27.日志技术、XML
目录
一.日志技术
1.1 什么是日志
1.2 目前记录日志的方案
1.3 日志技术的优势
1.4 日志技术体系
1.5 Logback框架
1.5.1 下载地址
1.5.2 模块组成
1.5.3 Logback的使用
二.XML
2.1 XML概述
2.2 XML的特点
2.3 XML文件的使用场景
2.4 XMl文件的创建
2.5 XML的语法规则
2.6 XML的标签(元素)规则
2.7 文档约束
2.8 XML文档约束——DTD
2.9 XML文档约束——schema
三.XML解析技术
3.1 什么是XML解析
3.2 分类
3.3 DOM解析
3.4 DOM4J
3.5 示例代码
四.XML检索技术
4.1 XML检索技术概述
4.2 步骤
4.3 Document中与Xpath相关的API
4.4 Xpath的四大检索方案
4.4.1 绝对路径
4.4.2 相对路径
4.4.3 全文检索
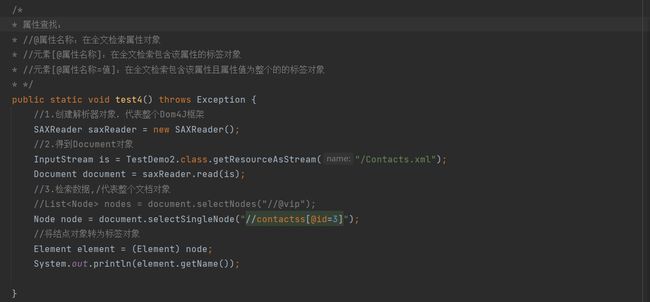
4.4.4 属性查找
一.日志技术
1.1 什么是日志
用来记录程序运行过程中的信息,并可以进行永久存储。好比生活中的日记,记录你的点点滴滴
1.2 目前记录日志的方案

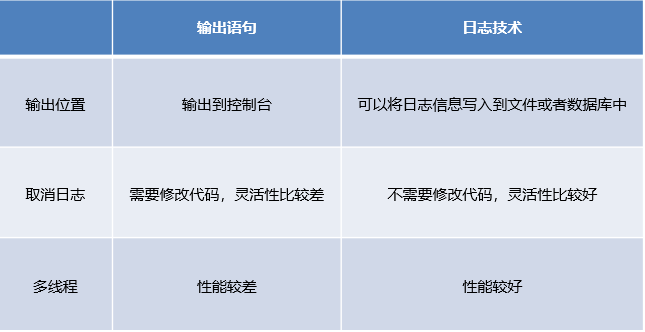
用输出语句记录。
弊端:
信息展示在控制台。
不能方便的记录到其他位置(文件、数据库)
想取消记录的信息需要修改代码才可以完成。
1.3 日志技术的优势
可以将系统执行的信息,方便的记录到指定的位置(控制台、文件、数据库)
可以随时以开关的形式记录日志的记录和取消,无需侵入到源代码中去修改。
1.4 日志技术体系
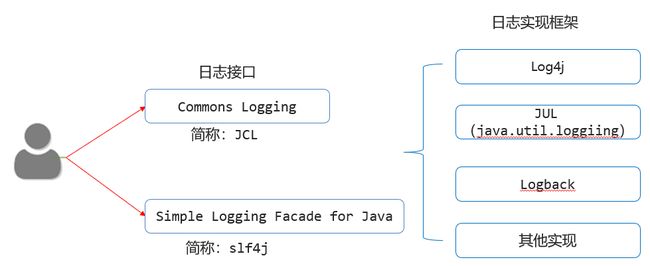
日志接口:一些规范,提供给日志的实现框架设计的标准。
日志框架:牛人或者第三方公司已经做好的代码实现,后来者可以直接拿去使用。
注意:因为对 Commons Logging 接口不满意,有人就搞了slf4j 。因为对 Log4j 的性能不满意,有人就搞了 Logback ,Logback是基于slf4j的日志规范实现的框架。
1.5 Logback框架
1.5.1 下载地址
1.5.2 模块组成
Logback框架分为以下三个模块
Logback-core:该模块为其他二个模块提供基础代码。(必须有)
Logback-classic:完整实现了slf4j API的模块。(必须有)
Logback-access:该模块用于与tomcat,Jetty等servlet容器集成,以提供HTTP访问日志功能。(可选)
1.5.3 Logback的使用
想使用Logback,必须在项目中整合如下三个部分
slf4j-api:日志接口
Logback-core:基础模块
Logback-classic:功能模块,它完整实现了slf4j-api
二.XML
2.1 XML概述
XML是可扩展标记语言的缩写,它是一种数据表示格式,可以描述非常复杂的数据结构,常用于存储和传输数据。
2.2 XML的特点
1. XML语言书写的内容是纯文本,默认使用UTF-8编码。
2. 如果把XML内容存为文件,那么他就是一个XML文件。
2.3 XML文件的使用场景
1.XML文件经常被当成消息进行网络传输。
2.XML文件可以作为配置文件存储系统的信息。
2.4 XMl文件的创建
就是创建一个XML类型的文件,要求文件的后缀必须使用xml,如hello_w orld.xml
2.5 XML的语法规则
1. XML文件的后缀名必须是xml。
2. 文档声明必须是在第一行。
3. XML文件中可以定义注释信息,格式为:
4. XML文件中可以存在以下特殊字符。因为XML不一定能正确识别关系运算符等特殊字符,所以用其他字符代替。

