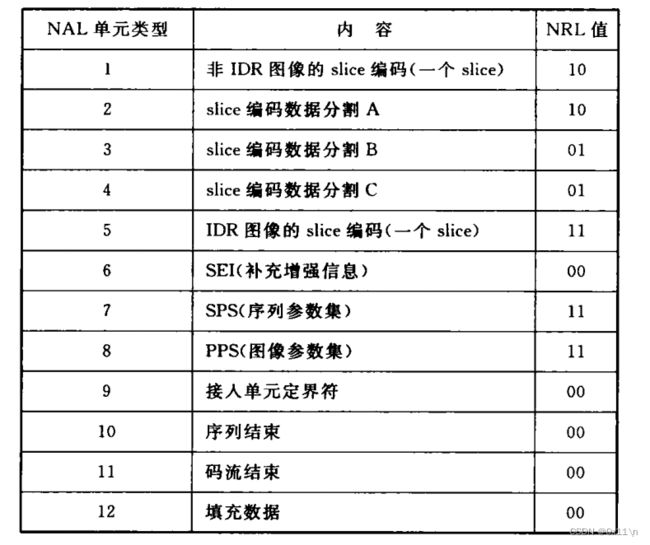
h264编码算法流程
xh264编解码:

编码层:视频压缩解压缩等核心算法,VLC就是这一系列算法,得到的是编码后的比特序列,即VLC数据。
网络抽象层:将压缩后的原始码流拼接头信息用于解码时来识别,安排格式以方便后续的网络传输或者介质存储。将上一步VLC数据映射成NAL单元。
传输层:用于传输。
h264-VLC层图像编码结构:
因为VLC层是核显的编解码得到编码后的比特序列,为了适应不同传输网络的最大传输单元长度则进行了条带划分。通常的做法是一个 NALU包含一个 slice。

h264-帧(Frame )、场 (Field)、 行(Lines)
一个视频序列是由N个帧组成的,采集图像的时候一般有2种扫描方式,一种是逐行扫描(progressive scanning),一种是隔行扫描(interlaced scanning)。对于隔行扫描,每一帧一般有2个场(field),一个叫顶场(top field),一个叫底场(bottom field)。假设一帧图像是720行,对于顶场,有效数据行就是一帧图像的所有偶数行,而底场,有效数据行就是一帧图像的所有奇数行。
场 = 垂直消隐顶场(First Vertical Blanking) + 有效数据行(Active Video) + 垂直消隐底场(Second Vertical Blanking)
行 = 结束码(EAV) + 水平消隐(Horizontal Vertical Blanking) + 起始码(SAV) + 有效数据(Active Video)

h264-什么是NAL
NAL全称Network Abstract Layer,即网络抽象层。在H.264/AVC视频编码标准中,整个系统框架被分为了两个层面:视频编码层面(VCL)和网络抽象层面(NAL)。其中,前者负责有效表示视频数据的内容,而后者则负责格式化数据并提供头信息,以保证数据适合各种信道和存储介质上的传播。VCL(Video Coding Layer)是H.264/AVC的规格,意思是压缩后、去冗余(Visual Redundancy)的影像资料,其技术核心包括动作估计、转换编码、预测编码、去区块效应滤波、及熵编码等。
h264-什么是NAL单元
原始的h264码流就是一个一个NAL单元的连续流。NAL单元的结构由两部分组成。包含头信息,一个字节,以及原始字节序列负载RBSP(SODB)。

而NAL头信息占用一个字节,包含三个字段,F禁止位、R重要性指示位、T类型标志。其中禁止位表示当前NAL单元是否发生比特错误,重要性指示位用于表示重要性比如当前NAL单位未用作预测也就是说解码端丢失也不会造成太大影响,在传输阶段需要对重要程度越高的NAL单元予以保护。

