mysql:列类型之json
环境:
- window10
- vs2022
- .net 6
- mysql 8.0.25
- DBeaver
参考:《mysql:11.5 The JSON Data Type》
1. 认识json格式
json全称是: JavaScript Object Notation。它的格式定义在:https://www.json.org/json-zh.html。
在mysql中,我们需要知道json的可选数据格式如下:
- 数组,如:
[]; - 对象,如:
{}; - 标量,如:
string、number、true/false、null;
这几种数据格式在json路径表达式和json函数中都有涉及,其中
标量在某些情况下可被当做是具有一个元素的数组。
其中,需要注意的地方:
- true/false和null均全为小写形式;
- string可以有转移字符(\"、\\、\/、\b、\f、\n、\r、\t、\u0000);
2. json数据在mysql中的存储格式
先看mysql中关于json存储的描述:
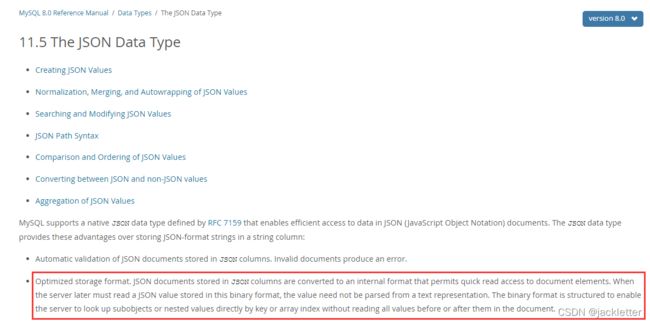
mysql文档中也没有说具体是什么格式,反正是说它并不是简单的以字符串形式存储,而是经过读取优化后的内部格式。
如果它是简单的将其存储为字符串,用起来性能肯定不搞,幸好它不是。
那么,它究竟是以什么格式存储呢,不妨简单认为它是按照下图格式化存储的(我推测的):
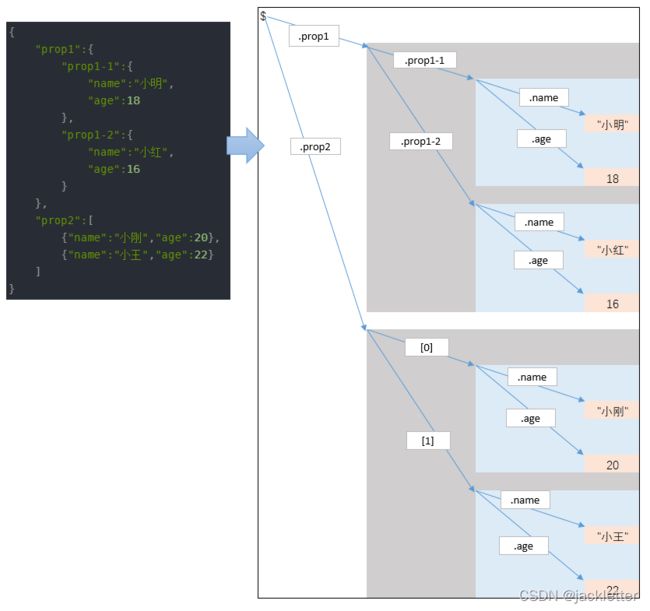
这对我们理解mysql中json路径表达式和json函数很有帮助!!!
3. json数据插入和读取的细节
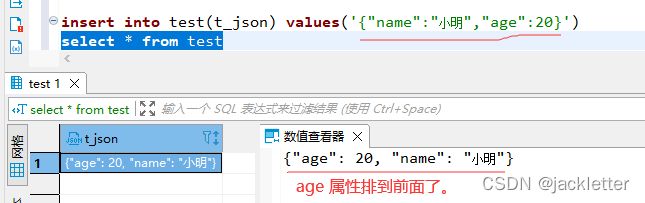
当我们把json字符串插入到mysql时,mysql会自动检查json格式的规范性,并自动将它转为内部优化的格式存储,当读取时,又会从存储的格式中重组成字符串格式。
注意:原json字符串在插入时已被优化处理掉,所以再读取的时候可能和原来的不一样,如下所示:
4. json路径表达式(以json_extract函数为例)
json_extract函数的功能是从json文档中按照指定的json路径表达式去提取值,先看个简单的用法:
select JSON_EXTRACT('{"name":"小明","age":18}','$.name')
// out: "小明"
上面示例的$.name是最简单的jsoon路径表达式。
现在来看json路径表达式的组成部分:
$:表示json文档本身;.:对象成员标识符(当为对象时有效,如果对象的key含有空格等,可以使用""包裹);[]:数组元素标识符(当为数组时有效),扩展表示:[M to N]、last关键字;*:表示对象或数组的所有成员或元素(示例:$.*、$[*]);[prefix]**suffix:表示匹配多级路径,尤其注意:prefix、**、subffix均是完整的路径;另外,prefix可为空,suffix不能为空,即:
$**这种形式是不合法的。
4.1 易迷惑点**
mysql的json路径表达式用到的就上面的这么多,其中有个容易迷惑的地方是**,它是用来匹配多级路径的,不是匹配某个属性名的一部分!