5. XML文件中可以存在CDATA区: 。
当大量的转义字符出现在xml文档中时,会使xml文档的可读性大幅度降低。这时如果使用CDATA段就会好一些。
在CDATA段中出现的“<”、“>”、“””、“’”、“&”,都无需使用转义字符。这可以提高xml文档的可读性。
在CDATA段中不能包含“]]>”,即CDATA段的结束定界符

2.6 XML的标签(元素)规则
1. 标签由一对尖括号和合法标识符组成 :
2. 标签必须成对出现,有开始,有结束 :
3. 特殊的标签可以不成对,但是必须有结束标记,如 : < br />
4. 标签中可以定义属性,属性和标签名空格隔开 , 属性值必须用引号引起来 “ 1 ” >
5. 标签需要正确的嵌套
2.7 文档约束
1.问题引出
由于XML文件可以自定义标签,导致XML文件可以随意定义,程序在解析的时候可能出现问题。
2.什么是文档约束
是用来限定XML文件中的标签和属性应该怎么写。
3.文档约束的分类
文档约束分为DTD和schema
2.8 XML文档约束——DTD
1.需求:使用DTD文档约束,约束一个XML文件的编写。
2.步骤:
①编写DTD约束文档,后缀必须是.dtd。一般不用我们编写,后面的框架技术会帮我们准备好。

②在需要编写XML文件中导入该DTD约束文档。
③按照约束的规则编写XML文件的内容。
3.注意事项
不能约束具体的数据类型。
2.9 XML文档约束——schema
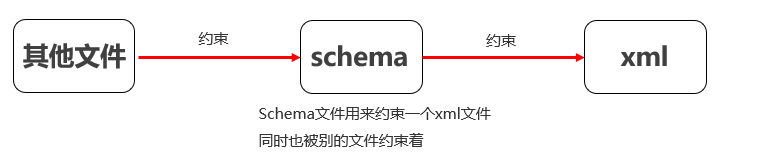
1.需求:
利用schema文档约束,约束一个XML文件的编写
2.步骤:
①编写schema文档约束,后缀必须是.xsd,具体的形式到代码中观看。
②在需要编写的XML文件中导入该schema约束文档
③按照约束内容编写XML标签
3.优点
①schema 可以约束具体的数据类型,约束能力上更强大。
②schema 本身也是一个 xml 文件,本身也受到其他约束文件的要求,所以编写的更加严谨
三.XML解析技术
3.1 什么是XML解析
使用程序读取XML文件中的数据。
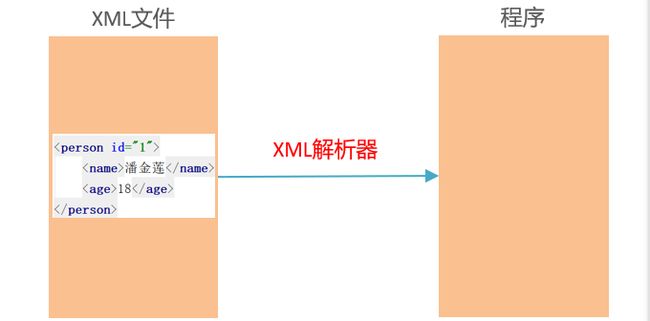
3.2 分类
XMl解析分为SAX解析和DOM解析。
DOM解析:把整个XML文档读取到内存形成一棵文档树对象。
SAX解析: 逐行扫描XML文档,一边扫描一遍解析。
3.3 DOM解析
1.什么是DOM解析
把整个XML文档读取到内存形成一棵文档树对象,把XML文档中的每个标签、属性、数据看成一个个结点,然后对这些结点进行操作。
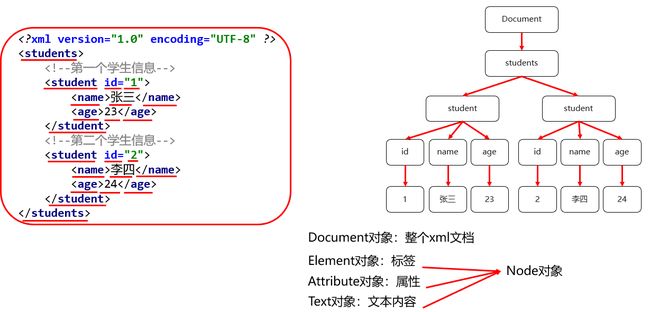
2.DOM常见的解析工具