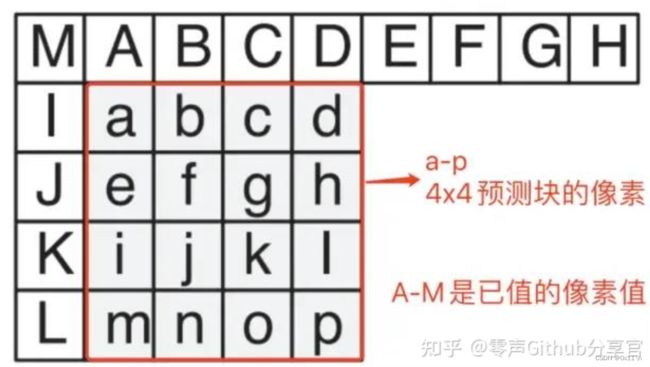
h264-帧内预测,4*4块亮度预测:
A~P为周围已知像素点的值,a~p为待预测的像素点位置。需要通过周围A~P的像素值来预测 a~p 共16个点的像素值。
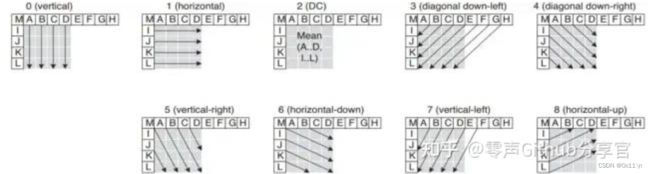
Mode0 (Vertical): 由上方的A、B、C、D进行垂直推算
Mode1 (Horizontal) : 由左侧的I、J、K、L进行水平推算
Mode2 (DC) : P中的所有样本预测值都等于AD及IL的平均值
Mode3 (Diagonal Down-Left): 由45度角方向的左下和右上的样本内插得出
Mode4 (Diagonal Down-Right): 以45度角往右下的方向进行推算
Mode5 (Vertical-Right) : 以垂直向下方向右偏大约26.6度角(即width/height = 1/2)的方向推行推算。
Mode6 (Horizontal-Down): 以水平向右方向下偏大约26.6度角的方向进行推算。
Mode7 (Vertical-Left): 以垂直向下方向左偏大约26.6度角的方向推行推算。
Mode8 (Horizontal-Up): 以水平向右方向上偏大约26.6度角的方向进行推算。
h264-帧内预测,16*16块亮度预测:
同理,用周围的点来预测16*16个像素点。一共包含四种模式。
Mode0 (vertical): 由上方的样本(H)垂直推算
Mode1 (horizontal) 由左侧的样本(V)水平推算
Mode2 (DC): 上方的样本(H)和左侧的样本(V)的平均值
Mode3 (Plane): 根据上方的样本(H)和左边的样本(V)通过一个plane函数得出,在亮度平滑变化的区域工作得很好。
h264-帧内预测,8*8块色度预测:
注意上面都是亮度预测,8*8用于色度预测,色度的Cr和Cb分量的预测模式选择是一样的。色度预测模式与16x16亮度预测模式的描述类似,除了模式的编号不一样。DC (mode 0), horizontal (mode 1), vertical (mode 2), plane (mode 3).
h264-帧内预测模式的选择:
色度最佳预测模式选择,仅比较4种模式的代价,取代价最小。
亮度最佳预测模式选择,先比较4*4(9中)的代价,再比较16*16(4中)的代价。最终取最小代价者。
注意亮度4*4代价函数是RDO模型,亮度16*16是SATD模型。而色度8*8代价函数同亮度4*4相似。
h264-帧内预测的编码:
通常I帧会进行大量的帧内预测,对于帧内4*4亮度块预测,使用无符号指数哥伦布编码直接将预测方式编号编入码流。比如使用mode0,只需要记录周围像素点以及待预测点的编码mode编号,就能够用最多13个像素来表示 13+4*4个像素点得亮度取值。
h264-帧间预测,亮度亚像素插值:
1/2像素点使用(1,-5,20,20,-5,1)的六抽头滤波器插值然后四色五入。
1/4像素点是计算临近像素的平均值。

