Python爬虫|Scrapy 基础用法
scrapy 框架
目录
- scrapy 框架
-
- 1. scrapy 是什么?
-
- ① scrapy 架构组成 (基本模块概述)
- ② scrapy 工作原理
- ③ scrapy 工作原理图
- 2. scrapy 框架的基本使用
-
- ① 基本使用方法
- ② spiders 自定义文件内部
- ③ response 常用的方法
- 3. scrapy shell
-
- ① 什么是 scrapy shell?
- ② 安装 ipython
- ③ 进入到 scrapy终端
- 4. pipelines 管道封装
-
- 4.1 yield 关键字
- 4.2 管道封装(单管道)
-
- ① 确定数据结构
- ② 获取网页内容
- ③ 管道操作
- ④ 开启管道(单)
- 4.3 开启多管道
- 5. 日志信息和日志等级
- 6. scrapy 的 post请求
- 7. 设置代理
- 8. CrawlSpider
-
- ① CrawlSpider 概述
- ② 运行原理图
- ③ CrawlSpider案例
- 9. ★ 写代码注意点(业务逻辑)
- 10. 案例代码 (使用CrawlSpider)
-
- ① football.py (spiders)
- ② items.py
- ③ piplines.py
- ④ settings.py
- ⑤ start.py (启动文件)
- 11. scrapy 的一些注意点 (特性)
-
- ① scrapy 采用异步下载
- ② 使用默认方法下载图片注意点
- ③ meta 为只读属性
- ④ 导入 settings 失败
1. scrapy 是什么?
Scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理
或存储历史数据等一系列的程序中。
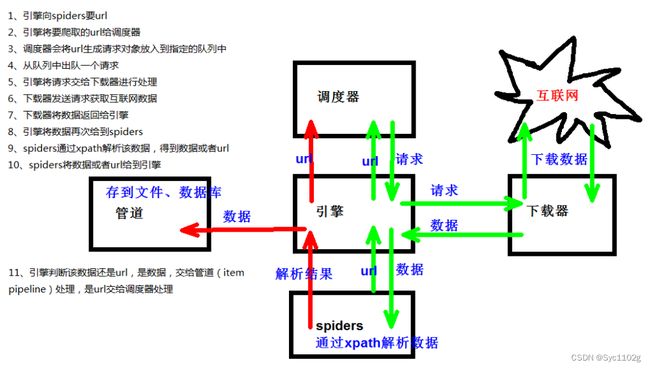
① scrapy 架构组成 (基本模块概述)
- 调度器(Scheduler)
调度器,可以把它假设成为一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是什么,同时去除重复的网址(不做无用功)。用户可以自己的需求定制调度器。 - 下载器(Downloader)
下载器,是所有组件中负担最大的,它用于高速地下载网络上的资源。Scrapy 的下载器代码不会太复杂,但效率高,主要的原因是整个 Scrapy框架都在建立在 twisted 这个高效的异步模型上的, Scrapy 下载器也是是建立在 twisted 这个高效的异步模型上的。 - 爬虫(Spider)
爬虫,是用户最关心的部分。用户定制自己的爬虫(通过定制正则表达式等语法),用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。例如使用 Xpath 提取感兴趣的信息。
用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。 - 实体管道(Item Pipeline)
实体管道,用于接收网络爬虫传过来的数据,并经过几个特定的次序处理数据,典型的任务包括验证实体的有效性、清除不需要的信息、存入数据库(持久化实体)、存入文本文件等。 - Scrapy引擎(Scrapy Engine)
Scrapy 引擎是整个框架的核心,用来处理整个系统的数据流,触发各种事件。它用来控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程。 - 中间件(Middlewares)
整个 Scrapy 框架有很多中间件,如下载器中间件、网络爬虫中间件等,这些中间件相当于过滤器,夹在不同部分之间截获数据流,并进行特殊的加工处理。
② scrapy 工作原理
(1)引擎 ‐‐‐> 自动运行,无需关注,会自动组织所有的请求对象,分发给下载器
(2)下载器 ‐‐‐> 从引擎处获取到请求对象后,请求数据
(3)spiders ‐‐‐> Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例 如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及 分析某个网页(或者是有些网页)的地方。
(4)调度器 ‐‐‐> 有自己的调度规则,无需关注
(5)管道(Item pipeline) ‐‐‐> 最终处理数据的管道,会预留接口供我们处理数据
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。 每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行 一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
以下是item pipeline的一些典型应用:
1. 清理HTML数据
2. 验证爬取的数据(检查item包含某些字段)
3. 查重(并丢弃)
4. 将爬取结果保存到数据库中
③ scrapy 工作原理图

2. scrapy 框架的基本使用
① 基本使用方法
1. 创建 scrapy项目:
先切换到项目所要放置的位置: cd /d D:\Pycharm\untitled2\Python-爬虫\10. Scrapy 框架
终端输入: scrapy startproject 项目名称
注意:
1. 项目名称不能以数字开头!