3.4 DOM4J
1.需求:使用DOM4J解析XML文件
2.步骤:
①去官网下载DOM4J框架
②在项目中创建一个lib文件夹
③将dom4j框架所需的jar包复制到lib文件夹下
④在jar文件上右键, 选择 Add as Library -> 点击 OK
⑤在类中导包使用
3.DOM4J常用API:
SAXReader用于创建解析器对象,代表整个DOM4J对象。
Documnet类代表整个XML文档对象,Documnet对象用SAXReader的read方法获取。

DOM4J解析XML文件中的各种结点所需API:
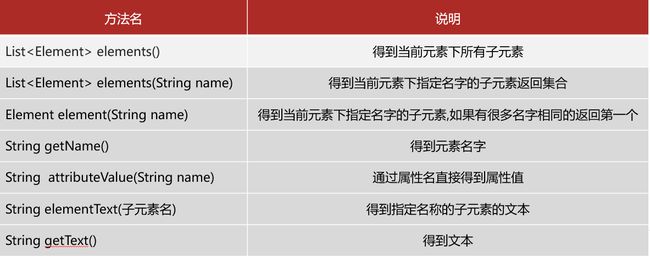
3.5 示例代码
使用DOM4J提供的API进行文档的解析
xml文件代码:
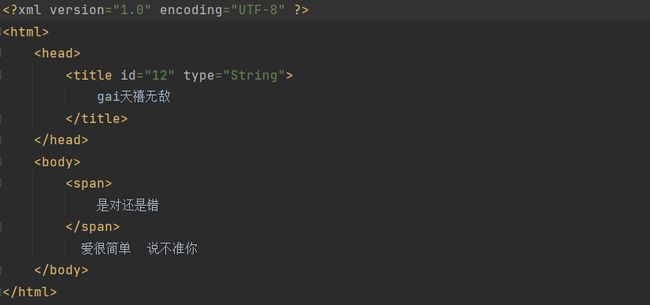
解析代码:
public class TestDemo {
//目标:掌握Dom4j框架的使用
public static void main(String[] args) throws DocumentException {
//1.创建解析器对象,代表整个Dom4j框架
SAXReader saxReader = new SAXReader();
//2.把整个XML文件读取到内存中成为一个Document对象
//使用Class类中提供的方法获取xml文件的输入流,可以随便找个类对象
InputStream is = Student.class.getResourceAsStream("/testfile.xml");
Document document = saxReader.read(is);
//3.使用框架提供的API
// 获取document文档对象的根元素对象
Element rootElement = document.getRootElement();
System.out.println(rootElement.getName());
//获取根对象下的所有子元素对象
List elements = rootElement.elements();
for (Element element : elements) {
System.out.println(element.getName());
}