它的正确用法如下:
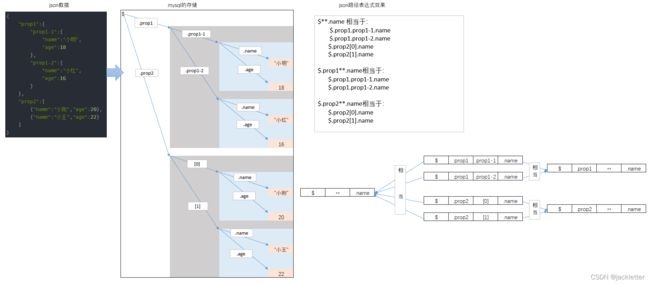
如果我们想取所有的name值,那么可以用表达式:
$**.name,而不要用$.**.name,因为$.不是一个完整的路径。
同理,如果我们想获取prop2数组的所有name值,那么可以用表达式:$.prop2[*].name或$.prop2**.name,而不要用$.prop2.**.name。
另外,json表达式中没有针对key的模糊匹配,所以不要妄想用$.prop1.**-1.name去获取什么东西。
4.2 知识点:数组的匹配
- [*]:匹配数组的所有元素
- [M]:匹配数组的第M+1个元素,从0开始,如:[2],匹配数组的第3个元素;
- [M to N]:匹配数组的第M+1到第N+1个元素,如:[2 to 4],匹配数组的第3到第5个元素;
- [last - M to last - N](M或N为0可以不写):匹配数组的倒数第M个到倒数第N个元素,如:[last - 4 to last - 2],匹配数组倒数第4到倒数第2个元素;
看下面的示例:
select json_extract ('[0,1,2,3,4,5]','$[*]') -- out: [0, 1, 2, 3, 4, 5]
select json_extract ('[0,1,2,3,4,5]','$[2]') -- out: 2
select json_extract ('[0,1,2,3,4,5]','$[2 to 4]') -- out: [2, 3, 4]
select json_extract ('[0,1,2,3,4,5]','$[last -4 to last -2]') -- out: [1, 2, 3]
select json_extract ('[0,1,2,3,4,5]','$[last-2 to last]') -- out: [3, 4, 5]
select json_extract ('[0,1,2,3,4,5]','$[last-2]') -- out: 3
4.3 json路径表达式的指向
我们可以根据json路径表达式简单推断它指向的数据类型,如:$[0 to 1]指向的结果肯定是一个数组,而$.name指向的则有可能是数组、对象或标量(依赖于具体的数据)。
总结规律:凡是包含*、**以及类似$[M to N]形式的返回的肯定是一个范围(即:数组)。至于其他的json路径返回的格式则不确定。
理解这一点很重要,因为部分json函数是只针对单个返回的,所以像
$.*、$**.name、$[M to N]的会直接报错:A path expression is not a path to a cell in an array.。
4.4 特殊情况的处理
-
对于标量数据,mysql仍将它视为有效的json文档
如下所示:select json_valid ('"小明"') -- out: 1 select json_valid ('18') -- out: 1 select json_valid ('null') -- out: 1 select json_valid ('true') -- out: 1 select json_valid ('false')-- out: 1 -
当使用
$[0]格式提取数据,而目标不是一个数组时,返回这个目标本身(文章开头就说了:标量在某些情况下可被当做是具有一个元素的数组); -
当使用
$[1]等格式(角标不是0的)提取数据,而目标不是一个数组时,返回null; -
当使用
$[M]格式提取数组元素时,角标超过数组长度也返回null。如下:
select json_extract ('"小明"','$[0]'),json_extract ('"小明"','$[1]') -- out: "小明",null select json_extract ('18','$[0]'),json_extract ('18','$[1]') -- out: 18,null select json_extract ('null','$[0]'),json_extract ('null','$[1]') -- out: null,null select json_extract ('true','$[0]'),json_extract ('true','$[1]') -- out: true,null select json_extract ('false','$[0]'),json_extract ('false','$[1]') -- out: false,null select json_extract ('{"name":"小明"}','$[0]'),json_extract ('{"name":"小明"}','$[1]') -- out: {"name": "小明"},null select json_extract('{"name":"小明"}','$.name[0]'),json_extract('{"name":"小明"}','$.name[1]') -- out: "小明",null
5. json处理函数
5.1 语法糖->和->>
它们是用来简便sql中提取数据的,是json_extract()和json_unquote(json_extract()) 的简化。
相比
->,->>可以将取出来的标量string的包裹双引号去掉.
如下示例:
create table test(
t_json json
)
insert into test(t_json) values('{"name":"小明","age":20}')
select t_json->"$.name",t_json->>'$.name' from test
/* 输出
t_json->"$.name"|t_json->>'$.name'|
----------------+-----------------+
"小明" |小明 |
*/
-- 用在where条件中
select * from test where t_json->"$.name" like '%小%' -- 输出一行
5.2 json_array() 和 json_object()
这两个函数使用来创建json数组和json对象的,语法为:
json_array (arg1,arg2...)json_object (key1,value1...)
