【01李宏毅深度学习笔记2021春季】课程笔记Introduction&Regression(简介和回归)
01-1 Introduction
课程网址:https://speech.ee.ntu.edu.tw/~hylee/ml/2021-spring.html
1. Prerequisite
- Math
- Calculus (微积分)
- Linear algebra (线性代数)
- Probability (概率)
- Programming
- Python
- PyTorch
- Hardware:不需要硬件设备,在Google Colab上运行
2. Assignment
-
multiple-choice questions(多选):submitted via NTU COOL
-
Leaderboard(排行榜):Kaggle or JudgeBoi (our in-house Kaggle )
3. Lecture Schedule
4. Kaggle (JudgeBoi is similar)
- Register a Kaggle account by yourself 注册自己账号
- select two results for evaluating on the private set before the assignment deadline
- limited submission times per day 每天提交有字数限制
01-2 Regression
Machine Learning ≈ Looking for Function
1. Different types of Functions
- Regression: The function outputs a scalar (输出固定值)
- Classification: Given options (classes), the function outputs the correct one (分类)
- Structured Learning: create something with structure (image, document)
2. How to find a function?
研究案例:YouTube Channel (李宏毅老师YouTube频道观看量)
https://www.youtube.com/c/HungyiLeeNTU
2.1 Function with Unknown Parameters
y: 2/26日的观看量,x:2/25日的观看量
w 和 b是将要从数据中学习的未知参数 W:weight b:bias
2.2 Define Loss from Training Data
等高线图:梯度下降的方向与切线方向垂直
证明:人工智能数学基础04之:梯度等高线_智者之家-CSDN博客_机器学习等高线
Loss损失函数:L(b,w),表示这组值有多好
2.3 Optimization
w ∗ , b ∗ = arg min w , b L \begin{array}{l} w^{*}, b^{*}=\arg \min_{w, b} L \end{array} w∗,b∗=argminw,bL
Gradient Descent梯度下降 Local Minima 局部最优 Global Minima 全局最优
-
(Randomly) Pick initial values w 0 , b 0 w^0, b^0 w0,b0 随机初始化
-
Compute计算
-
Update w and b iteratively 交替更新w和b
function with unknown
define loss from training data
optimization
2.4 Sigmoid激活函数
线性模型太简单,不能满足复杂问题的需要,因此我们需要建立更复杂的模型来拟合复杂曲线

为了更好的拟合现实世界中复杂的曲线,就需要很多这样分段碎片(hard sigmoid),将它们和常数叠加就可以拟合出各种各样的线性折线
然而hard sigmoid需要用分段函数来表示,在分段函数处不可导,针对计算机来说处理分段函数也更加麻烦,因此可以使用更加圆滑的sigmoid函数来代替,如下图所示

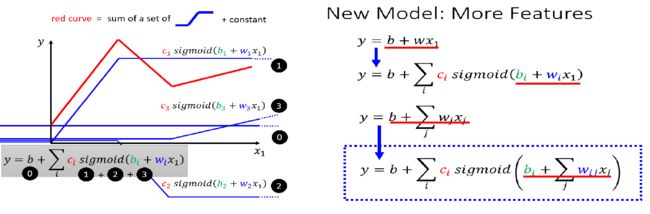
i:no. of sigmoid
j:no. of features
以上是线性模型到非线性模型的过程,接下来介绍非线性模型到神经网络的过程
3.Neural Networks
本部分展示了 y = b + ∑ i c i s i g m o i d ( b i + ∑ j w i j x j ) y = b + \sum_i \:c_i sigmoid(b_i + \sum_j w_{ij}x_j) y=b+∑icisigmoid(bi+∑jwijxj)公式由内到外的形成过程
3.1 b i + ∑ j w i j x j b_i + \sum_j w_{ij}x_j bi+∑jwijxj形成过程
i:1,2,3 no. of sigmoid j:1,2,3 no. of featuresw i j w_{ij} wij: weight for x j x_j xj for i-th sigmoid
将系数抽象成矩阵
3.2 s i g m o i d ( b i + ∑ j w i j x j ) sigmoid(b_i + \sum_j w_{ij}x_j) sigmoid(bi+∑jwijxj)形成过程
3.3 b + ∑ i c i s i g m o i d ( b i + ∑ j w i j x j ) b + \sum_i \:c_i sigmoid(b_i + \sum_j w_{ij}x_j) b+∑icisigmoid(bi+∑jwijxj)形成过程
3.4 神经网络处理过程 Back to ML Framework
3.4.1 Function with unknown parameters
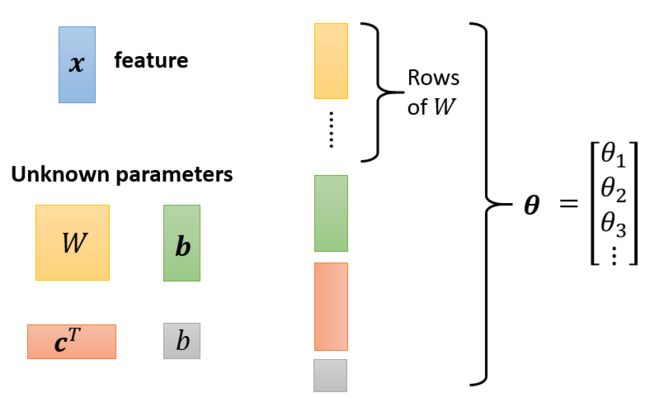 w、b、 c T c_T cT、b组成参数矩阵 θ \theta θ
w、b、 c T c_T cT、b组成参数矩阵 θ \theta θ
3.4.2 Loss
L = 1 / N ∑ n e n L = 1/N \sum_ne_n L=1/Nn∑en
3.4.3 Optimization of New Model
-
θ = ∣ θ 1 θ 2 θ 3 ⋮ ∣ θ ∗ = arg min θ L \theta= \begin{vmatrix} \theta_1\\ \theta_2\\ \theta_3\\ \vdots \end{vmatrix} \enspace\enspace\enspace\enspace \theta^*=\arg \min_\theta L θ=∣∣∣∣∣∣∣∣∣θ1θ2θ3⋮∣∣∣∣∣∣∣∣∣θ∗=argθminL
-
随机初始化 θ 0 \theta^0 θ0
名词 定义 Epoch 使用训练集的全部数据对模型进行一次完整训练,被称之为“一代训练” Batch 使用训练集中的一小部分样本对模型权重进行一次反向传播的参数更新,这一小部分样本被称为“一批数据” Iteration 使用一个Batch数据对模型进行一次参数更新的过程,被称之为“一次训练” 一个例子说明:
N=10000(10000个样本),B=10(Batch size为10)
那么可以得出在一个epoch内更新了1000次参数
4. ReLU
- 两个ReLU合成了一个Hard Sigmoid
系数c可以为复数,有负数时依然使用max而不使用min是为了更好的将公式合起来,更好表示
- Activation function**激活函数** i变成2i是因为两个ReLU才能合成一个sigmoid
-
激活函数模拟人脑内的神经元,因此这种结构被称为神经网络
1.怎么样才能处理更复杂的模型呢?
够多的ReLU和Sigmoid就可以模拟出各种复杂的曲线
现在也会用一层叠一层的方式,向深度发展(具体为什么,接下来的课程会讲),也就是深度学习
【注】过多的层数会造成过拟合
2.课程将讲述的模型真的应用到了youtube频道的流量预测,每一层有100个ReLu