻址模式将硬盘划分为磁头(Heads)、柱面(Cylinder)、扇区(Sector)。
磁头(Heads):每张磁片的正反两面各有一个磁头,一个磁头对应一张磁片的一个面。因此,用第几磁 头就可以表示数据在哪个磁面。
柱面(Cylinder):所有磁片中半径相同的同心磁道构成“柱面",意思是这一系列的磁道垂直叠在一起,就形成一个柱面的形状。简单地理解,柱面数=磁道数。
扇区(Sector):将磁道划分为若干个小的区段,就是扇区。虽然很小,但实际是一个扇子的形状,故称为扇区。每个扇区的容量为512字节。
② 知道了磁头数、柱面数、扇区数,就可以很容易地确定数据保存在硬盘的哪个位置。也很容易确定硬盘的容量,其计算公式是: 硬盘容量=磁头数×柱面数×扇区数×512字节
(2)磁盘的抽象
磁盘是圆形结构-》我们可以将其按照一个剖面展开,抽象出线性结构
将一个大磁盘抽象出一个大数组,然后操作系统对磁盘的管理转变为对数组的管理
将数据存储到磁盘-》将数据存储到数组
找到磁盘特定扇区的位置-》找到数组特定位置
对磁盘的管理-》对该数组的管理
因为磁盘十分的大,我们需要将其划分为一小块,一小块的空间,然后管理——分区
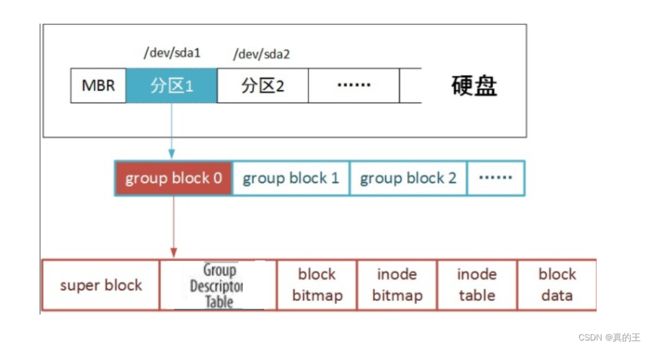
磁盘的基本单位是扇区(512字节),但是操作系统和磁盘进行I/O的基本单位是4kb
为什么操作系统不以512字节为单位呢?
(1)、太小了,有可能需要多次I/O,进而导致效率降低
(2)、如果操作系统使用和磁盘一样的大小,如果磁盘的大小改变,操作系统的源代码也需要进行修改,使用4kb实现了操作系统和硬件的解耦合
Data blocks:多个4kb空间的集合,保存的都是特定的文件内容
inode :inode是一个大小为128字节的空间,保存的是对应文件的属性,包含自己的inode编号
这也就说明Linux下,文件的内容和属性是分开存储的
inode Table:该块组内所有文件的inode空间的集合,需要唯一标识,每一个inode块都需要有一个inode编号,简言之:一般来说一个文件一个inode编号
BlockBitmap:假设有1W+个blocks,就会有1W+个比特位,比特位与特定的blocks是一一对应的,其中比特位为1,代表该blocks被占用,否则表示为可用
inodeBitmap:假设有1W+个inode,就会有1W+个比特位,比特位与特定的indoe是一一对应的,其中比特位为1,代表该inode被占用,否则表示为可用
GDT:快组描述符,这个块组的大小,已经使用多少空间,有多少个inode,已经占用多少了
还剩多少,一共有多少block,还剩多少……
块组分割成为上面的内容,并且写入相关的管理数据-》每一个块组都这么干-》整个分区就被写入了文件系统
一个文件只对应一个inode属性节点-》有唯一的inode编号
一个文件可以有多个block、
inode中存有与该文件映射的block的块号,如果文件特别大,有的block里面就会存储该文件的相关的块号来实现存储大量文件
(3)、深入理解inode
inode编号是当前分区有效
找到文件:inode编号-》分区特定的blockgroups-》inode-》属性-》内容
在Linux中inode属性中没有文件名
一个目录下,可以保存很多文件,但是这些文件名是不允许重复的
目录也是一个文件,也要有inode,也要有data blocks
它的data blocks内部存放的是文件名和对应inode的映射关系,两者都是唯一确定的
创建一个文件,系统做了什么?
先在特定分区,特定块组中遍历inodeBitmap,找到为0的比特位,将其置为1,inode中写入它的属性,建立与data blocks的映射关系,清空特定的data blocks,建立文件名与inode的映射关系,其中文件名从用户中来,inode从系统中来
文件创建失败的原因
inode和data blocks都是固定的,可能inode没有了,data block还存在
inode有,data block没有了
4、软硬链接
我们先创建一个文件
然后与另一个文件建立软链接
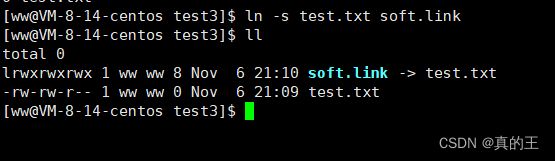
ls -s 文件名 链接文件名
后一个链接前一个