使用如下:
select json_array ('小明','小王','小刚') -- 输出: ["小明", "小王", "小刚"]
select json_object ('name','小明','age',18) -- 输出: {"age": 18, "name": "小明"}
5.3 json_depth、json_keys、json_length、json_type、json_valid、json_quote、json_unquote、json_pretty
这些函数都比较简单,直接看示例:
-- json_depth: json存储的深度,可以参照上面猜测的存储格式,指的是路径的最大数量
select json_depth('{"prop1":{"prop1-1":{"name":"小明","age":18},"prop1-2":{"name":"小红","age":16}},"prop2":[{"name":"小刚","age":20},{"name":"小王","age":22}]}') -- out: 4
-- json_keys 输出对象的属性数组
select json_keys('{"name":"小明","age":20}') -- 输出: ["age", "name"]
select json_keys('[1,2,3]') -- 输出: null
select json_keys('[{"name":"小明"}]','$[0]') -- 输出: ["name"]
select json_keys('[{"name":"小明"},{"name":"小王"}]','$[0 to 1]') -- 报错: 路径表达式返回的不能是数组
-- json_length 输出对象的元素个数(和json_keys处理不同,数组中的个数也是可以计算得)
select json_length('{"name":"小明","age":20}') -- 输出: 2
select json_length('[1,2,3]') -- 输出: 3
select json_length('[{"name":"小明"}]','$[0]') -- 输出: 1
select json_length('[{"name":"小明"},{"name":"小王"}]','$[0 to 1]') -- 报错: 路径表达式返回的不能是数组
-- json_type 输出json类型
select json_type('"小明"') -- out: STRING
select json_type('null') -- out: ARRAY
select json_type('true') -- out: NULL
select json_type('18') -- out: INTEGER
select json_type('18.56') -- out: DOUBLE
select json_type('{}') -- out: OBJECT
select json_type('[]') -- out: ARRAY
-- json_valid 验证是否是真确的json文档
select json_valid('"小明"') -- out: 1
select json_valid('null') -- out: 1
select json_valid('true') -- out: 1
select json_valid('18') -- out: 1
select json_valid('18.56') -- out: 1
select json_valid('{}') -- out: 1
select json_valid('[]') -- out: 1
select json_valid('小明') -- out: 0
select json_valid('True') -- out: 0
select json_valid('NULL') -- out: 0
select json_valid('{"name":"小明"') -- out: 0
-- json_quote 将给定的字符串变为格式正确的json字符串(涉及到转义、添加双引号)
select json_quote('null') -- out: "null"
select json_quote('"null"') -- out: "\"null\""
select json_quote('18') -- out: "18"
select json_quote('true') -- out: "true"
select json_quote('{"name":"小明"}') -- out: "{\"name\":\"小明\"}"
-- json_unquote 和json_quote功能相反
select json_unquote('"null"') -- out: null
select json_unquote('null') -- out: null
select json_unquote('18') -- out: 18
select json_unquote('"18"') -- out: 18
select json_unquote('"小明"') -- out: 小明
select json_unquote('"{\\"name\\":\\"小明\\"}"') -- out: {"name":"小明"}
select json_unquote('"\\u5c0f\\u660e"') -- out: 小明
-- json_pretty: 输出带缩进,易读的文本
select json_pretty('[{"name":"小明"},{"name":"小王"}]')
/* 输出
[
{
"name": "小明"
},
{
"name": "小王"
}
]
*/
5.4 函数json_extract 和 json_value
对于json_extract ,上面示例一直在说这个函数,因为它太常见了,这里补充一点:它不仅可以提取一个json路径,还可以提取多个json路径,如:
select json_extract('{"name":"小明","age":18}','$.name','$.age') -- out: ["小明", 18]
对于json_value这个函数也是提取数据,但它相比json_extract相比更灵活:因为它可以将提取出来的数据转成想要的数据类型,完整语法如下:
JSON_VALUE(json_doc, path [RETURNING type] [on_empty] [on_error])
on_empty:
{NULL | ERROR | DEFAULT value} ON EMPTY
on_error:
{NULL | ERROR | DEFAULT value} ON ERROR
type is one of the following data types:
• FLOAT
• DOUBLE
• DECIMAL
• SIGNED
• UNSIGNED
• DATE
• TIME
• DATETIME
• YEAR (MySQL 8.0.22 and later)
YEAR values of one or two digits are not supported.