2. 爬虫文件不能以汉字开头,项目名称可以,但不建议
项目组成:
spiders
__init__.py 自定义的爬虫文件.py ‐‐‐> 由我们自己创建,是实现爬虫核心功能的文件
__init__.py
items.py ‐‐‐> 定义数据结构的地方,是一个继承自 scrapy.Item的类
middlewares.py ‐‐‐> 中间件 代理
pipelines.py ‐‐‐> 管道文件,里面只有一个类(可以增加),用于处理筛选出来的的实体数据(如将数据存储在数据库中),默认是300优先级,值越小优先级越高(1‐1000)
settings.py ‐‐‐> 配置文件 比如:是否遵守robots协议,User‐Agent定义等
2. 创建爬虫文件
(1) 切换到项目中的 spiders目录下
cd 目录名字/目录名字/spiders
cd scrapy_baidu_01\scrapy_baidu_01\spiders
(2) 创建爬虫文件
scrapy genspider 爬虫名字 网页的域名
scrapy genspider baidu http://www.baidu.com
爬虫文件的基本组成:
继承scrapy.Spider类
name = 'baidu' ‐‐‐> 运行爬虫文件时使用的名字
allowed_domains ‐‐‐> 爬虫允许的域名,在爬取的时候,如果不是此域名之下的 url,会被过滤掉
start_urls ‐‐‐> 声明了爬虫的起始地址,可以写多个url,一般是一个
parse(self, response) ‐‐‐> 解析数据的回调函数
response.text ‐‐‐> 响应的是字符串
response.body ‐‐‐> 响应的是二进制文件
response.xpath()‐> xpath方法的返回值类型是selector列表
extract() ‐‐‐> 提取的是 selector对象的是 data
extract_first() ‐‐‐> 提取的是 selector列表中的第一个数据
3. 运行爬虫代码
scrapy crawl 爬虫名称
【注意】:应在 spiders 文件夹内执行
将 settings文件中 的 ROBOTSTXT_OBEY = True 注释掉,就不用遵守 robots君子协议了

【注意1】:start.py 文件和 scrapy_cfg 文件处于同一级目录
【注意2】:此启动方法会使得代码中的相对路径出错,原本是相对于 piplines.py 或者 settings.py 所在目录那一级,现在是相对于 start.py 文件!
设置请求头
在 settings.py 文件中取消以下代码段,添加请求头
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
# 其中可以加入请求头内容
② spiders 自定义文件内部
name = 'baidu' # 爬虫的名字 用于运行爬虫的时候 使用的值
allowed_domains = ['http://www.baidu.com'] # 允许访问的域名
# 注意如果你的请求的接口是html为结尾的 那么是不需要加/的
start_urls = ['http://www.baidu.com/'] # 起始的url地址 指的是第一次要访问的域名,在 allowed_domains的后面添加一个/
# 是执行了start_urls之后 执行的方法 方法中的response 就是返回的那个对象
# 相当于 response = urllib.request.urlopen()
# response = requests.get()
def parse(self, response):
print('ok!')
③ response 常用的方法
response.text # str 字符串 数据
response.body # 二进制 bytes 数据
response.status # 状态码
response.url # 页面 url
response.xpath() # 使用 xpath 语法,通过 xpath 方法调用返回的是 seletor列表
response.css() # 使用 css语法(非常不建议,十分麻烦)
# 使用 css_selector 查询元素,返回一个 selector列表对象
# 获取内容 :response.css('#su::text').extract_first()
# 获取属性 :response.css('#su::attr(“value”)').extract_first() 不好用!
response.extract() # 提取 selector对象的 data属性值 (如果是多个值,返回列表!)