h264-帧间预测,色度亚像素插值:
色度运动估计需要支持1/8像素经度,使用的是二次线性法。
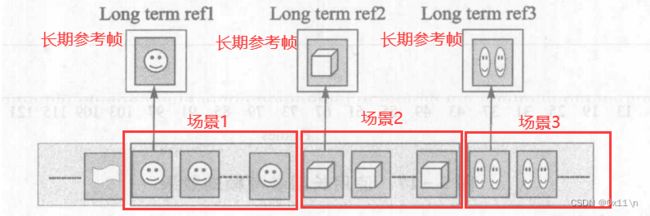
h264-长期参考帧:
编码器会缓存最多16个参考帧,视频因为场景的切换那么前面缓存的短期参考帧就都没有用了。那么预测的时候必须向前查找当前场景的一个长期参考帧来进行预测。因为场景的切换,参考上一个短期参考帧进行运动估计已经没有意义了因为属于上一个场景的。这里指的场景切换是指场景1切换到场景2,而后后切换回场景1,视频里面的场景大部分是来回切换小部分是一直切换新场景,那么在编码器检测到场景切换后就会检测当前缓存是否有当前场景比较相近的长期参考帧,找出来用它作为运动估计的参考。结果测试,如果不使用长期参考帧,在发生场景切换后仅使用帧内预测而不使用运动估计的话,在场景切换瞬时会造成视频客观质量下降且码率骤升。而使用长期参考帧作为运动补偿,客观质量高出0.5db左右。
h264-运动矢量的编码优化:
一般结果运动估计后需要编码的有两部分数据,一是残差、二是运动矢量。以4*4的宏快划分为例,一个宏快包含16个像素点,就有16个像素的运动矢量需要保存,运动矢量包含两个变量分别为方向和距离(也可以是横纵坐标),那么编码运动矢量码率可能比残差还高。所以实际编码中运动矢量还会进行二次估计,也就是相邻两个宏快的运动矢量也有相关性。比如宏快A运动矢量为MVa,宏快B的运动矢量为MVb,通过MVa-MVb得到运动矢量的残差MV,也就是只需要编码宏快A的运动矢量MVa以及对应宏快B的运动矢量残差就能够用MVa还原出MVb。
h264-运动矢量预测的规则:
因为运动矢量也可以预测,那么就需要找出以哪个宏快的运动矢量作为参照来进行目标宏快运动矢量的预测,实际上想要预测当前宏快的运动矢量,那么可以以当前宏快上下左右几个方向来选择参照宏快,具体选择规则如下:

如果E不是16*8或者8*16,那么E的运动矢量以ABC三个宏快的运动矢量的中值(非平均值)作为预测值。
如果E是16*8,上面8*8部分宏快由B的MV进行预测,下面部分由A的MV进行预测。
如果E是8*16,左边8*8部分宏快由A的MV进行预测,右边部分由C的MV进行预测。
同时需要根据ABCD的可用性决心调整。
h264-SKIP编码模式:
SKIP模式指的是宏快编码时,有的宏快可以标记为SKIP。SKIP有两种取值。
p_SKIP:没有运动矢量的残差、也没有量化残差。解码时直接以参考的运动矢量预测值进行还原像素点预测值。
b_SKIP:没有运动矢量的残差、也没有量化残差。解码时直接以Direct模式计算前后向MV得到像素点预测值。
h264的IBP帧预测编码顺序:
按照播放顺序截取一段视频存储,存储从左往右,越靠右则越先播放,越靠左则越后播放。实际的编码顺序是倒过来进行编码的,也就是用后播放的帧选做I帧来预测越先播放的帧P,然后将IP之间的帧编码为B。过程连续进行,通常每12到15个PB内插入一个新的I帧。另外视频内容变化不大时会自动加大I帧的间隔。因为B帧会带来编码延时通常实际应用中不会对B帧进行编码。

h264-亮度检测与加权预测:
基于帧间预测编码思想是检测宏快的移动,基于亮度进行移动检测,前提是亮度不做改变。也就是需要假设视频亮度不发生变化。而在视频应用中亮度因为镜头光圈整体或者局部光源肯定会造成亮度改变。解决的办法就是首先检测亮度的变化,h264选择两幅图像亮度直方图(计算简单且对图像内容变化敏感度低)来检测亮度的变化,计算两幅图像的直方图在各个灰度级的差别的绝对和然后阈值判断是否发生亮度跳变。然后根据前后两个图像亮度的变化在预测时进行一定的亮度加权,利用加权先将待预测的宏快像素点的亮度提升(补偿)到参考宏快像素点亮度同一级别,然后再进行运动估计。
简单的方法就是计算参考帧和预测帧的亮度比值,然后将待预测帧的宏块乘比值来进行补偿,不过忽略了宏快局部变化效果一般。通常在实际运用是加权系数不通过简单的帧亮度比值来衡量,而是用一个标准去计算最佳亮度比值。另外亮度补偿也根据情况对每一个宏快都进行亮度补偿(整体淡入淡出),或者仅对一部分宏块进行亮度补偿(每个宏快都去判断是否需要补偿,计算量大实际不采用这种方式)。
h264中整数DCT的4*4公式:

h264中的量化器:
需要对残差系数、矢量和标量等一系列数字做量化以方便后续的熵编码,h264在量化器上有一些特别的设计,研究表明残差的系数取值服从 Lapla-cain 分布。帧间比帧内分布更加几种。量化公式为,以及量化级别表。另外为了支持高清视频,h264还引入了非一致性量化,意思是不同位置的变幻系数和量化步长不一样。
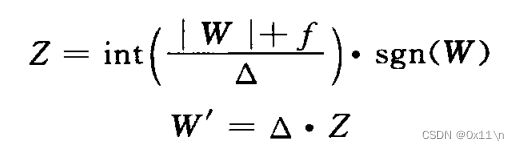