• CHAR
• JSON
看示例:
SELECT JSON_VALUE('{"fname": "Joe", "lname": "Palmer"}', '$.fname'); -- out: Joe
SELECT JSON_VALUE('{"item": "shoes", "price": "49.95"}', '$.price' RETURNING DECIMAL(4,2)) AS price; -- out: 49.95
5.5 函数JSON_CONTAINS、JSON_CONTAINS_PATH、JSON_OVERLAPS、JSON_SEARCH、MEMBER OF
这几个函数都是用来做查询判断的。
5.5.1 JSON_CONTAINS
这个是用来判断两个json内容是否被包含的。
语法:JSON_CONTAINS(target, candidate[, path])
简单示例:select json_contains('["小明","小王"]','"小明"') -- out: 1
详细解释:
- json_contains比较的是内容是否被包含,如果指定了path,那么就取target的path部分去比较;
- 标量和标量相比较是它们完全相等才算包含(包扩类型和值);
- 对象和对象相比较是target完全包含candidate中的键值对才算包含;
- 数组与数组比较是target完全包含candidate中的元素才算包含;
如下:
-- 标量与标量间的包含关系
select json_contains ('null','null') -- out:1 标量判断包含: 完全相等
select json_contains ('1','"1"') -- out: 0 标量判断包含: 完全相等,数据类型也要相等
select json_contains ('{"age":20}','20','$.age') -- out: 1 标量判断包含: 完全相等
-- 对象与对象间的包含关系
select json_contains('{"name":"小明","age":20}','{"name":"小明","age":20}') -- out: 1 对象判断包含: 完全包含
select json_contains('{"name":"小明","age":20}','{"name":"小明","addr":"天明路"}') -- out: 0 对象判断包含: 完全包含
select json_contains('{"name":"小明","age":20}','{"age":"20"}') -- out: 0 对象判断包含: 完全包含
select json_contains('{"name":"小明","age":20}','20','$.age') -- out: 1 对象判断包含: 完全包含
select json_contains('{"name":"小明","age":20}','20','$.age2') -- out: null 有null值则返回null
-- 数组与数组间的包含关系
select json_contains('[1,2,3]','[3,2]') -- out: 1 数组判断包含: 完全包含
select json_contains('[1,2,3]','[1,4]') -- out: 0 数组判断包含: 完全包含
select json_contains('[]','[]') -- out: 1 数组判断包含: 完全包含
select json_contains('[1,2,3]','[]') -- out: 1 数组判断包含: 完全包含
select json_contains('[{"name":"小明"},{"age":20}]','[{"age":20}]') -- out: 1 数组判断包含: 完全包含
-- 数组与标量间的包含关系
select json_contains('["小明","小王"]','"小王"') -- out: 1 数组与标量判断包含: 完全包含
5.5.2 JSON_CONTAINS_PATH
这个是用来判断某个json路径是否能从json文档中匹配到数据的。
语法:JSON_CONTAINS_PATH(json_doc, one_or_all, path[, path] …)
简单示例:select json_contains_path('{"a":1,"b":2}','one','$.a') -- out: 1
详细解释:
- 当使用
one模式时,只要有一个path匹配成功就算成功; - 当使用
all模式时,必须所有的path都匹配到值才算成功;
示例如下:
-- 非常规情况
select json_contains_path ('""','one','$') -- out: 1
select json_contains_path ('""','one','$[0]') -- out: 1
select json_contains_path ('{}','one','$[0]') -- out: 1
-- 真的是数组,真的没有第一个元素
select json_contains_path ('[]','one','$[0]') -- out: 0
-- 有一个能匹配到
select json_contains_path('{"a":1,"b":2}','one','$.a') -- out: 1
select json_contains_path('{"a":1,"b":2}','one','$.a','$.c') -- out: 1
select json_contains_path('{"a":1,"b":2}','one','$.c','$.d') -- out: 0
-- 必须都能匹配到
select json_contains_path('{"a":1,"b":2}','all','$.a','$.b') -- out: 1
select json_contains_path('{"a":1,"b":2}','all','$.a','$.c') -- out: 0
select json_contains_path('[1,2,3]','all','$[0]') -- out: 1
select json_contains_path('[1,2,3]','all','$[0]','$[2]') -- out: 1
select json_contains_path('[1,2,3]','all','$[0]','$[2]','$[3]') -- out: 0
5.5.3 JSON_OVERLAPS
比较两个文档是否有交叉。
语法: JSON_OVERLAPS(json_doc1, json_doc2)
简单示例:select json_overlaps('[1,2]','[1]') -- out: 1
详细解释:
- 当两个json文档都是数组时,比较它们有没有完全相同的元素;
- 当两个json文档都是对象时,比较它们有没有完全相同的key-pair对;
- 当两个json文档都是标量时,比较它们是不是完全相等;
- 当非数组和数组比较时,将非数组看做是只有一个元素的数组;
如下示例:
-- 数组间判断相交
select json_overlaps('[1,2]','[1]') -- out: 1
select json_overlaps('[]','[]') -- out: 0
select json_overlaps('[1,2]','[3]') -- out: 0
-- 数组和标量间判断相交
select json_overlaps('[1,2]','1') -- out: 1
select json_overlaps('[1,2]','3') -- out: 0
select json_overlaps('1','[1,2]') -- out: 1
-- 数组和对象间判断相交
select json_overlaps('{"name":"小明"}','[{"name":"小明"},{"name":"小刚"}]') -- out: 1
select json_overlaps('{"name":"小明"}','[{"name":"小王"},{"name":"小刚"}]') -- out: 0
5.5.4 JSON_SEARCH
从json文档中搜索值,返回搜索到的json路径。