# 提取 selector对象的值
# 如果提取不到值,那么会报错
# 使用 xpath 请求到的对象是一个 selector对象,需要进一步使用 extract() 方法拆包,转换为 unicode字符串
response.extract_first() # 提取 selector列表的第一个数据 # 对列表的操作!
# 提取 seletor列表中的第一个值
# 如果提取不到值,会返回一个空值
# 返回第一个解析到的值,如果列表为空,此种方法也不会报错,会返回一个空值
response.getall() # getall()方法和extract()方法一样,返回的都是符合要求的所有的数据,存在一个列表里
response.get() # get()方法和 extract_first() 方法返回的是一样的,都是列表里的第一个数据
# get() 、getall() 方法是新的方法,extract() 、extract_first()方法是旧的方法。
# extract() 、extract_first()方法取不到就返回None。
# get() 、getall() 方法取不到就raise一个错误
'''
extract_first() 不能针对单个选择器!get()、getall()、extract()都可以!
如:
# 注意:每一个selector对象可以再次的去使用xpath或者css方法
3. scrapy shell
① 什么是 scrapy shell?
Scrapy终端,是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码。 其本意是用来测试提取
数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码。
该终端是用来测试XPath或CSS表达式,查看他们的工作方式及从爬取的网页中提取的数据。 在编写您的spider时,该
终端提供了交互性测试您的表达式代码的功能,免去了每次修改后运行spider的麻烦。
一旦熟悉了Scrapy终端后,您会发现其在开发和调试spider时发挥的巨大作用。
② 安装 ipython
如果您安装了 IPython ,Scrapy终端将使用 IPython (替代标准Python终端)。 IPython 终端与其他相 比更为强大,提供智能的自动补全,高亮输出,及其他特性。
③ 进入到 scrapy终端
进入到scrapy shell的终端,直接在window的终端中输入: scrapy shell 域名
如果想看到一些高亮 或者 自动补全 那么可以安装 ipython: pip install ipython
# scrapy shell www.baidu.com
4. pipelines 管道封装
懒加载
也叫延迟加载,指的是在长网页中延迟加载图像,是一种很好优化网页性能的方式。
懒加载的优点:
- 提升用户体验,加快首屏渲染速度;
- 减少无效资源的加载;
- 防止并发加载的资源过多会阻塞 js 的加载;
懒加载的原理:
首先将页面上的图片的 src 属性设为空字符串,而图片的真实路径则设置在 data-original 属性中,当页面滚动的时候需要去监听 scroll 事件,在 scroll 事件的回调中,判断我们的懒加载的图片是否进入可视区域,如果图片在可视区内则将图片的 src 属性设置为 data-original 的值,这样就可以实现延迟加载。
因此,如果图片有 data-original属性,在提取链接时,就用 data-original属性获取链接,不要用 src 了!
一般第一张图片没有 data-original属性,后面的有,要判断一下
# 第一张图片和其他的图片的标签的属性是不一样的
# 第一张图片的 src 是可以使用的 其他的图片的地址是 data-original
4.1 yield 关键字
在 spiders 目录下的主爬虫文件中使用!
