ICML 2022|达摩院多模态模型OFA,实现模态、任务和架构三个统一
作者:霜清、钟煌、鸿侠

通用统一的预训练大模型逐渐成为AI研究的一大趋势,本文将介绍达摩院提出的多模态模型OFA,是如何实现架构、模态、任务的三个统一。
近年来,基于大规模无监督数据的预训练逐渐成为深度学习研究的热潮,大规模预训练模型也凭借其强大的模型表现和迁移能力逐渐在AI领域扮演着基础模型的角色。近期,包括DeepMind的“通用AI Agent”Gato、通用图文模型Flamingo,及Google Pathway的一系列进展披露,均表明大规模多模态预训练已经逐步成为了未来AI的基础设施,AI模型也逐渐变的更加通用、统一。通用统一的预训练大模型也逐渐成为当前AI研究的一大趋势。
达摩院深耕多模态预训练,并率先探索通用统一模型。此前,达摩院陆续发布了多个版本的M6模型,从大规模稠密模型到超大规模的混合专家模型的探索,逐步从百亿参数升级到十万亿参数规模,在大模型、绿色/低碳AI、服务化、亮点应用等多方面都取得了一定的突破。今年,达摩院重点突破统一范式(模态、任务和架构)的通用多模态预训练框架M6-OFA,希望降低模型在预训练、适配下游模态与任务、以及推理过程中的难度,以便更加便捷地提供预训练、下游任务微调、模型部署、应用发布的大模型全流程服务。目前M6-OFA已被第39届国际机器学习大会(International Conference on Machine Learning (ICML 2022))录用,ICML是机器学习领域三大顶级会议之一。
多模态统一模型OFA的核心思想是将多模态任务表达为序列到序列生成的形式,结合任务特定的instruction在经典的transformer encoder-decoder架构中实现多任务预训练,从而实现以下三个统一。
-
架构统一:使用统一的transformer encoder decoder进行预训练和微调,不再需要针对不同任务设计特定的模型层,用户不再为模型设计和代码实现而烦恼。
-
模态统一:将NLP、CV和多模态任务统一到同一个框架和训练范式,即使你不是CV领域专家,也能轻松接入图像数据,玩转视觉、语言以及多模态AI模型。
-
任务统一:将任务统一表达成Seq2Seq的形式,预训练和微调均使用生成范式进行训练,模型可以同时学习多任务,让一个模型通过一次预训练即可获得多种能力,包括文本生成、图像生成、跨模态理解等。
目前,约10亿参数的OFA-huge模型在训练数据少一到两个数量级的情况下,不仅在图文描述、物体指代理解等多个任务中超越Deepmind Flamingo和Google CoCa,还同时具备高质量的图像生成能力。相关论文已被ICML 2022录用,对应代码、模型、交互式服务也已开源,论文及开源项目可至文末查看详情。
一、OFA任务效果
先来看看效果,OFA在一些任务效果表现上还是蛮神奇的,艺术创作和真实图像生成都不在话下。
而在开放领域的物体指代任务方面,在动漫场景同样能实现精准识别,杰尼龟、路飞,一个都不放过!

因为是基于instruction做多任务预训练,模型类似T0能够根据对任务指令的理解做一些没有学过的任务,比如下列新任务,即针对特定区域的VQA,模型只需要根据输入的问题以及给定的坐标离散化表示便能做出相应的正确回答:

不难看出,OFA已经在“多模态,多任务”这条路上迈出第一步,展现出预训练模型根据人类指令执行不同任务的能力,这也是当前谷歌的Pathways系统所追求的一大目标。
二、OFA基本原理
OFA的作者认为,通用AI模型设计需要具备模态、任务和模型大小等多个方面的可扩展性。为此,文章提出任务无关(TA)、模态无关(MA)、任务足够丰富(TC)等几个在算法设计上需要满足的性质,并指出现有模型没有同时满足这些性质的各类原因,包括Pretrain/Finetune任务表示不一致、额外的Finetune任务相关的结构设计、模态输入对某些任务的依赖。OFA通过一个简单的任务、模态、结构统一的seq2seq框架,在满足以上三个性质的前提下,获得了下游诸多图文跨模态任务的SOTA表现。
OFA的实现原理比较简单,核心模型架构就是最经典的transformer encoder-decoder。为了将预训练和微调都融入到这个架构中,OFA将各类涉及多模态和单模态(即NLP和CV)的各类任务均表达为Sequence-to-Sequence的形式,使用上述encoder-decoder模型进行训练,预训练和微调都无需增加任务特定的模型层,如BERT在分类任务finetune所使用到的分类层,以降低预训练和微调的discrepancy。在具体实现上,OFA做了一系列针对统一预训练的设计,包括如何实现不同分辨率的图像、文本、检测框等模态信息的输入,如何将不同多模态及单模态任务统一成序列到序列的形式,如下图所示:
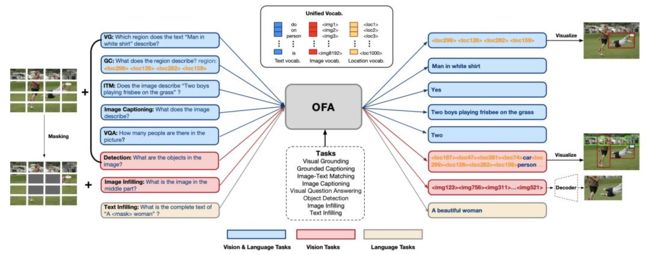
OFA的整体目标是实现三大统一。首先是I/O统一,要解决的问题就是图像和文本在transformer模型中如何输入和输出。输入方面,文本的输入则是传统的BPE encoding将文本输入转化为embedding序列,图像的输入则相对复杂。首先图像需要同样转化成embedding序列的形式,方法的核心则参照ViT的分patch实现。参考了CoAtNet和SimVLM的实现,OFA将图像接入ResNet后转化为patch embedding后再与文本embedding进行拼接,而为了实现更好的效果OFA将ResNet部分加入到模型的训练中。但针对图像的输出,图像依然需要离散化的表达,因此OFA的实现和此前DALL-E、Beit等工作一致,将图像使用vector quantization模型转化成code作为模型的target并将code加入到词表中。此外,由于模型的预训练任务包括grounded captioning,visual grouding以及object detection,OFA还需要处理坐标信息的输入和输出。具体而言,参照Pix2Seq的实现,OFA将连续的坐标信息转化成离散化的表示,并将其加入到词典中,从而将文本、图像、坐标都融入到一个统一的词表中。
任务的统一实现便是建立在上述的I/O统一的基础上,类似Image captioning和VQA等任务本身便是Seq2Seq的形式,无需做额外的改变。而像visual grounding或者object detection这类任务,则需要将输出用序列的形式表达,具体而言每个object的坐标信息都可以表达为
完成上述两个目标,将单模态和多模态的不同任务都统一到同一个Transformer架构便是一个自然而然的事情。但针对效果的优化,OFA还增加了Normformer的方法增强训练稳定性,同时针对分类任务加入了Trie树实现帮助模型在分类任务上能够取得稳定的效果提升且不会输出集合外的标签。

预训练数据集
OFA的研究人员从各种公开数据集中收集了各种模态的数据,包括约2000万多模态数据、3500万无标注图片以及140GB大小的纯文本数据等。OFA所使用的数据集在规模上远小于其它的多模态预训练模型,例如ALIGN(18亿图文Pair)、CLIP(4亿图文Pair)、SimVLM(18亿图文Pair,800G文本)等,但M6-OFA仍然可以在多个下游任务上取得超越这些模型的效果。未来,OFA的研究人员表示将会收集更大规模的预训练数据集以进一步研究数据规模的增加对模型表现的影响。
三、OFA模型规模
近年来,许多关于预训练模型的研究都在提有关scaling law的观点,即随着数据规模和模型规模的增大,模型效果也会随之上升。而在本工作中,OFA的研究人员则重点研究模型规模对效果的影响,并在OFA工作中提出了5个规模的模型,模型参数大小从3.3千万到9.4亿不等,具体参数配置如下表所示:

实验效果也表明,模型规模的增加对于模型效果的提升具有非常显著的影响,其中最大规模的OFA模型也在多项多模态任务中取得了SOTA的表现。
四、OFA实验结果
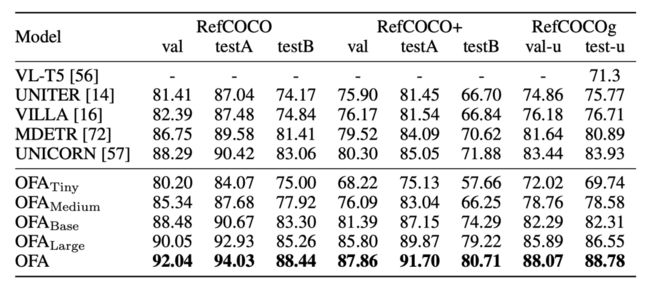
OFA的实验结果还是比较惊艳的,在多项多模态任务都取得了SOTA的表现,尤其考虑到它还是个生成范式的模型。针对多模态理解能力的评估, OFA在视觉问答(VQA)和视觉推理两个任务的经典数据集VQA-v2和SNLI-VE上进行了测评。VQA要求算法根据给定的图片和问题,从3000余个候选答案中选出正确答案,而视觉推理,则要求判断给定的图像和文本之间的关系。在这两个具有挑战性的任务中,OFA均取得了显著优于此前提出的多模态预训练模型的优异表现:

通过OFA提供的视觉问答能力的展示,也可以看出模型能够对图像信息和人类提出的问题进行全面的理解并作答:

多模态生成的一大典型任务为Image Captioning(图像描述),要求算法根据给定的图片,输出相应的描述。在该任务的经典数据集MSCOCO上,OFA在多项评测指标均显著超出此前的模型,并且相比近日推出的预训练数据高出一到两个数量级并且参数规模更大的Deepmind Flamingo和Google Coca,OFA都具有明显的优势,同时OFA还在MSCOCO Image Captioning的官方榜单上位列第一名:

https://competitions.codalab.org/competitions/3221#results
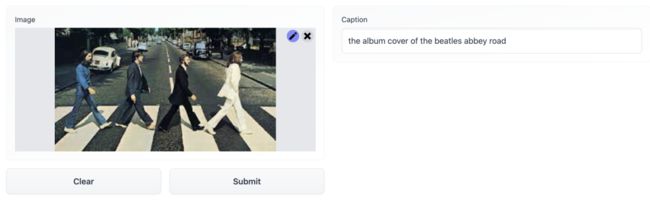
而在图像描述的交互界面中,可以看到模型甚至能够根据图片表达出更多图像以外的信息,比如图中的披头士乐队等,也显示出预训练从大规模数据中学习到的知识所发挥的作用。
在另一跨模态任务物体指代中,模型需要根据用户的指令在图像上找出对应的物体。在此任务上,OFA同样取得了最优表现,并且具有较为明显的优势,其背后的一大原因便是统一的学习模式让模型能够借助其他任务,比如物体检测的能力,去提升自身在该任务的表现。
在应用的交互展示中,可以看到模型不仅能在日常的场景精准识别物体,甚至能够在复杂的交通场景中实现准确识别,也为未来OFA在多个场景的落地展现出无限的可能。

此外,OFA还在基于文本生成图像的任务上进行了评测,这也是首次统一预训练模型应用于该领域的工作。本任务要求算法模型根据给定的文本输入生成对应的图像,在保证语义一致的同时还需要保证图像生成的质量,是一项具有挑战的任务。在MSCOCO的评测中OFA同样取得了优异的表现,超出OpenAI的GLIDE和微软的NUWA等工作:

在实际的生成样例对比中,也可以看到,相比公开的GLIDE和Cogview模型,OFA针对真实的和反事实的query均取得了更好的生成效果:

而在单模态任务上,OFA在GLUE上能够取得匹敌RoBERTa、XLNET、DeBERTa等纯文本领域的SOTA预训练模型的效果,而在生成任务文本摘要的Gigaword上,则超越了ProphetNet等工作,取得了最优表现。而在CV方面,OFA在ImageNet图像分类任务上效果超越MoCo v3、DINO等baseline,并且取得了匹敌BEiT和MAE的表现。目前可以观察到,模态统一的OFA模型在单模态任务上也能取得顶尖水平的表现。

OFA同样针对零样本学习的场景来检验预训练模型模型的能力,并在GLUE和SNLI-VE等任务上进行测试。实验发现,OFA可以取得超出同期的Uni-Perceiver的效果:

同时OFA的研究人员还发现,在未知的任务和未知的领域数据中,统一范式的预训练帮助OFA取得了突出的效果。如下图所示,作者设计了一项名为Grounded QA的新任务,即算法模型需根据输入的图片和给定的物体位置,以及输入的问题,作出正确的回答。OFA模型则根据其对视觉问答以及视觉定位等多项任务的综合理解,实现了对新任务的零样本学习:

而对于预训练没有见过的领域数据,OFA同样能够对这部分数据作出良好的表现,这也显示了该模型的通用性,如下图所示:

OFA模型在面对动画图片以及科幻场景时,尽管在训练集中几乎没有见过此类型图像,但依然能够作出正确的回答。
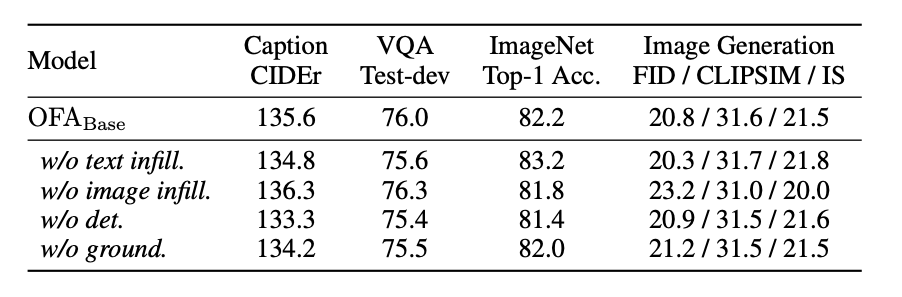
作者针对加入不同任务对于预训练模型的影响,做了一系列消融实验的分析。实验表明,不同的预训练任务整体能为模型效果的提升带来增益,说明多任务学习一定程度上能实现任务效果间的相互促进。但依然存在一些例外,任务间也可能存在冲突。比如针对VQA任务,作者发现去掉图像还原的任务能够带来明显的效果提升,而对图片分类任务,则是去掉纯文本任务带来的增益最大。
现在多任务也逐渐成为一个研究的潮流,OFA的作者认为,任务之间如何分配权重、先后顺序,实现最优的调度达到帕累托平衡也可能是一个重要的研究问题。
五、总结
针对大一统模型的目标,达摩院提出了实现三大统一,即架构统一、模态统一、任务统一的多模态预训练模型OFA,在多项多模态任务上取得了SOTA,并且在单模态任务也取得了优异的表现。同时,还观察到模型能够在没有学习过的任务和领域数据上实现零样本学习,这也展现出大一统模型更大的潜能。
在未来,大量的应用模型可以基于强大的基础模型进行优化,实现更好的效果。基础模型强大的文本生成、图像生成甚至乃至视频生成的能力都将在大量的商业场景中发挥重要作用,包括数字人、AI设计、自动问答对话等。通用统一的基础大模型也会持续发展,将在AI领域扮演基础设施的角色。此外,通用统一模型能够实现任务间的相互协助,未来的AI模型将会根据多任务学习实现融会贯通,类似人类能够通过多任务的学习实现自身能力的全方位提升,并且具备快速学习新任务的能力,让AI不再依赖成本高昂的大规模标注数据。
参考及体验
论文标题:
Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
论文地址:
https://arxiv.org/pdf/2202.03052.pdf
开源地址:
https://github.com/OFA-Sys/OFA
交互式Demo地址:
https://huggingface.co/OFA-Sys