语法:JSON_SEARCH(json_doc, one_or_all, search_str[, escape_char[, path] …])
简单示例:select json_search('[{"name":"小明","age":20},{"name":"小王"},{"name":"张三"}]','all','%小%') -- out: ["$[0].name", "$[1].name"]
详细解释:
- 当使用
one模式时,当匹配到第一个就返回; - 当使用
all模式时,当所有的都比对后才返回; - 注意:只搜索字符串,不能搜索其他的数据类型;
- 可以用通配符,就像sql的like一样(
%、_);
看示例:
select json_search('[{"name":"小明","age":20},{"name":"小王"},{"name":"张三"}]','all','小明') -- out: "$[0].name"
select json_search('[{"name":"小明","age":20},{"name":"小王"},{"name":"张三"}]','one','%小%') -- out: "$[0].name"
select json_search('[{"name":"小明","age":20},{"name":"小王"},{"name":"张三"}]','all','%小%') -- out: ["$[0].name", "$[1].name"]
select json_search('[{"name":"小明","age":20}]','one','20') -- out: null 只搜索字符串
select json_search('[{"name":"小明","age":true}]','one','true') -- out: null 只搜索字符串
5.5.5 MEMBER OF
用来判断某个值是否在另一个json数组中。
语法:value MEMBER OF(json_array)
示例:
select 1 member of('[1,2,3]') -- out: 1
select 1 member of('1') -- out: 1
select '1' member of('[1,2,3]') -- out: 0 类型不同也不行
select cast('[2]' as json) member of('[1,[2],3]') -- out: 1 必要是使用cast函数转换类型
select true member of('[1,true]') -- out: 1
select null member of('[1,true,null]') -- out: null, 比较特殊
5.6 函数 JSON_REMOVE
从json文档中删除一部分。
语法:JSON_REMOVE(json_doc, path[, path] …)
简单示例:select json_remove('{"name":"小明","age":18}','$.name') -- out: {"age": 18}
详细解释:
- 根据json的路径表达式从json文档中移除,每个path指向的都不能是一个范围(也就是说:不能有
*、**以及[M to N]这种形式); - 移除时,按照从左向右匹配path的顺序,前一个path执行的结果影响后续的path执行;
示例:
select json_remove('{"name":"小明","age":18}','$.*') -- 报错: In this situation, path expressions may not contain the * and ** tokens or an array range.
select json_remove('{"name":"小明","age":18}','$.name') -- out: {"age": 18}
select json_remove('{"name":"小明","age":18}','$.name','$.age') -- out: {}
select json_remove('[0,1,2,3]','$[0]','$[1]') -- out: [1, 3] 前一个path执行的结果影响到后续的path执行
5.7 函数 JSON_ARRAY_APPEND、JSON_ARRAY_INSERT、JSON_INSERT
这几个函数都是插入数据到json数组或对象的。
5.7.1 JSON_ARRAY_APPEND
追加数据到数组的结尾。
语法:JSON_ARRAY_APPEND(json_doc, path, val[, path, val] …)
简单示例:select json_array_append('[1,2]','$',3) -- out: [1, 2, 3]
详细解释:
- path不能指向一个范围,即:
*、**以及[M to N]都是不被允许的; - 当path匹配到的数据不是数组时,mysql将它看成是只有一个元素的数组;
示例:
select json_array_append('[1,2]','$',3) -- out: [1, 2, 3]
select json_array_append('{"name":"小明"}','$',3) -- out: [{"name": "小明"}, 3] 当path指向的不是数组时,将它看做只有一个元素的数组
select json_array_append('{"name":"小明"}','$.name',3) -- out: [1, 2, 3] 当path指向的不是数组时,将它看做只有一个元素的数组
select json_array_append('[1,[]]','$[1]',2,'$[1]',3) -- out: [1, [2, 3]]
select json_array_append('{"arr1":[],"arr2":[]}','$.arr1',true) -- out: {"arr1": [true], "arr2": []}
select json_array_append('{"arr1":[],"arr2":[]}','$.*',true) -- 报错: In this situation, path expressions may not contain the * and ** tokens or an array range.
select json_array_append('[[],[]]','$[0 to 1]',true) -- 报错: In this situation, path expressions may not contain the * and ** tokens or an array range.
5.7.2 JSON_ARRAY_INSERT
向json数组中的某个位置插入数据。
语法:JSON_ARRAY_INSERT(json_doc, path, val[, path, val] …)
简单示例:select json_array_insert('[1,2,3]','$[1]','5') -- out: [1, "5", 2, 3]
详细解释:
- path不能指向一个范围;
- path最终匹配到的数据应该是数组中的一员,如果不是则报错(此时并没有将它看做是只有一个元素的数组);
- 当path指向的数据在数组中索引超出时,自动认为匹配到数组最后一个;
- 执行插入时,从左向右执行path,并且前一个执行结果影响后续;
示例:
select json_array_insert('[1,2,3]','$[1]','5') -- out: [1, "5", 2, 3]
select json_array_insert('[0,2]','$[100]','1') -- out: [0, 2, "1"] 当path指向的数据在数组中索引超出时,自动认为匹配到数组最后一个;
select json_array_insert('"小明"','$','1') -- 报错: 不会将它转成只有一个元素的数组 A path expression is not a path to a cell in an array.
select json_array_insert('[]','$','1') -- 报错: 不会将它转成只有一个元素的数组 A path expression is not a path to a cell in an array.