1. 带有 yield 的函数不再是一个普通函数,而是一个生成器 generator,可用于迭代
2. yield 是一个类似 return 的关键字,迭代一次遇到 yield 时就返回 yield 后面(右边)的值。
重点是:下一次迭代时,从上一次迭代遇到的yield后面的代码(下一行) 开始执行
3. 简要理解:yield就是 return 返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后(下一行)开始
- yield 在 scrapy 中的推送方式
在 scrapy 中,yield 将内容推送给引擎来处理(引擎交给piplines 处理)

# 1. 推送 item对象
# 获取一个book就将book交给pipelines,一个book就是一个item对象
book = ScrapyDangdangItem(name=name, price=price, img_src=img_src)
yield book # 数据提交给引擎,用 yield关键字
# 或这样写
# book = ScrapyDangdangItem()
# book['name'] = name,
# book['price'] = price
# book['img_src'] = img_src
# yield book # 数据提交给引擎,用 yield关键字
# 2. 直接推送字典dict
# 可以直接 yield 一个字典对象
yield {
'src':src,
'name',name,
'price':price,
}
# 3. 推送 request请求
# 继续请求
yield scrapy.Request(url=url, callback=self.parse)
'''
scrapy.Request就是scrpay的get请求
url就是请求地址
callback 是要执行的那个函数,注意不需要加()
'''
4.2 管道封装(单管道)
① 确定数据结构
- 在 items.py 文件中的数据结构对象中创建给每一个下载对象创建 scrapy.Field()
class ScrapyDangdang095Item(scrapy.Item):
# define the fields for your item here like:
# 这里的数据结构通俗的说就是你要下载的数据都有什么
# 图片
src = scrapy.Field()
# 名字
name = scrapy.Field()
# 价格
price = scrapy.Field()
② 获取网页内容
- 在 spiders 目录下的主 py文件中拿到需要下载的内容后,导入 items.py 文件中所需要的"数据结构对象"
# 在将主py文件中的parse(self,response)函数中把拿到的scr、name、price传入"数据结构对象",并复制给一个对象, 然后yield 出去
def parse(self, response):
src = 获取 src 数据
name = 获取 name 数据
price = 获取 price 数据
book = ScrapyDangdang095Item(src=src,name=name,price=price)
yield book
# 如果是单数据管道,可以直接 yield 一个字典对象,默认传给那个唯一的管道
'''
yield {
'src':src,
'name',name,
'price':price,
}
'''
③ 管道操作
- 在 pipelines.py 文件中进行下载的操作
# 如果想使用管道的话 那么就必须在 settings 中开启管道
class ScrapyDangdang095Pipeline:
# 在爬虫文件开始的之前就执行的一个方法
def open_spider(self,spider):
self.fp = open('book.json','w',encoding='utf-8')
# item 就是 yield 后面的 book对象
def process_item(self, item, spider):
# 以下这种模式不推荐,因为每传递过来一个对象,就打开一次文件,写完就关闭,对文件的操作过于频繁
# (1) write方法必须要写一个字符串 而不能是其他的对象
# (2) w模式,因为上述机制,每一个对象都打开一次文件,会覆盖之前的内容,只能用append模式
# with open('book.json','a',encoding='utf-8')as fp:
# fp.write(str(item))
self.fp.write(str(item))
return item
# 在爬虫文件执行完之后 执行的方法
def close_spider(self,spider):
self.fp.close()
④ 开启管道(单)
- 需要在 settings.py 文件中将以下代码取消注释,设置数据结构对象优先级
ITEM_PIPELINES = {
# 管道:优先级(值越小优先级越高)
'scrapy_dangdang_095.pipelines.ScrapyDangdang095Pipeline': 300,
}
管道封装(多管道)
4.3 开启多管道
piplines.py 文件中的管道可以开多个,按优先级依次运行,注册之后需要在 settings.py 中配置一下才会生效
每个pipline之间存在着现后逻辑关系,都可以处理item,处理完之后提交到下一个pipline里面
最后的 return item,这个item将会被提交到下一个pipline里面进行处理
- ① 需要在 settings.py 文件中将以下代码取消注释,设置优先级
ITEM_PIPELINES = {
# 管道可以有很多个,那么管道是有优先级的,优先级的范围是1到1000,值越小优先级越高
'scrapy_dangdang_095.pipelines.ScrapyDangdang095Pipeline': 300,
# DangDangDownloadPipeline
'scrapy_dangdang_095.pipelines.DangDangDownloadPipeline':301
}
- ② 在 pipelines.py 文件中进行下载等管道操作
# 如果想使用管道的话 那么就必须在 settings 中开启管道
class ScrapyDangdang095Pipeline:
# 在爬虫文件开始的之前就执行的一个方法
def open_spider(self,spider):
self.fp = open('book.json','w',encoding='utf-8')
# item就是yield后面的book对象
def process_item(self, item, spider):
self.fp.write(str(item))
return item # 必须加,否则其他管道就无法获得item了!