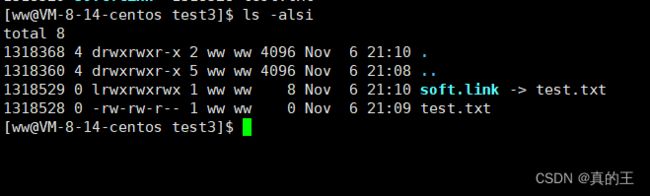
我们再硬链接test.txt
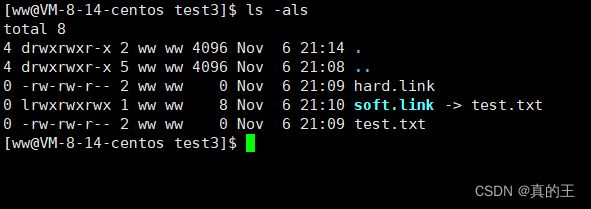
这时我们发现soft.link和test.txt的inode是不同的,证明软链接是有独立inode的
硬链接是没有独立inode的,它的inode与链接文件inode相同
软硬连接本质区别:有无独立inode
软链接有独立inode-》软链接是一个独立的文件
硬链接没有独立inode-》硬链接不是一个独立文件
软连接相当于创建了一个新文件,文件中存储的是指向某个文件的路径
创建硬链接不是创建了一个真正的文件,硬链接用的是其它文件的属性和数据
硬连接的本质是在指定路径下建立了文件名与inode的映射关系
一个inode可以映射多个文件名,删除其中一个文件,相当于去除与inode的映射关系,只有将该文件的全部映射关系去掉,才意味着真正删除该文件
默认创建目录,引用计数(硬链接数)为什么是2?
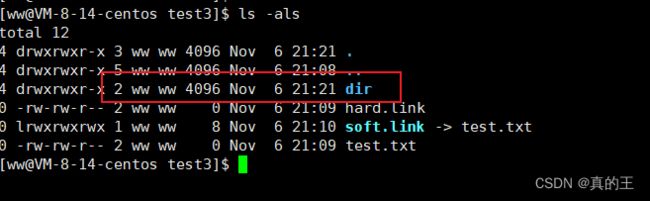
这是因为 自己目录名 与inode建立映射
目录内部还会有 . 记录当前目录
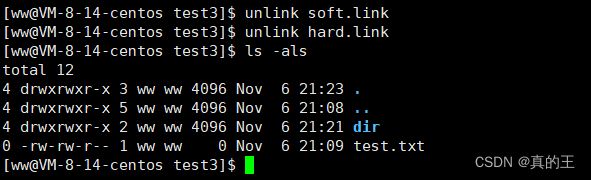
如果我们想要去除链接关系可以使用unlink命令
二、动静态库
对于Linux下静态库后缀.a 动态库.so
库中是没有main函数的
并且需要将.c/.cpp文件编译成.o文件
如果我们只把.h和.o文件给别人,别人是能够直接使用的
同时我们所写的库都是第三方库,写好后直接编译是不能通过的
Linux下头文件gcc的默认搜索路径是:/usr/include
库文件的默认搜索路径是:/lib64 or /usr/lib64
我们将库拷贝到系统的默认路径下,叫做库的安装
所以我们要使用库,无论是静态库还是动态库都需要我们手动指明库的位置,头文件的位置
1、静态库
(1)、静态库的制作
//myprint.h
#include
extern void print();
//myprint.cpp
#include "myprint.h"
void print()
{
std::cout << " Hello World" << std::endl;
}
//mymath.h
#include
extern int GetSum(int left, int right);
//mymath.cpp
#include "mymath.h"
int GetSum(int left, int right)
{
int ans = 0;
for(int i = left; i <= right; i++)
{
ans += i;
}
return ans;
} 按照前面所说我们需要将.c/.cpp编译为.o文件
然后使用ar命令打包
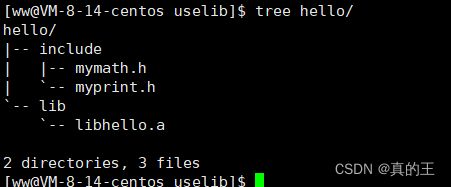
ar -rc libhello.a mymath.o myprint.o![]()
这就形成了静态库,这个过程我们也可以使用makefile来进行简化
//makefile
libhello.a: myprint.o mymath.o
ar -rc libhello.a mymath.o myprint.o
mymath.o: mymath.c
gcc -c mymath.c -o mymath.o -std=c99
myprint.o: myprint.c
gcc -c myprint.c -o myprint.o -std=c99
.PHONY:hello
hello:
mkdir -p hello/include
mkdir -p hello/lib
cp -rf *.a hello/lib
cp -rf *.h hello/include
.PHONY:clean
clean:
rm -rf *.o libhello.a
(2)、静态库的使用
静态库的使用这里只说明不修改系统的方法
gcc -o test.exe main.c -I hello/include -L hello/lib -lhello
-I 代表指明头文件路径
-L代表库所在的路径
-l代表该路径下的具体库的名字
库的真实名字:去掉前缀lib 去掉后缀.a或者.so