select json_array_insert('{"name":"小明"}','$.name','1') -- 报错: 不会将它转成只有一个元素的数组 A path expression is not a path to a cell in an arra
select json_array_insert('[0,1,2]','$[0]',-1,'$[1]',-2) -- out: [-1, -2, 0, 1, 2] 前一个path的执行结果影响后续path
5.7.3 JSON_INSERT
将某个数据插入到json对象中。
语法:JSON_INSERT(json_doc, path, val[, path, val] …)
简答示例:select json_insert('{"name":"小明"}','$.age',20) -- out: {"age": 20, "name": "小明"}
详细解释:
- 目的是向json对象中插入属性,如果指定的属性已存在就忽略此次插入;
- path指向不能是一个范围;
- path执行顺序从左到右,前者执行结果影响后者;
- path指向一个数组中不存在的角标元素,则在数组最后插入(注: 这种情况不应该用json_insert);
- path指向一个不存在的位置上一级应该存在,如果上一级还是不存在,那么就忽略插入;
示例:
select json_insert('{"name":"小明"}','$.age',20) -- out: {"age": 20, "name": "小明"}
select json_insert('{"name":"小明"}','$.name','小王') -- out: {"name": "小明"} 已经存在 忽略
select json_insert('{}','$.detail.addr','天明路') -- out: 没有匹配到
select json_insert('{}','$.detail',cast('{}' as json),'$.detail.addr','天明路') -- out: {"detail": {"addr": "天明路"}} 相比上面的,虽然都没有匹配到,但没有匹配到的层级不同
select json_insert('[0,1]','$[3]','3') -- out: [0, 1, "3"] 指向数组不存在的位置 在最后插入 (注: 这种情况不应该用json_insert)
select json_insert('[0,1]','$[1]','3') -- out: [0, 1] 指向数组存在的位置 忽略(注: 这种情况不应该用json_insert)
5.8 JSON_REPLACE、JSON_SET
它们都是用来改json数据的,其实应该和json_insert对比:
- json_insert 相当于是 sql中的insert;
- json_replace 相当于是 sql中的update;
- json_set 相当于是 sql中的updateorinsert(虽然sql中并没有updateorinsert);
5.8.1 JSON_REPLACE
替换json文档中的数据。
语法:JSON_REPLACE(json_doc, path, val[, path, val] …)
简单示例:select json_replace('{"name":"小明","age":20}','$.age',18) -- out: {"age": 18, "name": "小明"}
详细解释:
- path不应该指向范围,否则报错;
- path从左向右执行,前者执行结果影响后者;
- 如果path指向的数据存在,则替换,否则忽略;
示例:
select json_replace('{"name":"小明"}','$.name','小王') -- out: {"name": "小王"}
select json_replace('{"name":"小明"}','$.age',20) -- out: {"name": "小明"} 指向数据不存在,忽略
select json_replace('{"name":"小明"}','$.*',20) -- 指向范围,报错: In this situation, path expressions may not contain the * and ** tokens or an array range.
select json_replace('{"name":"小明","age":20}','$.name','小王','$.age',18,'$.age',16) -- out: {"age": 16, "name": "小王"}
5.8.2 JSON_SET
向json文档中插入或更细数据。
语法:JSON_SET(json_doc, path, val[, path, val] …)
简单示例:select json_set('{"name":"小明"}','$.age',20,'$.name','小王') -- out: {"age": 20, "name": "小王"}
详细解释:
- path不应该指向范围,否则报错;
- path从左向右执行,前者执行结果影响后者;
- path指向一个数组中不存在的角标元素,则在数组最后插入(注: 这种情况不应该用json_insert);
- path指向一个不存在的位置上一级应该存在,如果上一级还是不存在,那么就忽略插入;
示例:
select json_set('{"name":"小明"}','$.name','小王','$.name','小刚') -- out: {"name": "小刚"}
select json_set('{"students":[1]}','$.students[2]',2,'$.students[3]',3) -- out: {"students": [1, 2, 3]}
select json_set('{"name":"小明"}','$.students[0].name','小王','$.name','小刚') -- out: {"name": "小刚"} 第一个path的set被忽略
select json_set('{"name":"小明"}','$.*',20) -- 报错: In this situation, path expressions may not contain the * and ** tokens or an array range.