'''
# 每个pipline之间存在着现后逻辑关系,都可以处理item,处理完之后提交到下一个pipline里面。
# 最后的return item,这个item将会提交到下一个pipline里面进行处理。
'''
# 在爬虫文件执行完之后 执行的方法
def close_spider(self,spider):
self.fp.close()
# ★第二个管道
import urllib.request
# 多条管道开启
# (1) 定义管道类
# (2) 在 settings 中开启管道
# 'scrapy_dangdang_095.pipelines.DangDangDownloadPipeline':301
class DangDangDownloadPipeline:
def process_item(self, item, spider):
url = 'http:' + item.get('src')
filename = './books/' + item.get('name') + '.jpg'
urllib.request.urlretrieve(url = url, filename= filename)
return item
5. 日志信息和日志等级
(1)日志级别:
CRITICAL:严重错误
ERROR: 一般错误
WARNING: 警告
INFO: 一般信息
DEBUG: 调试信息
默认的日志等级是 DEBUG,只要出现了DEBUG或者DEBUG以上等级的日志,那么这些日志将会打印
(2)settings.py文件设置:
默认的级别为DEBUG,会显示上面所有的信息
在配置文件中 settings.py
LOG_FILE : 将屏幕显示的信息全部记录到文件中,屏幕不再显示,注意文件后缀一定是.log (推荐使用该方法)
LOG_FILE = 'log保存路径'
LOG_LEVEL : 设置日志显示的等级,就是显示哪些,不显示哪些(一般不设置)
LOG_LEVEL = 'WARNING'(不建议)
6. scrapy 的 post请求
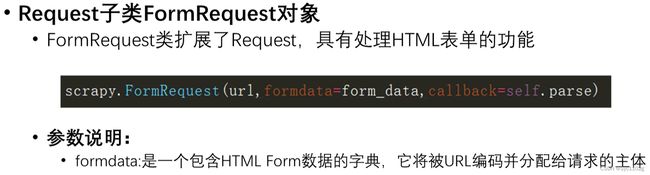
(1) 重写 start_requests 方法(spiders目录下的爬虫文件中):
def start_requests(self)
url = 'https://fanyi.baidu.com/sug' # 开始的 url
data = {
'kw': 'final' # post参数
}
yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse_second)
(2) start_requests的返回值:
yield scrapy.FormRequest(url=url, headers=headers, callback=self.parse_item, formdata=data)
url: 要发送的post地址
headers:可以定制头信息
callback: 回调函数
formdata: post所携带的数据,这是一个字典

用途
用来模拟登录
7. 设置代理
(1) 到 settings.py 中,打开一个选项
DOWNLOADER_MIDDLEWARES = {
'postproject.middlewares.Proxy': 543,
}
(2) 到 middlewares.py 中写代码
def process_request(self, request, spider):
request.meta['proxy'] = 'https://113.68.202.10:9999'
return None
8. CrawlSpider
① CrawlSpider 概述
1.继承自 scrapy.Spider
创建爬虫文件时加参数:scrapy genspider ‐t crawl 爬虫文件名 域名 # 注意 参数 ‐t crawl
2.特点
CrawlSpider可以定义规则,再解析html内容的时候,可以根据链接规则提取出指定的链接,然后再向这些链接发送请求
所以,如果有需要跟进链接的需求,意思就是爬取了网页之后,需要提取链接再次爬取,使用CrawlSpider是非常合适的,不用手动提取想要的 url,这些操作都会由 LinkExtractors 根据链接规则自动提取并爬取
3.应用
① 爬取多页内容
② 爬取详情页,继续一层一层爬取
3.提取链接
链接提取器,在这里就可以写规则提取指定链接
scrapy.linkextractors.LinkExtractor(
allow = (), # 正则表达式 提取符合正则的链接(提取 http://www.baidu.com 后的即可)
deny = (), # (不用)正则表达式 不提取符合正则的链接
allow_domains = (), # (不用)允许的域名
deny_domains = (), # (不用)不允许的域名
restrict_xpaths = (), # xpath,提取符合xpath规则的链接
restrict_css = () # 提取符合选择器规则的链接)
4.模拟使用
正则用法:links1 = LinkExtractor(allow=r'list_23_\d+\.html')
xpath用法:links2 = LinkExtractor(restrict_xpaths=r'//div[@class="x"]')
css用法:links3 = LinkExtractor(restrict_css='.x')
5.提取连接
link.extract_links(response)
6.注意事项
【注1】callback只能写函数名字符串, callback='parse_item'
【注2】在基本的spider中,如果重新发送请求,那里的callback写的是 callback=self.parse_item
【注3】follow=true 是否跟进 就是按照提取连接规则进行提取


② 运行原理图

③ CrawlSpider案例
需求:读书网数据入库
1.创建项目:scrapy startproject dushuproject
2.跳转到spiders路径 cd\dushuproject\dushuproject\spiders
3.创建爬虫类:scrapy genspider ‐t crawl read www.dushu.com // 注意 参数 ‐t crawl