2、动态库
动态库的制作和静态库类似,不过是在编译时增加了新的选项
(1)、动态库的制作
同样道理,制作动态库也需要我们将文件编译成为.o不过要加上-fPIC选项
gcc -fPIC -c mymath.c -o mymath.o编译成.o文件之后的操作是打包
gcc -shared myprint.o mymath.o -o liboutput.so同样我们也可以写成makefile
liboutput.so: myprint.o mymath.o
g++ -shared mymath.o myprint.o -o liboutput.so
mymath.o:mymath.cpp
g++ -fPIC -c mymath.cpp -o mymath.o
myprint.o:myprint.cpp
g++ -fPIC -c myprint.cpp -o myprint.o
.PHONY:output
output:
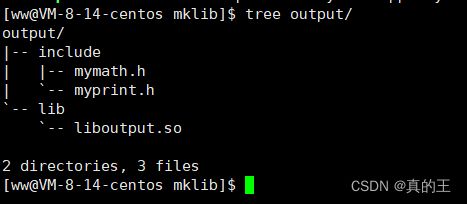
mkdir -p output/include
mkdir -p output/lib
cp *.h output/include
cp *.so output/lib
.PHONY:clean
clean:
rm -rf output *.o *.so

(2)、动态库的使用
a.如果我们只有静态库,没办法,编译器只能针对该库进行静态链接
b.如果动静态库同时存在,默认使用动态库
c.如果动静态库都存在,非要使用静态库 使用-static选项,摒弃默认优先使用动态库的原则,直接使用静态库的方案
当我的程序要使用动态库中的代码时,将动态库加载到内存,并且与页表进行映射,映射动态库代码到共享区
静态库使用绝对地址的方案,必须从全局的角度看待,因为它将库与可执行程序一同加载
动态库是独立的库文件,可以分批加载,随意加载到任意位置,然后与页表进行映射

然后运行

报错,找不到动态库。
可是我们前面已经声明了动态库的位置,这里为什么还是找不到呢?
因为我们声明动态库位置是对编译器的,而编译完成后就与编译器没有任何关系了
所以我们需要对操作系统声明动态库的位置
我们可以建立一个库的软连接文件到/lib64目录中

然后运行

3、使用库的原因
站在使用库的角度,库的存在,可以大大减少我们的开发周期,提高软件的质量
站在写库的角度:1、简单,2、安全
库是编译好的,并不会暴露我的源代码
总结
以上就是今天要讲的内容,本文仅仅是简单介绍了Linux文件系统及动静态库的制作和使用