5.9 函数JSON_MERGE、JSON_MERGE_PATCH、JSON_MERGE_PRESERVE
这三个函数都是用来合并json文档的,但它们的细节处理不一样。另外,JSON_MERGE不被推荐使用了,使用JSON_MERGE_PRESERVE替代。
5.9.1 JSON_MERGE_PRESERVE
合并多个json文档,当冲突时,保留它们的值。
语法:JSON_MERGE_PRESERVE(json_doc, json_doc[, json_doc] …)
简单示例:select json_merge_preserve('{"name":"小明"}','{"name":"小刚","score":20}') -- out: {"name": ["小明", "小刚"], "score": 20}
详细解释:
- 标量之间的merge会生成一个数组,然后让数据放进去;
- 数组之间的merge会合并生成一个新的数组;
- 数组与非数组之间的merge会将非数组放到数组中去;
- 两个对象之间合并会将它们的属性合并生成新的对象(共同的属性生成数组);
示例:
-- 标量之间
select json_merge_preserve('"小明"','"小王"','"小刚"') -- out: ["小明", "小王", "小刚"]
-- 标量与数组
select json_merge_preserve('"小明"','[20]') -- out: ["小明", 20]
-- 标量与对象
select json_merge_preserve('"小明"','{"name":"小王"}') -- out: ["小明", {"name": "小王"}]
-- 数组与数组
select json_merge_preserve('[1,2,3]','[3,4]') -- out: [1, 2, 3, 3, 4]
-- 数组与对象
select json_merge_preserve('[1,2]','{"name":"小明"}') -- out: [1, 2, {"name": "小明"}]
-- 多个数组
select json_merge_preserve('[1,2]','[3]','[4]') -- out: [1, 2, 3, 4]
-- 对象与对象
select json_merge_preserve('{"name":"小明","age":20}','{"name":"小刚","age":20,"students":[{"name":"小王"}]}','{"students":[{"name":"小王"}]}') -- out: {"age": [20, 20], "name": ["小明", "小刚"], "students": [{"name": "小王"}, {"name": "小王"}]}
5.9.2 JSON_MERGE_PATCH
合并读个json文档,当属性或元素冲突时,使用第一个出现的。
语法:JSON_MERGE_PATCH(json_doc, json_doc[, json_doc] …)
简单示例:select json_merge_patch('{"name":"小明"}','{"name":"小刚","age":20}') -- out: {"age": 20, "name": "小刚"}
详细解释:
- 第一个json文档不是对象时,将把第一个文档当成{}被覆盖;
- 第二个json文档不是对象时,合并的结果就是第二个对象
- 当都是对象时,采用后者属性覆盖前者的规则(排除value为null的);
示例:
-- 第一个json文档不是对象时,将把第一个文档当成{}被覆盖
-- 第二个json文档不是对象时,合并的结果就是第二个对象
select json_merge_patch('"小明"','"小红"') -- out: "小红"
select json_merge_patch('{}','"小红"') -- out: "小红"
select json_merge_patch('"小明"','null') -- out: null
select json_merge_patch('{}','null') -- out: null
select json_merge_patch('"小明"','{"age":20}') -- out: {"age": 20}
select json_merge_patch('{}','{"age":20}') -- out: {"age": 20}
select json_merge_patch('"小明"','[1,2]') -- out: [1, 2]
select json_merge_patch('{}','[1,2]') -- out: [1, 2]
select json_merge_patch('{"name":"小明"}','[1,2]') -- out: [1, 2]
select json_merge_patch('{"name":"小明"}','1') -- out: 1
-- 当都是对象时
select json_merge_patch('{"name":"小明","age":20}','{"name":"小刚","age":null,"score":98.5}') -- out: {"name": "小刚", "score": 98.5}
5.10 函数JSON_TABLE
将json文档转为table。
语法:
JSON_TABLE(
expr,
path COLUMNS (column_list)
) [AS] alias
column_list:
column[, column][, ...]
column:
name FOR ORDINALITY
| name type PATH string path [on_empty] [on_error]
| name type EXISTS PATH string path
| NESTED [PATH] path COLUMNS (column_list)
on_empty:
{NULL | DEFAULT json_string | ERROR} ON EMPTY
on_error:
{NULL | DEFAULT json_string | ERROR} ON ERROR
示例:
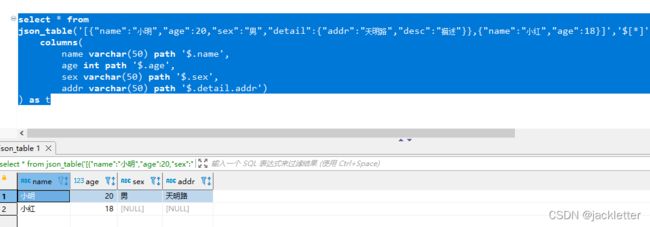
select * from
json_table('[{"name":"小明","age":20,"sex":"男","detail":{"addr":"天明路","desc":"描述"}},{"name":"小红","age":18}]','$[*]'
columns(
name varchar(50) path '$.name',
age int path '$.age',
sex varchar(50) path '$.sex',
addr varchar(50) path '$.detail.addr')
) as t
输出:
5.11 其他函数JSON_SCHEMA_VALID、JSON_SCHEMA_VALIDATION_REPORT、JSON_STORAGE_FREE、JSON_STORAGE_SIZE
5.11.1 JSON_SCHEMA_VALID
校验json是否符合某个规则。
示例:
SET @schema = '
{
"id": "http://json-schema.org/geo",
"$schema": "http://json-schema.org/draft-04/schema#",
"description": "A geographical coordinate",
"type": "object",
"properties": {
"latitude": {
"type": "number",
"minimum": -90,
"maximum": 90
},
"longitude": {
"type": "number",
"minimum": -180,
"maximum": 180
}
},
"required": ["latitude", "longitude"]
}';
SET @document = '{
"latitude": 63.444697,
"longitude": 10.445118
}';
SELECT JSON_SCHEMA_VALID(@schema, @document); -- out: 1
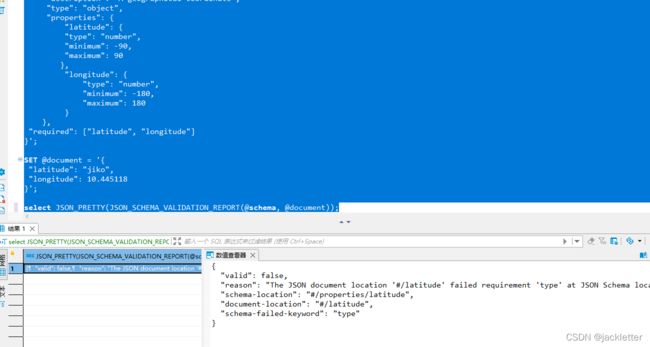
5.11.2 JSON_SCHEMA_VALIDATION_REPORT
相比JSON_SCHEMA_VALID 输出详细的结果报告,示例:
SET @schema = '
{
"id": "http://json-schema.org/geo",
"$schema": "http://json-schema.org/draft-04/schema#",
"description": "A geographical coordinate",
"type": "object",
"properties": {
"latitude": {
"type": "number",
"minimum": -90,
"maximum": 90
},
"longitude": {
"type": "number",
"minimum": -180,
"maximum": 180
}
},
"required": ["latitude", "longitude"]
}';
SET @document = '{
"latitude": "jiko",
"longitude": 10.445118
}';
select JSON_PRETTY(JSON_SCHEMA_VALIDATION_REPORT(@schema, @document));
输出:
5.11.3 JSON_STORAGE_FREE
查询通过JSON_SET(), JSON_REPLACE(), orJSON_REMOVE().函数后,释放了多少空间。
示例:
create table test(
t_json json
)
insert into test(t_json) values('{"name":"abcd"}')
update test set t_json=json_set(test.t_json,'$.name','ab')
select json_storage_free(t_json) from test -- out: 2 释放了2个字节
update test set t_json=json_set(test.t_json,'$.name','abcde')
select json_storage_free(t_json) from test -- out: 0 并没有释放空间
5.11.4 JSON_STORAGE_SIZE
查询存json数据占用的空间。
示例:
select json_storage_size('"abc"') -- out: 5
select json_storage_size('{"name":"abc"}') -- out: 20
以上就是所有的json处理函数。。。
6. json结合虚列、索引
为了方便扩展,我们在表里定义json列,为了方便查询,我们可以定义虚列,为了加快搜索速度,我们可以在虚列上加索引。
看下面的示例:
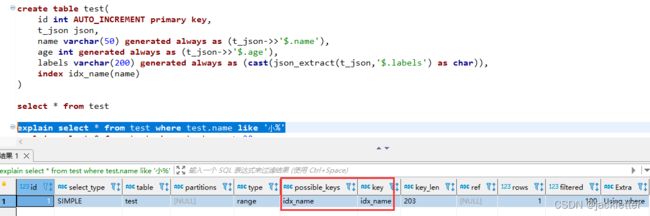
create table test(
id int AUTO_INCREMENT primary key,
t_json json,
name varchar(50) generated always as (t_json->>'$.name'),
age int generated always as (t_json->>'$.age'),
labels varchar(200) generated always as (cast(json_extract(t_json,'$.labels') as char)),
index idx_name(name) -- 创建索引
)
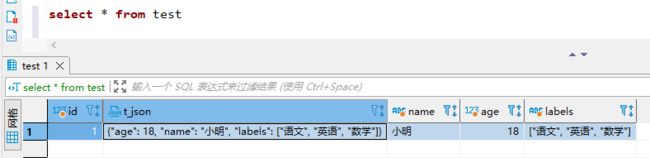
-- 插入测试数据
insert into test(t_json) values('{"name":"小明","age":18,"labels":["语文","英语","数学"]}');
-- 简单查询
select * from test
-- 观察查询索引使用情况
explain select * from test where test.name like '小%'
输出:
Multi-Valued Indexes:mysql 8.0.17后支持一种多值的索引,转为json列设计,使用它可以方便的从json中检索数据,先看个示例:
create table test(
id int AUTO_INCREMENT primary key,
t_json json,
name varchar(50) generated always as (t_json->>'$.name'),
index idx_name(name),
index idx_labels((cast((t_json->'$.labels') as unsigned array)))
)
insert into test(t_json) values('{"name":"小明","age":18,"labels":[1,2,3]}');
explain select * from test where 1 member of (t_json->'$.labels')
输出:

从输出上看,这个查询走索引,效率肯定高,但它不支持char:
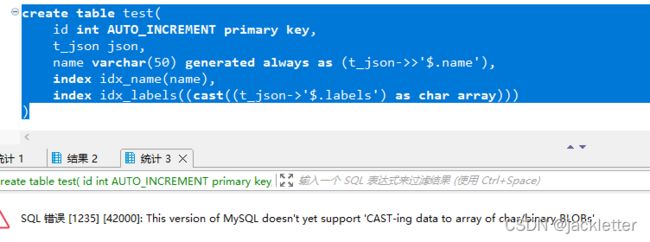
7. c#中如何使用
使用mysql驱动读取出来的json是个字符串,用json接受即可,如下:
/*
create table test(
id int AUTO_INCREMENT primary key,
t_json json,
name varchar(50) generated always as (t_json->>'$.name'),
index idx_name(name)
)
*/
public class Test
{
public int id { get; set; }
public string t_json { get; set; }
public string name { get; set; }
}