h264的4*4整数DCT变换、量化过程:

h264的8*8整数DCT变换、量化过程:

h264的游程编码:
在结果变换和量化之后,需要进行游程编码,由于标准支持了 4*4、8*8等变换,以及对一些预测方式的直流分量进行了哈达玛变换,一共有13种块类型,不同的快类型游程编码的扫描系数不同。

h264的熵编码:
一共有两种针对残差量化后的的熵编码。CAVLC、CABAC。
CAVLC:基于上下文自适应的可变长编码,用于色度、亮度的残差数据编码。
CABAC:基于CAVLC优化升级。
h264去块效应滤波器:
块效应是因为以宏块为单位进行编码会发现块的连接处不连续,比如对整个图像做DCT变换就没有块效应,但是对单独的宏块DCT因为祛除了宏块内部高频信息,宏块之间的相关性被忽略了。且宏块DCT后量化时会将DCT系数处理不同的量化步长后取整,放大了斑块效应。DCT系数高频量化为0了,造成强边缘在跨边界处出现锯齿状,以及格形噪声。有两种方式来减少这个效应。
后置滤波:在解码端对显示缓冲区的数据做处理,因为是在解码完毕和显示之前的操作,在标准中是可选项。
环路滤波:在解码时进行滤波,要求编码时也使用配套的滤波器使得解码能够正确重建图形。
h264-SP和SI帧的引入:
传统IBP的GOP结构中,只有I帧可以作为流间切换点 (用于快速预览、随机定位、视频插入广告等需要快速切换到一个片段),随机切换的话有可能没有I帧。为了支持流切换点,引入了SI和SP帧。
SP帧:分为主SP和辅SP两种,基于帧间的运动补偿预测进行编码,使用不同的参考帧情况下重建相同的图像。
SI帧:同样,作用是提供代替帧或者切换点。

h264码率控制:
码率控制时在给定一个码率下,要求优化各种编码信息(帧率、图像尺寸、量化参数、计算量)等,在保持给定码率的条件下使得视频编码质量失真越小。有多重方法可以控制码率。
(1)基于缓存状态的码率控制:给缓存一个门限,当缓存超过门限是编码端通过增加量化参数或者丢帧来降低码率。
(2)具有前反馈输入的码率控制:除了利用缓存门限之外,还考虑输入编码数据的自身信息,在初始化后编码前进行目标比特计算、编码前后的量化参数计算。
(3)基于率失真的码率控制:转换为带约束条件的优化模型问题得到最优的编码参数。经典的是h263+中的TMN8算法。
(4)多层编码的码率控制:编码时得到多个层级的码流,包含一个基础码流和一些增强码流。前者用于确保图像重建,后者用于优化质量。
(5)精细力度可分级的码率控制:略。
码率失真优化:
基于各种各样的算法,提供了一系列编码工具(帧内编码、帧间编码、宏块大小等)。编码工具相互组合复用对同一个视频的编码结果大不相同,失真程度不同。优化策略模式的组合叫做率失真优化。策略模式的选择如下:
(1)宏块划分选择,16*16、16*8、8*16、8*8等
(2)宏块使用帧内还是帧间
(3)帧内编码应该使用哪种预测模式,亮度宏块选择16*16或者4*4
(4)P帧宏快是否采用skip、B帧宏快是否采用直接预测模式
(5)量化步长的选择
策略组合的效果会表现成R-D曲线,表现了编码的极限压缩能力。
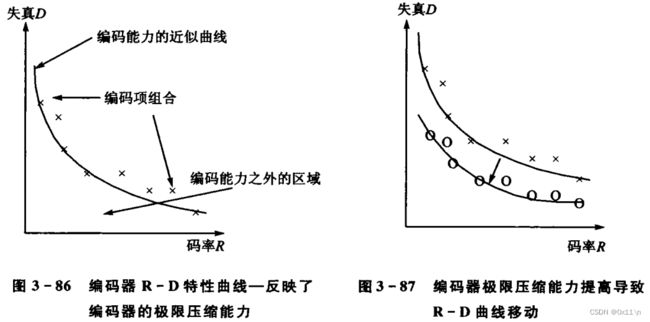
拉格朗日乘法与编码模式的选择:
对于数学优化问题,拉格朗日乘法是一种寻找变量受一个或多个条件限值的多元函数的求极值的方法。