4.items
5.spiders
6.settings
7.pipelines
数据保存到本地
数据保存到 mysql数据库
9. ★ 写代码注意点(业务逻辑)
数据结构文件(items.py)
- 定义数据结构,(其本身是一个继承自 scrapy.Item的类)
- 为了定义常见的输出数据格式,scrapy 提供了 item 类,Item 对象是用来收集提取数据的简单容器。它们提供了一个类似于字典的API,提供了一种方便的语法,用于声明可用字段。
各种各样的 scrapy 组件使用由 item 提供的附加信息,查看已声明的字段,以找出导出的列,可以使用 item 字段元数据定制序列化,trackref 跟踪项目实例以帮助发现内存泄漏
1. 定义数据结构(固定语法: variable = scrapy.Field())
主爬虫文件
- 解析、匹配数据
1. 向引擎发送 url(allowed_domains、start_urls、可重写 start_urls 方法)
2. 接收自引擎的 response对象,进行处理(解析)
管道文件(piplines.py)
- 负责处理爬虫从网页中抽取的实体数据,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据,典型的任务包括清理,验证和持久性(如将数据存储在数据库中)
1. 在管道类中写处理数据的方法
# piplines.py 文件中的管道可以开多个,运行,写了之后在settings中配置一下就会生效
# piplines的process_item()必须要 ★ return item,否则其他管道无法获取item
# 原理:每个pipline之间存在着现后逻辑关系,都可以处理item,处理完之后提交到下一个pipline里面
# 最后的return item,这个item将会提交到下一个pipline里面进行处理
配置文件(settings.py )
- 配置相关信息
# 常用的配置
ROBOTSTXT_OBEY = False # ★ 是否遵循爬虫协议
USER_AGENT = 'Amazon (+http://www.yourdomain.com)' # 客户端 User-Agent 请求头
COOKIES_ENABLED = True # 是否支持cookie,cookiejar进行操作cookie
CONCURRENT_REQUESTS_PER_DOMAIN = 16默认值8 # 每个域名能够被执行的最大并发请求数目
DOWNLOAD_DELAY = 3 # 对同一网址延迟请求的秒数,延时时间不能动态改变,防止下载速度过快对网站服务器造成影响,容易被发现
RANDOMIZE_DOWNLOAD_DELAY = True # 启用后,当从同一的网站获取数据时,Scrapy将会等待一个随机的值,延迟时间为0.5到1.5之间的一个随机值乘以 DOWNLOAD_DELAY
# 以上二者适合搭配使用:DOWNLOAD_DELAY 设置两次请求间隔是4秒,RANDOMIZE_DOWNLOAD_DELAY 设置请求间隔随机开启,也就是实际间隔是0.5-1.5倍的DOWNLOAD_DELAY之间(2~6)的随机数。
LOG_FILE = None # ★ 日志存储文件路径
LOG_LEVEL = 'DEBUG' # 全局日志级别, 值域: CRITICAL, ERROR, WARNING, INFO, DEBUG
LOG_FORMAT = '%(asctime)s [%(name)s] %(levelname)s: %(message)s' # 日志格式化样式, 实际使用中配置json字符串结构方便采集
# 能够被单个IP处理的并发请求数
# 默认值0,代表无限制,需要注意两点
# 如果不为零,那CONCURRENT_REQUESTS_PER_DOMAIN将被忽略,即并发数的限制是按照每个IP来计算,而不是每个域名
# 该设置也影响DOWNLOAD_DELAY,如果该值不为零,那么DOWNLOAD_DELAY下载延迟是限制每个IP而不是每个域
CONCURRENT_REQUESTS_PER_IP = 16
# ★ 全局ITEM 管道配置
ITEM_PIPELINES = {
'scrapy_football.pipelines.XXXPipeline': 300,
}
# 全局设置使用的请求头,,不建议配置, 建议在spider中配置或处理层配置
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en'
}
# 局部设置使用的请求头
# 爬虫程序类中设置
custom_settings = {
'DEFAULT_REQUEST_HEADERS' : {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
}
DOWNLOAD_DELAY
默认值:0
Downloader从同一网站上访问页面应该等待的时间。这个设置常常被用来控制爬取的速度,以免对网站造成太大的压力。这个值的单位为秒,并且可以使用小数。
这个值同样被RANDOMIZE_DOWNLOAD_DELAY所影响。在默认的情况下,Scrapy不会每次都等待一个固定的时间,而是使用一个范围在0.5-1.5之间的值乘以DOWNLOAD_DELAY。
当CONCURRENT_REQUESTS_PER_IP的值不为0时,延迟将按照每个IP判断,而不再是Domain。
这个设置可以在Spider中通过download_delay属性进行设置。
RANDOMIZE_DOWNLOAD_DELAY
默认值:True
如果启用,那么DOWNLOAD_DELAY等待的时间将会随机乘以范围在0.5-1.5之间的一个小数。这个设置的作用是使爬虫的等待时间更有随机性,更难以被检测。
10. 案例代码 (使用CrawlSpider)
普通版本_1 (不使用 CrawlSpider) 下载多层请求、多页数据(图片):Scrapy 下载多层请求、多页图片(下载使用urllib.request.urlretrieve方法)
普通版本_2 (不使用 CrawlSpider) 下载多层请求、多页数据(图片):Scrapy 下载多层请求、多页图片 (重写get_media_requests、file_path方法)
① football.py (spiders)
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import ScrapyFootballItem
class FootballSpider(CrawlSpider):
name = 'football'
allowed_domains = ['mynba.tv']
start_urls = ['http://www.mynba.tv/video/?page=1']
rules = (
Rule(LinkExtractor(allow=r'\?page=\d+'), follow=True),
Rule(LinkExtractor(allow=r'/video/.*?\.html'), callback='parse_item', follow=False),
)
def parse_item(self, response):
# 匹配数据
game_title = response.xpath('//*[@id="app"]/div/div[4]/div/div[2]/p[1]/text()').extract_first()
name_1 = response.xpath('//*[@id="app"]/div/div[4]/div/div[1]/p/a/text()').extract_first()
logo_src_1 = response.xpath('//*[@id="app"]/div/div[4]/div/div[1]/img/@src').extract_first()
name_2 = response.xpath('//*[@id="app"]/div/div[4]/div/div[3]/a/text()').extract_first()
logo_src_2 = response.xpath('//*[@id="app"]/div/div[4]/div/div[3]/img/@src').extract_first()
info = ScrapyFootballItem(game_title=game_title, name_1=name_1, logo_src_1=logo_src_1, name_2=name_2,logo_src_2=logo_src_2)
yield info
② items.py
import scrapy
class ScrapyFootballItem(scrapy.Item):
game_title = scrapy.Field() # 比赛详情标题
name_1 = scrapy.Field() # 主队球队名称
logo_src_1 = scrapy.Field() # 主队球队logo
name_2 = scrapy.Field() # 客队球队名称
logo_src_2 = scrapy.Field() # 客队球队logo
③ piplines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import xlwt
class ScrapyFootballPipeline:
def open_spider(self, spider):
self.workbook = xlwt.Workbook()
self.worksheet = self.workbook.add_sheet('sheet1')
self.line_cnt = 0
self.col_name = ['game_title', 'name_1', 'logo_src_1', 'name_2', 'logo_src_2']
# 写入表头
for i in range(4):
self.worksheet.write(self.line_cnt, i, self.col_name[i])
self.line_cnt += 1
def process_item(self, item, spider):
# 写入数据
for i in range(4):
self.worksheet.write(self.line_cnt,i,item[self.col_name[i]])
self.line_cnt += 1
self.workbook.save('football_data.xls')
return item # 必须加,否则其他管道就无法获得item了!
import urllib.request # 用于下载图片
class ScrapyFootballPipeline_2:
def process_item(self, item, spider):
img_src_1 = item['logo_src_1']
img_src_2 = item['logo_src_2']
name_1 = img_src_1.split('/')[-1]
name_2 = img_src_2.split('/')[-1]
urllib.request.urlretrieve(img_src_1,filename=f'img/{name_1}')
urllib.request.urlretrieve(img_src_2,filename=f'img/{name_2}')
return item
④ settings.py
BOT_NAME = 'scrapy_football'
SPIDER_MODULES = ['scrapy_football.spiders']
NEWSPIDER_MODULE = 'scrapy_football.spiders'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 3
RANDOMIZE_DOWNLOAD_DELAY = True
ITEM_PIPELINES = {
'scrapy_football.pipelines.ScrapyFootballPipeline': 300,
'scrapy_football.pipelines.ScrapyFootballPipeline_2': 301,
}
⑤ start.py (启动文件)
from scrapy import cmdline
cmdline.execute('scrapy crawl football'.split(' '))
11. scrapy 的一些注意点 (特性)
用过几次 scrapy 写爬虫后,对这个框架的一些特性有所感悟
① scrapy 采用异步下载
Scrapy 的下载器代码不会太复杂,但效率高!
主要的原因是 Scrapy 下载器是建立在 twisted 这个高效的异步模型上的(其实整个框架都在建立在这个模型上的)
scrapy 采用异步处理请求,即scrapy发送请求之后,不会等待这个请求的响应(也就是不会阻塞),而是可以同时发送其他请求或者做别的事情。而我们知道服务器对于请求的响应是由很多方面的因素影响的,如网络速度、解析速度、资源抢占等等,其响应的顺序是难以预测的。
scrapy异步的根源,在于它依赖于Twisted框架。Twisted框架是一个Python的event-driven的框架,这里可以理解为是异步I/O的。爬取内容时输出的顺序可能每次运行时都不一样
scrapy也支持多线程
② 使用默认方法下载图片注意点
官方文档
如果使用默认的方法对数据处理:
如果单纯获取文本,那么只需start_urls是一个list;
而如果获取图片,则必须 start_urls与item中存储图片路径字段这两者必须都是 list,并且存储图片路径字段必须是 image_urls
【注意】:可以在 get_media_requests 中把相应地方重写了
如果涉及下列方式下载图片
1.用 ImagesPipeline 的默认方法下载或者不修改 ImagesPipeline 的 get_media_requests的返回值
2.重写 ImagesPipeline 的 get_media_requests 方法,但不修改其返回值(即返回值还是一个 Request请求对象列表)
那么item中存储图片路径字段必须是 list! 即:这里要下载的图片(即使只有一张) url 必须命名为 image_urls 放到 list 中传送给 item
除非重写 ImagesPipeline 的 get_media_requests 的方法的返回值(本是一个请求对象的列表,修改为返回单个Request请求对象即可)
参考链接
③ meta 为只读属性
# request.meta = {"item": item} 这里不行!meta为只读属性!想法是给Requests的meta属性添加值,效果一样,都是为了传参用,但只能是在构造函数中 scrapy.Request(meta=) 才能用,其他地方不允许修改值
④ 导入 settings 失败
from bizhi import settings # 记得把根目录标记为: 源/根 后导入
原因: 这个报错的意思是:试图在顶级包(top-level package)之外进行相对导入。也就是说相对导入只适用于顶级包之内的模块
由于在"顶层模块"之外引用包,这里用到"顶层模块"的概念,“顶层模块” 是这执行文件同级的文件
from . import XXX
或者
from .. import XXX
时会遇到这样两个错误:
SystemError: Parent module '' not loaded, cannot perform relative impor
和
ValueError: attempted relative import beyond top-level package
其实这两个错误的原因归根结底是一样的:在涉及到相对导入时,package所对应的文件夹必须正确的被python解释器视作package,而不是普通文件夹。否则由于不被视作package,无法利用package之间的嵌套关系实现python中包的相对导入。
文件夹被python解释器视作package需要满足两个条件:
-
1、文件夹中必须有__init__.py文件,该文件可以为空,但必须存在该文件
-
2、不能作为顶层模块来执行该文件夹中的py文件(即不能作为主函数的入口 模块的__name__ 不能等于__main__)
很多时候就是导入和当前执行的py文件同级的package中的模块时报错: attempted relative import beyond top-level package
此时,该包作为顶层模块(和执行文件同级),已经不被视为一个package了,需要将他们的父级目录标记为源/根
补充:在"from YY import XX"这样的代码中,无论是XX还是YY,只要被python解释器视作package,就会首先调用该package的__init__.py文件。如果都是package,则调用顺序是YY,XX。
也就是说 你不能在一个x.py 文件中 执行 from .模块名 import * 同时运行 python x.py
另外,练习中“from . import XXX”和“from … import XXX”中的’.‘和’…’,可以等同于linux里的shell中’.‘和’…'的作用,表示当前工作目录的package和上一级的package。
Pycharm中的解决方案:把根目录标记为: 源/根 后导入(右键相应文件夹,选择 Mark Directory as Sources 即可)