关于rknn-toolkit的yolov5的例子
简而言之今天调了一天那玩意得出了心得:
1、github的commit版本
2、如何从识别图片变成实时摄像头检测
3、如何使用自训练模型和官方的test.py进行目标检测。
____________________________________
刚好没租到GPU,现在来总结一下。
一、github的commit版本
在rknn-toolkit中有所用yolov5的commit号:c5360f6e7009eb4d05f14d1cc9dae0963e949213

进入该commit版本最好的方式是:
原本yolov5的官方网站是:
ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite (github.com) https://github.com/ultralytics/yolov5现在要进某次commit就是在原本网站加上/commit/c5360f6e7009eb4d05f14d1cc9dae0963e949213
https://github.com/ultralytics/yolov5现在要进某次commit就是在原本网站加上/commit/c5360f6e7009eb4d05f14d1cc9dae0963e949213
Fix `--data from_HUB.zip` (#4732) · ultralytics/yolov5@c5360f6 (github.com)https://github.com/ultralytics/yolov5/commit/c5360f6e7009eb4d05f14d1cc9dae0963e949213然后点browse files
然后注意,这个时候是点code右边下三角之后选择download zip(不能用clone,不然还是下的最新版本)
最后提一句:目前查看一个项目的commit在:

网上有些图是以前的github。
二、识别图片的demo变成实时摄像头检测
import os
import urllib
import traceback
import time
import sys
import numpy as np
import cv2
from rknn.api import RKNN
from PIL import Image
# init runtime environment
print('--> Init runtime environment')
# ret = rknn.init_runtime()
ret = rknn.init_runtime(target='rv1126', device_id='256fca8144d3b5af')
if ret != 0:
print('Init runtime environment failed')
exit(ret)
print('done')
capture = cv2.VideoCapture(0)
ref, frame = capture.read()
if not ref:
raise ValueError("未能正确读取摄像头(视频),请注意是否正确安装摄像头(是否正确填写视频路径)。")
fps = 0.0
while(True):
t1 = time.time()
# 读取某一帧
ref, frame = capture.read()
if not ref:
break
# 格式转变,BGRtoRGB
frame = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
#############
# 进行检测
img = frame
img, ratio, (dw, dh) = letterbox(img, new_shape=(IMG_SIZE, IMG_SIZE))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Inference
print('--> Running model')
outputs = rknn.inference(inputs=[img])
# simple post process
boxes, classes, scores = yolov5_post_process_simple(outputs[0])
img_0 = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
if boxes is not None:
draw(img_0, boxes, scores, classes)
cv2.imshow("direct result", img_0)
# full post process
input0_data = outputs[0].transpose(0,1,4,2,3)
input1_data = outputs[1].transpose(0,1,4,2,3)
input2_data = outputs[2].transpose(0,1,4,2,3)
input0_data = input0_data.reshape(*input0_data.shape[1:])
input1_data = input1_data.reshape(*input1_data.shape[1:])
input2_data = input2_data.reshape(*input2_data.shape[1:])
input_data = list()
input_data.append(np.transpose(input0_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input1_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input2_data, (2, 3, 0, 1)))
boxes, classes, scores = yolov5_post_process_full(input_data)
img_1 = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
#img_1 = img_1[:,:,::-1]
if boxes is not None:
draw(img_1, boxes, scores, classes)
fps = ( fps + (1./(time.time()-t1)) ) / 2
print("fps= %.2f"%(fps))
#img_1 = cv2.putText(frame, "fps= %.2f"%(fps), (0, 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow("video",img_1[:,:,::-1])
c= cv2.waitKey(1) & 0xff
if c==27:
capture.release()
break
print("Video Detection Done!")
capture.release()
cv2.destroyAllWindows()这里我就不过多解释了,就是你看着我这段程序,对照一下原本给的那个test.py的这一段,你就大概知道我怎么处理了,然后我还多加了一个fps,其它的都不用改,因为我这一部分只是单纯实现从图片到摄像头实时处理(摄像头实时处理其实就是相当于循环一直给图片罢了)
三、如何使用自训练模型和官方的test.py进行目标检测
这一部分内容是建立在前面的两部分之上的。
首先通过netron来查看onnx文件我发现一个很奇怪的问题,就是那个官方给的onnx最后有个奇怪的detect层,这是我其他训练的模型生成的onnx所没有的,就算是切换opset到12也没有出现。
但是在使用那个commit版本我找到了答案,那个版本的export.py里面有一个选项,当你使用python export.py --simplify
那生成的onnx就是和官方给的一模一样了(输出层数稍有不同,但结构完全相同)。
第二,随着我实践的变多,我后面发现其实最后有没有那个detect层都可以使用官方程序里的后处理程序,换言之,只要你是yolov5s训练出来的pt权重文件,都可以最后转化成rknn然后用官方程序里的后处理操作(画框)。当然这里也有一些限制:1、后续yolov5s版本算子是否支持?2、输出格式outputs有一些限制:后面会放图。这部分在后面详细介绍。
第三,我强烈建议把官方的test.py拆成两部分:1、onnx_to_rknn.2、板子推理和后处理。
就是转化部分是:(注意那个config,我上一篇有提过)
# Create RKNN object
rknn = RKNN()
if not os.path.exists(ONNX_MODEL):
print('model not exist')
exit(-1)
# pre-process config
print('--> Config model')
rknn.config(reorder_channel='0 1 2',
mean_values=[[0, 0, 0]],
std_values=[[255, 255, 255]],
optimization_level=3, target_platform= ['rv1126'])
print('done')
# Load ONNX model
print('--> Loading model')
ret = rknn.load_onnx(model=ONNX_MODEL)
if ret != 0:
print('Load yolov5 failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=False, dataset=DATASET)
if ret != 0:
print('Build yolov5 failed!')
exit(ret)
print('done')
# Export RKNN model
print('--> Export RKNN model')
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:
print('Export yolov5rknn failed!')
exit(ret)
print('done')
这一个部分就是直接将onnx转化为rknn
然后有了rknn模型的话推理就直接加载rknn模型即可:
# Create RKNN object
rknn = RKNN()
ret = rknn.load_rknn(RKNN_MODEL)
# init runtime environment
print('--> Init runtime environment')
# ret = rknn.init_runtime()
ret = rknn.init_runtime(target='rv1126', device_id='256fca8144d3b5af')
if ret != 0:
print('Init runtime environment failed')
exit(ret)
print('done')
# Inference
print('--> Running model')
outputs = rknn.inference(inputs=[img])大致这么个流程。搭配我前面第二部分内容,基本上就明白我意思了。
那接下来我就介绍一下如何通用自训练模型来进行后处理:
欲知后事如何,请听下回分解(我先吃个饭)
——————————————————————
1、训练yolov5模型注意点
首先在训练yolov5模型的时候也有注意点:
YOLOv5训练自己的数据集(超详细完整版)_深度学习菜鸟的博客-CSDN博客_yolov5训练自己的数据集
我主要是看这篇文章训练的,然后我讲讲总结和别的心得吧。
1、数据集准备,它这里面介绍了自己弄数据集等等比较多内容,那对像我之前已经准备好了voc数据集的(bdd100k转化而来),其实要做的就是把图片文件夹和标签文件夹名字改了,改成images和labels(一定要这两个名字,程序里对应的)然后如果你是用我之前的voc_annotation.py生成的那个2007_train.txt和2007_val.txt的话,还要用notepad++去把jpg后面的内容去掉。变成这种:

2、data下的xxx.yaml文件
3、model下修改yolov5s.yaml的种类数
4、预训练模型yolov5s.pt(这玩意本身就可以拿来预测)
5、修改train.py,这个建议一行行看
6、python train.py --noautoanchor
训练的时候我个人感觉关掉锚框自适应比较好,因为我之前没关,所以训练了一个锚框自适应的模型,然后我又发现我找不着这自适应后的锚框文件在哪,也就不知道新锚框数据,这导致我根本用不了它去rv1126上后处理。然后其实默认的锚框已经可以适用于大多数情况。
2、rknn-toolkit的yolov5后处理分析:

首先设置断点,主要是看outputs的数据格式。
1、官方给的模型
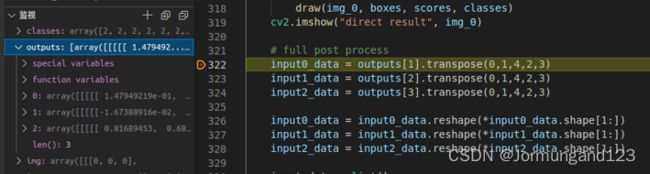 看左边,outputs有三个五维数组。
看左边,outputs有三个五维数组。
含义是:首先你得有前面我csdn中yolov3的理解。
输出的含义是:三个尺度(大中小目标)的输出,然后五维数组的shape是:
1×3×80×80×(80+5)
1×3×40×40×(80+5)
1×3×20×20×(80+5)
1×三个锚框×(80×80个格子,在yolov3中是13×13那种)×(80个类别+1个confidence+4个锚框调整参数)
对代码的调整:
目前outputs只有三个,所以要改成input0_data = outputs[0].transpose(0,1,4,2,3)
就是outputs索引从1,2,3到0,1,2
2、yolov5-5.0

这里的outputs变成了四个,你可以看onnx,我觉得是因为在转onnx的时候多了一个simplify模式的detect层,所以多了一个拼接的3维数组。
对代码的调整:
就是outputs索引为1,2,3对应5维矩阵即可。
3、yolov5-pytorch

outputs变成了3个,但是是4维矩阵,这里是从:
1×3×80×80×(80+5)变成了1×255×80×80
这里注意啊,我这只是描述数组的shape,具体是3×80还是80×3的顺序自己用netron看吧。
对代码的调整:
目前我没去调整,但调整思路比较固定,就是变换维度和顺序和前面的两种模型的输出一样就行,然后注意从255到3×85可能有一些问题(是否是刚好划分成三个锚框要的数据)。
四、后续
目前在看那个rknpu的yolov5的c的程序,那下面的那个rknn模型很勾八怪,netron看不了结构,只有输入输出,跟个黑箱一样。但是意外的是输出跟那个yolov5-pytorch的输出结构差不多,看看能不能直接用。
但其实也不影响,目前估计就是看看单独板子运行的推理时间,推理准确性要求都不需要。