//获取根对象下的某个子元素对象
Element body = rootElement.element("body");
System.out.println(body.getText());
System.out.println(body.getTextTrim());
//获取属性值
Element head = rootElement.element("head");
Element title = head.element("title");
Attribute id = title.attribute("id");
System.out.println(id.getName()+"-->"+id.getValue());
String type = title.attributeValue("type");
System.out.println(type);
}
} 四.XML检索技术
4.1 XML检索技术概述
XPath 使用 路径表达式 来定位 XML 文档中的元素节点或属性节点 。
4.2 步骤
1. 导入 jar 包 (dom4j的 和 jaxen-1.1.2.jar) , Xpath 技术依赖 Dom4j 技术
2. 通过 dom4j 的 SAXReader 获取 Document 对象
3. 利用 XPath 提供的 API, 结合 XPath 的语法完成选取 XML 文档元素节点进行解析操作。
4.3 Document中与Xpath相关的API
4.4 Xpath的四大检索方案
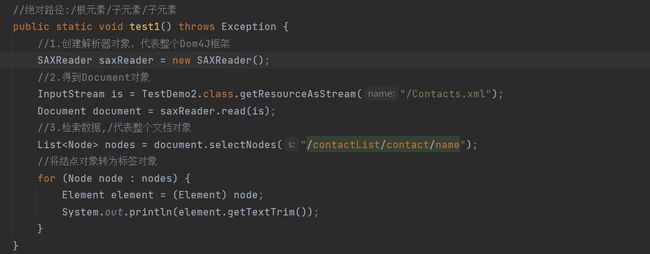
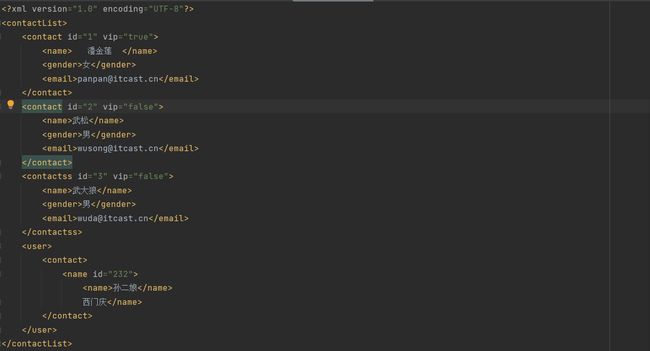
4.4.1 绝对路径
采用绝对路径获取从根节点开始逐层的查找
代码示例:
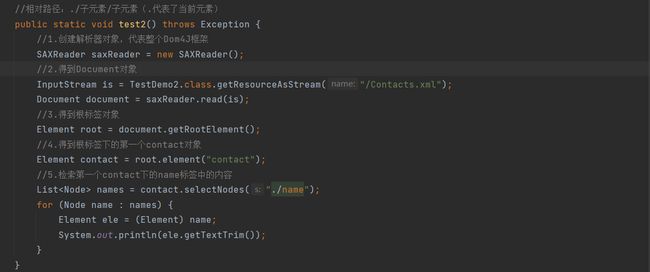
4.4.2 相对路径
先得到根节点 contactList, 再采用相对路径获取下一级 contact 节点的 name 子节点并打印信息
代码示例:
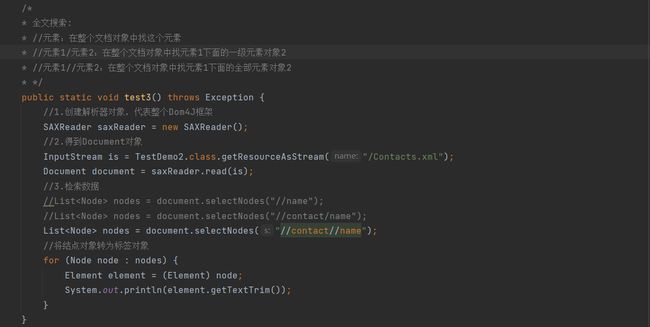
4.4.3 全文检索
直接全文搜索所有的 name 元素并打印

代码示例:
4.4.4 属性查找
在全文中搜索属性,或者带属性的元素

代码示例: