Matching the Blanks: Distributional Similarity for Relation Learning (通篇翻译)
Matching the Blanks:关系学习的分布相似性
Livio Baldini Soares Nicholas FitzGerald Jeffrey Ling ∗ Tom Kwiatkowski Google Research { liviobs,nfitz,jeffreyling,tomkwiat } @google.com
摘要
通用关系抽取器可以对任意关系进行建模,是信息抽取的核心目标。人们一直在努力构建通用的提取器,这些提取器表示与曲面形式的关系,或者联合嵌入曲面形式与现有知识图中的关系。然而,这两种方法的推广能力都很有限。在本文中,我们基于哈里斯分布假设对关系的扩展,以及学习文本表征(尤其是伯特)的最新进展,仅从实体链接文本构建任务不可知的关系表征。
我们表明,即使不使用任何任务的训练数据,这些表示也显著优于以前关于基于范例的关系提取(FewRel)的工作。我们还表明,使用我们的任务不可知表示初始化的模型,然后在有监督的关系提取数据集上进行调整,在semeval 2010任务8、KBP37和TACRED上的性能明显优于之前的方法。
1引言
阅读文本以识别和提取实体之间的关系一直是自然语言处理的长期目标(Cardie,1997)。通常,与提取相关的工作分为三类。在第一组中,受监督(kambhatla,2004;GuoDong等人,2005;Zeng等人,2014)或远程监督关系提取器(Mintz等人,2009)在有限的模式中学习从文本到关系的映射。作为第二组,开放信息提取通过使用关系的表面形式(Banko等人,2007年;Fader等人,2011年;Stanovsky等人,2018年)来表示关系,从而消除了预定义模式的局限性,这增加了范围,但也导致了相关的通用性不足,因为许多表面形式可以表达相同的关系。最后,通用模式(Riedel et al.,2013)既包含了文本的多样性,也包含了模式关系的简洁性,以构建一种扩展到任意文本输入(Toutanova et al.,2015)和任意实体对(Verga和McCallum,2016)的联合表示。然而,与远程监督关系提取器一样,通用模式依赖于可以与文本对齐的大型知识图(通常是Freebase(Bollacker et al.,2008))。
基于Lin和Pantel(2001)将Harris的分布假设(Harris,1954)扩展到关系,以及通过观察上下文学习单词表征的最新进展(Mikolov等人,2013年;Peters等人,2018年;Devlin等人,2018年),我们提出了一种直接从文本学习关系表征的新方法。首先,我们研究了Transformer神经网络体系结构(Vaswani et al.,2017)对实体对之间关系进行编码的能力,并确定了一种在监督关系提取方面优于以往工作的表示方法。
然后,我们提出了一种通过匹配空白来训练这种关系表示的方法,无需任何来自知识图或人工注释器的监督。
[BLANK]受卡尔早期封面的启发,录制了[BLANK]最受欢迎的版本之一[BLANK]。[BLANK]演唱的[BLANK]被《时代》杂志称为“最伟大的歌曲之一”,并被列入《滚石》的“有史以来最伟大的500首歌曲”名单。
图1:“匹配空格”示例,其中两个关系语句共享相同的两个实体。
继Riedel等人(2013年)之后,我们假设可以访问一个文本语料库,其中的实体与唯一标识符相连,我们将关系语句定义为包含两个标记实体的文本块。由此,我们创建了训练数据,其中包含关系语句,其中实体已替换为特殊的[空白]符号,如图1所示。我们的训练程序采用包含关系语句的空白对,其目标是鼓励关系表示在相同的实体对范围内相似。训练结束后,我们在最近发布的《费雷尔任务》(Han et al.,2018)中使用了学习到的关系表征,其中的特定关系,如“原始工作语言”用一些示例来表示,例如《人群》(意大利语:La Folla)是1951年的一部意大利电影。Han等人(2018年)将FewRel作为一个监督数据集,旨在评估模型在测试时适应新领域关系的能力。我们表明,通过匹配空白的训练,我们可以在没有看到任何FewRel训练数据的情况下,超越Han et al.(2018)在FewRel上的最佳表现。我们还表明,通过匹配空白和调整FewRel预先训练的模型在FewRel评估上优于人类。同样,通过匹配空白然后调整标记数据的训练,我们显著提高了SemEval 2010任务8(hendrickx et al.,2009)、KBP-37(Zhang and Wang,2015)和TACRED(Zhang et al.,2017)关系提取基准的性能。
2概述
任务定义在本文中,我们重点学习从关系语句到关系表示的映射。形式上,假设![]() 是一个标记序列,其中x0=[CLS]和xn=[SEP]是特殊的开始和结束标记。设s1=(i,j)和s2=(k,l)是整数对,使得0
是一个标记序列,其中x0=[CLS]和xn=[SEP]是特殊的开始和结束标记。设s1=(i,j)和s2=(k,l)是整数对,使得0![]() ,该函数将关系语句映射到一个固定长度的向量
,该函数将关系语句映射到一个固定长度的向量![]() ,该向量表示用s1和s2标记的实体之间以x表示的关系。
,该向量表示用s1和s2标记的实体之间以x表示的关系。
本文包括两个主要贡献。首先,在第3.1节中,我们研究了关系编码器fθ的不同架构,所有架构都构建在广泛使用的Transformer序列模型之上(Devlin等人,2018;Vaswani等人,2017)。我们通过将这些体系结构应用于一套带有监督训练的关系提取基准来评估每一种体系结构。
我们的第二个更重要的贡献(见第4节)是表明fθ可以通过实体链接文本的形式从广泛可用的远程监控中学习。
3.关系学习的架构
这项工作的主要目标是开发直接从文本生成关系表示的模型。鉴于最近接受语言建模变体培训的deep transformers表现强劲,我们采用Devlin et al.(2018)的伯特模型作为我们工作的基础。在本节中,我们将探讨用Transformer模型表示关系的不同方法。
3.1关系分类和提取任务
我们在一系列有监督的关系提取基准上评估了不同的表示方法。我们使用的关系提取任务可以大致分为两类:完全监督关系提取和少量镜头关系匹配。
对于监督任务,目标是在给定关系语句r的情况下,预测关系类型t∈ 其中T是关系类型的固定字典,T=0通常表示关系语句中的实体之间缺乏关系。对于这类任务,我们根据SemEval 2010任务8(hendrickx等人,2009年)、KBP-37(Zhang和Wang,2015年)和TACRED(Zhang等人,2017年)进行评估。更正式地说,在少数镜头关系匹配的情况下,根据查询关系语句对一组候选关系语句进行排序和匹配。
在此任务中,测试和开发集中的示例通常包含训练集中不存在的关系类型。对于这类任务,我们在FewRel(Han et al.,2018)数据集上进行评估。
具体来说,我们得到了K组N个标记的关系语句
![]()
,其中![]() 是对应的关系类型。目标是预测查询关系语句rq的
是对应的关系类型。目标是预测查询关系语句rq的![]() 。
。

图2:我们的模型中使用的损失说明。左图描述了一个适用于监督训练的模型,其中模型预计将根据预定义的关系类型字典进行分类。右图描绘了一个成对的相似性损失,用于少数镜头分类任务。
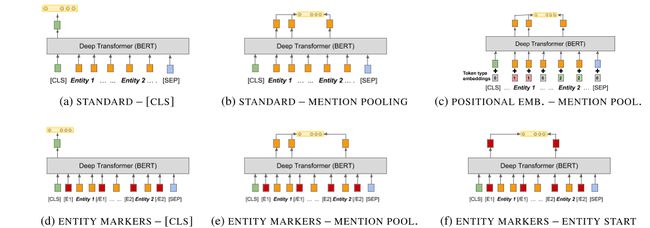
图3:从深度变压器网络中提取关系表示的各种架构。图(a)描述了具有标准输入和[CLS]输出的模型,图(b)描述了具有标准输入和提及池输出的模型,图(c)描述了具有位置嵌入输入和提及池输出的模型。图(d)、(e)和(f)在使用[CLS]时使用实体标记输入,分别提到池和实体启动输出。

表1:受监督关系提取任务的结果。模型名称标有*符号的行上的结果报告为已发布,所有其他数字均由我们计算。SemEval 2010任务8未建立默认的开发拆分;在这项工作中,我们使用了训练集的随机切片,其中包含1500个示例。
3.2 Deep Transformers模型的关系表示
在本节的所有实验中,我们从Devlin et al.(2018)提供的BERT大模型和针对特定任务损失的训练开始。
由于BERT之前没有被应用于关系表示问题,我们的目标是回答两个主要的建模问题:(1)如何表示BERT输入中感兴趣的实体,以及(2)如何从BERT的输出中提取关系的固定长度表示。
我们为输入编码和输出关系表示提供了三个选项。图3显示了这六种组合。
3.2.1实体范围标识
回想一下,在第2节中,关系语句r=(x,s1,s2)包含令牌x序列和实体跨度标识符s1和s2。我们提供了三种不同的选项,用于将有关焦点跨度s1和s2的信息获取到我们的BERT编码器中。
标准输入首先,我们使用一个伯特模型进行实验,该模型无法对跨越s 1和s 2的实体进行任何显式识别。
我们将此选项称为标准输入。
这是一个重要的参考点,因为我们相信BERT有能力识别x中的实体,但在标准输入中,当x包含两个以上的实体时,无法知道哪两个实体处于焦点。
对于输入中的每个标记的位置嵌入,BERT还添加了一个切分嵌入,主要用于向模型中添加句子切分信息。为了解决标准表示缺乏明确的实体标识的问题,我们引入了两个新的分段嵌入,一个添加到span s1中的所有标记,另一个添加到span s2中的所有标记。这种方法类似于之前的工作,其中位置嵌入已应用于关系提取(Zhang等人,2017年;Bilan和Roth,2018年)。
实体标记标记最后,我们用四个保留字片段来增加x,以标记关系语句中提到的每个实体的开始和结束。我们引入[e1 start]、[e1 end]、![]() 和
和![]() 并修改x以给出
并修改x以给出

,我们将这个令牌序列输入到BERT而不是x。我们还更新了实体索引s̃1=(i+1,j+1)和s̃2=(k+3,l+3)以说明插入的令牌。我们将输入的这种表示形式称为实体标记。
3.3定长关系表示法
现在我们介绍三种从伯特编码器中提取固定长度关系表示hr的方法。这三种变体依赖于提取transformer网络的最后一个隐藏层,我们将n=| x |(或| x̃|,如果使用实体标记标记),定义为ash=[h 0,…h n]。
[CLS]令牌从第2节中调用,每个x以一个保留的[CLS]令牌开始。Devlbert等人在2018年使用的句子长度是固定的。
我们采用[CLS]输出h0作为第一个关系表示。
实体提及池我们通过最大化与每个实体提及中的单词片段对应的最终隐藏层来获得hr,从而得到两个向量
![]()
和he2=MAXPOOL([hk…hl− 1])代表提及的两个实体。我们将这两个向量连接起来,得到单个表示![]() ,其中〈a | b〉是a和b的连接。我们将这种体系结构称为“提到池”。
,其中〈a | b〉是a和b的连接。我们将这种体系结构称为“提到池”。
实体开始状态最后,我们建议在使用实体标记时,简单地用对应于其各自开始标记的最终隐藏状态的串联来表示两个实体之间的关系。回想一下实体标记在x中插入标记,在S1和S2中创建偏移量,我们对关系的表示是![]() 。我们将这种输出表示形式称为实体开始输出。请注意,这只能应用于实体标记输入。
。我们将这种输出表示形式称为实体开始输出。请注意,这只能应用于实体标记输入。
图3展示了我们在本节中评估的几个变体。除了定义模型输入和输出架构外,我们还修复了用于训练模型的训练损失(如图2所示)。在所有模型中,来自Transformer网络的输出表示被馈送到一个完全连接的层中,该层要么(1)包含线性激活,要么(2)对表示执行层规范化(Ba等人,2016)。
我们将后转换层的选择视为一个超参数,并为每个任务使用性能最佳的层类型。
对于监督任务,我们引入了一个新的分类层![]() ,其中his表示关系表示的大小,K表示关系类型的数量。分类损失是相对于真实关系类型的
,其中his表示关系表示的大小,K表示关系类型的数量。分类损失是相对于真实关系类型的![]() softmax的标准交叉熵。
softmax的标准交叉熵。
对于少镜头任务,我们使用查询语句的关系表示和每个候选语句之间的点积作为相似性分数。在这种情况下,我们还应用了关于真实类的相似性得分softmax的熵损失。
我们使用以下一组超参数对所有变体的伯特模型执行特定任务的微调:•Transformer架构:24层,1024个隐藏大小,16个头部•权重初始化:伯特大•Transformer后层:密集线性激活(KBP-37和TACRED),或层规范化层(SemEval 2010和FewRel)。
•训练阶段:1至10•学习率(监督):3e-5,Adam•批量大小(监督):64•学习率(少镜头):1e-4,SGD•批量大小(少镜头):256表1显示了模型变量在三个监督关系提取任务和少镜头关系分类任务的5向1镜头变量上的结果。对于所有四项任务,使用实体标记输入表示法和实体开始输出表示法的模型得分最高。
从结果可以看出,在输入中添加位置信息对于模型学习有用的关系表示至关重要。与之前从位置嵌入中获益的工作不同(Zhang等人,2017年;Bilan和Roth,2018年),deep Transformers从看到新的实体边界词块(实体标记)中获益最大。还值得注意的是,最好的变体在所有四项任务上都优于之前发布的模型。在本文的其余部分中,我们将在进一步培训和评估我们的模型时使用此体系结构。
4.通过匹配空格进行学习
到目前为止,我们已经使用人类标记的训练数据来训练我们的关系语句编码器fθ。受开放信息提取(Banko et al.,2007;Angeli et al.,2015)的启发,该方法直接从标记文本中导出关系,我们现在引入一种新的训练fθ方法,无需预定义的本体或关系标记的训练数据。相反,我们声明,对于任何一对关系语句r和r′,如果两个关系语句r和r′表示语义相似的关系,则内积![]() 应该是高的。如果这两个关系语句表示语义不同的关系,那么这个内积应该如下所示。
应该是高的。如果这两个关系语句表示语义不同的关系,那么这个内积应该如下所示。
与信息提取远程监控中的相关工作不同(Hoffmann等人,2011;Mintz等人,2009),我们在训练时不使用关系标签。相反,我们观察到web文本中存在高度冗余,任意一对实体之间的每个关系都可能被多次声明。随后,如果s1表示同一实体ass′1,s2表示同一实体ass′2,![]() 更有可能编码与
更有可能编码与![]() 相同的语义关系。我们从一个新的文本开始,介绍了一种新的学习方法。我们介绍了这种通过匹配空格(MTB)进行学习的方法。在第5节中,我们展示了MTB学习的关系表示法可以在不进行任何进一步调整的情况下用于关系提取,甚至可以击败之前对人类标记数据进行训练的工作。
相同的语义关系。我们从一个新的文本开始,介绍了一种新的学习方法。我们介绍了这种通过匹配空格(MTB)进行学习的方法。在第5节中,我们展示了MTB学习的关系表示法可以在不进行任何进一步调整的情况下用于关系提取,甚至可以击败之前对人类标记数据进行训练的工作。
4.1学习设置
设E是一组预定义的实体。让
![]()
成为一个关系语句的语料库,这些语句被标记为两个实体![]() 和
和![]() 。回想一下,在第2节中,
。回想一下,在第2节中,![]() ,其中SI1和SI2界定了XI中提到的实体。通过将关系语句ri与分别对应于跨度
,其中SI1和SI2界定了XI中提到的实体。通过将关系语句ri与分别对应于跨度![]() 和
和![]() 的两个实体
的两个实体![]() 和
和![]() 配对来创建每个项ind。
配对来创建每个项ind。
我们的目标是学习一个关系语句编码器fθ,我们可以用它来确定两个关系语句是否编码相同的关系。为此,我们定义了以下二元分类器

,为r和r′编码相同关系(l=1)或不编码相同关系(l=0)的情况分配一个概率。
然后,我们将学习θ的参数化,该参数化使损失

最小化,其中![]() 是Kronecker delta,其值为1 iff
是Kronecker delta,其值为1 iff![]() ,否则为0。
,否则为0。

表2:“匹配空白”自动生成的训练数据示例。语句对RA和RB是一个积极的例子,因为它们共享两个实体的分辨率。语句对RA和RC以及r带RC形成强负对,因为它们共用一个实体,但包含其他不匹配的实体。
4.2引入空白
读者可能已经注意到,方程式1中的损失可以通过用于创建D的实体链接系统完美地最小化。而且,由于这个连接系统没有任何关系的概念,因此假设fθ会以某种方式神奇地建立有意义的关系表示是不合理的。
为了避免简单地重新学习实体链接系统,我们引入了一个经过修改的语料库
![]()
,其中每个r̃i=(x̃i,s i 1,s i 2)包含一个关系语句,其中一个或两个实体提及可能已被一个特殊的[空白]符号替换。具体地说,x̃包含由概率为α的s1定义的跨度。否则,跨度将替换为单个[空白]符号。S2也是如此。D̃中只有![]() 的关系语句明确指出了参与关系的两个实体。
的关系语句明确指出了参与关系的两个实体。
因此,最小化L(D̃)需要fθ做的不仅仅是识别r中的命名实体。
我们假设D̃上的训练将导致fθ编码两个可能被忽略的实体跨度之间的语义关系。第5节的结果支持这一假设。
4.3匹配空白训练
为了用匹配的这是老的classifier任务对模型进行训练,我们构建了一个类似于BERT的训练设置,其中同时使用了两种损失:蒙面语言模型损失和匹配空白的损失。为了生成训练语料库,我们使用英文维基百科并从HTML段落块中提取文本段落,忽略列表和表格。我们使用现成的实体链接system 1,用唯一的知识库标识符(例如Freebase ID或Wikipedia URL)注释文本范围。span注释不仅包括专有名词,还包括其他指称实体,如普通名词和代词。从这个带注释的语料库中,我们提取关系语句,其中每个语句在一个固定大小的标记2窗口中至少包含两个固定实体。为了防止对涉及流行实体的关系语句产生较大的偏见,我们通过随机抽样包含任何给定实体的恒定数量的关系语句来限制包含同一实体的关系语句的数量。
如前一节所述,我们使用这些语句来训练模型参数,以最小化L(D̃)。在实践中,不可能像方程1中那样比较每一对关系陈述,因此我们使用噪声对比估计(Gutmann和Hyvảrinen,2012;Mnih和Kavukcuoglu,2013)。在这个估计中,我们考虑所有包含相同实体的关系语句的正对,因此方程1中第一项的贡献没有变化-在这里。然而,这种近似确实改变了第二项的贡献。
我们不是对不包含同一对实体的所有关系语句对求和,而是从所有关系语句对集中统一随机抽样,或从共享单个实体的关系语句集中抽样。我们加入了第二组“硬”否定,以说明大多数随机抽样的关系语句对甚至不太可能是局部相关的,并且我们希望确保训练过程能够看到引用相似但不同关系的关系语句对。最后,我们用[空白]符号替换每个实体的提及,概率为α=0。7,如第3.2节所述,以确保模型不会因评估任务中没有[空白]符号而混淆。我们从英文维基百科中总共生成了6亿对关系语句,大致分为50%的正对和50%的强负对。

表3:FewRel少数镜头关系分类任务的测试结果。Proto Net是Han等人(2018)发布的最好的系统。在撰写本文时,我们的BERT EM+MTB模型在5向1拍配置上的表现优于排行榜上的顶级模型(http://www.zhuhao.me/fewrel/),在10向1拍配置上的表现优于10%,在10向1拍配置上的表现优于15%。
5.实验评估
在本节中,我们通过匹配空白来评估训练的影响。我们从第3.3节中最好的基于伯特的模型开始,我们称之为伯特EM,并将其与通过匹配空白任务(伯特EM+MTB)训练的变体进行比较。我们通过将Transformer权重初始化为BERT LARGE的权重,训练BERT EM+MTB模型,并使用以下参数:•学习率:3e-5 with Adam•批量:2048•步骤数:100万•关系表示:实体标记我们报告第3.1节中所有任务的结果,对BERT EM和BERT EM+MTB使用相同的特定任务训练方法。
5.1少样本关系匹配
首先,我们研究了BERT-EM+MTB在没有任何特定任务的训练数据的情况下解决FewRel任务的能力。由于FewRel是一种基于范例的方法,我们可以根据每个候选relasemeval语句的表示与范例表示的内积对其进行排序。
图4显示,任务不可知的BERT-EM和BERT-EM+MTB模型在FewRel任务上的表现优于之前发布的最新状态,即使它们没有看到任何FewRel训练数据。
对于BERT EM+MTB,与Han等人。
(2018)的受监督方法非常重要——在5向1次任务中占8.8%,在10向1次任务中占12.7%。BERT EM+MTB在这种无监督的情况下也显著优于BERT EM,这是意料之中的,因为在BERT EM的训练期间没有特定关系的损失。
为了研究监督对BERT-EM和BERT-EM+MTB的影响,我们引入了越来越多的FewRel的训练数据。图4显示了性能的提高,因为我们或者增加了每种关系类型的训练示例的数量,或者增加了训练数据中的关系类型的数量。当允许访问所有训练数据时,BERT EM接近BERT EM+MTB的性能。然而,当我们在训练期间保持所有关系类型,并改变每个示例的类型数量时,BERT EM+MTB只需要6%的训练数据来匹配在所有训练数据上训练的BERT EM模型的性能。我们观察到,保持关系类型的多样性,并减少每种类型的示例数,是减少此任务注释工作量的最有效方法。图4中的结果表明,可以使用MTB训练来显著减少实现基于示例的关系提取系统的工作量。
最后,我们在表3中报告了BERT EM+MTB在FewRel的所有完全监督任务中的表现。我们发现,它优于Han等人(2018)报告的人类上限,并且显著优于FewRel排行榜上所有其他已发布或未发布的提交。

表4:BERT EM+MTB和基于BERT EM的关系分类器在各自测试集上的F1分数。SOTA系统的详细信息见表1。
5.2监督关系提取
表4包含我们的分类器在监督关系提取数据上的调整结果。如第3.2节所述,我们基于伯特EM的分类器在这三项任务中的表现优于之前公布的结果。额外的基于MTB的训练进一步提高了所有任务的F1成绩。
我们还分析了两个模型的性能,同时减少了受监督的特定于任务的调整数据量。表5中显示的结果显示了在调整特定于任务的训练数据的随机子集时开发集的性能。对于所有任务,我们发现基于MTB的训练对于资源不足的情况更为有效,在这种情况下,基于BERT EM和基于BERT EM+MTB的分类器之间的性能差距更大。这进一步支持了我们的论点,即通过匹配空格进行训练可以显著减少创建关系提取器和填充知识库所需的人力投入。
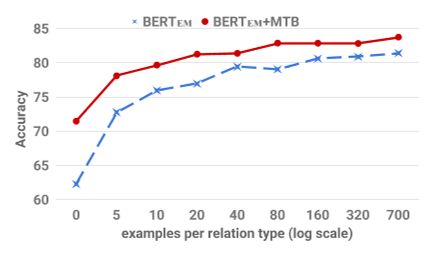
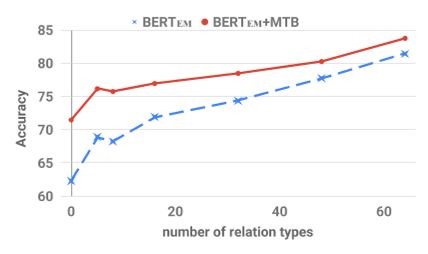

图4:在FewRel上调优的分类器的比较。可用于微调开发结果的注释集。在左侧,我们显示准确度,同时改变每个关系类型的示例数,同时保持所有64个可用于训练的关系。在右边,我们显示了两个模型的开发集的准确性,同时改变了可供调整的关系类型的总数,同时保持了每个关系类型的所有700个示例。在这两个图中,都会显示任务的10路1拍变体的结果。

表5:F1在有监督的关系提取任务的开发集上的得分,同时改变我们的BERT-EM和BERT-EM+MTB模型可用的调整数据量。
6.结论和今后的工作
在本文中,我们研究了直接从文本中产生有用的关系表示的问题。
我们描述了一种新的训练设置,我们称之为匹配空白,它完全依赖于实体分辨率注释。当我们的模型与一种新的结构相结合,用于微调BERT中的关系表示时,我们的模型在三个关系提取任务上达到了最先进的结果,并且在少数镜头关系匹配上优于人类的准确性。此外,我们还展示了新的模型如何在低资源制度下特别有效,并且我们认为它可以显著减少创建关系提取器所需的人力。
在未来的工作中,我们计划通过根据BERT EM+MTB对具有相似表示的关系语句进行聚类来进行关系发现。这将为我们实现真正的通用关系识别和提取目标提供一些途径。我们还将研究可用于在分布式知识库中存储关系三元组的关系和实体的表示。这是受最近知识库嵌入工作的启发(Bordes等人,2013年;Nickel等人,2016年)。
参考文献
Gabor Angeli, Melvin Jose Johnson Premkumar, and Christopher D Manning. 2015. Leveraging linguistic structure for open domain information extraction. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural language Processing , volume 1, pages 344–354.
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E hinton. 2016. Layer normalization. arXiv preprint arXiv:1607.06450 .
Michele Banko, Michael J. Cafarella, Stephen soderland, Matt Broadhead, and Oren Etzioni. 2007. Open information extraction from the web . In proceedings of the 20th International Joint Conference on Artifical Intelligence , IJCAI’07, pages 2670– 2676, San Francisco, CA, USA. Morgan Kaufmann Publishers Inc.
Ivan Bilan and Benjamin Roth. 2018. Position-aware self-attention with relative positional encodings for slot filling . CoRR , abs/1807.03052.
Kurt Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor. 2008. Freebase: A collaboratively created graph database for structuring human knowledge . In Proceedings of the 2008 ACM SIGMOD International Conference on management of Data , SIGMOD ’08, pages 1247–1250, New York, NY, USA. ACM.
Antoine Bordes, Nicolas Usunier, Alberto garciaduran, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multirelational data . In C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems 26 , pages 2787–2795. Curran Associates, Inc.
Claire Cardie. 1997. Empirical methods in information extraction. AI Magazine , 18(4):65–80.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 .
Anthony Fader, Stephen Soderland, and Oren Etzioni. 2011. Identifying relations for open information extraction . In Proceedings of the 2011 Conference on Empirical Methods in Natural Language processing , pages 1535–1545, Edinburgh, Scotland, UK. Association for Computational Linguistics.
Zhou GuoDong, Su Jian, Zhang Jie, and Zhang Min. 2005. Exploring various knowledge in relation extraction. In Proceedings of the 43rd annual meeting on association for computational linguistics , pages 427–434. Association for Computational linguistics.
Michael U Gutmann and Aapo Hyvärinen. 2012. Noise-contrastive estimation of unnormalized statistical models, with applications to natural image statistics. Journal of Machine Learning Research , 13(Feb):307–361.
Xu Han, Hao Zhu, Pengfei Yu, Ziyun Wang, Yuan Yao, Zhiyuan Liu, and Maosong Sun. 2018. Fewrel: A large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation. In proceedings of the 2018 Conference on Empirical methods in Natural Language Processing , pages 4803– 4809.
Zellig S Harris. 1954. Distributional structure. Word , 10(2-3):146–162.
Iris Hendrickx, Su Nam Kim, Zornitsa Kozareva, Preslav Nakov, Diarmuid Ó Séaghdha, Sebastian Padó, Marco Pennacchiotti, Lorenza Romano, and Stan Szpakowicz. 2009. Semeval-2010 task 8: Multi-way classification of semantic relations between pairs of nominals. In Proceedings of the Workshop on Semantic Evaluations: Recent Achievements and Future Directions , pages 94–99. Association for Computational Linguistics.
Raphael Hoffmann, Congle Zhang, Xiao Ling, Luke Zettlemoyer, and Daniel S Weld. 2011. knowledgebased weak supervision for information extraction of overlapping relations. In Proceedings of the 49th Annual Meeting of the Association for computational Linguistics: Human Language technologiesvolume 1 , pages 541–550. Association for computational Linguistics.
Nanda Kambhatla. 2004. Combining lexical, syntactic, and semantic features with maximum entropy models for extracting relations. In Proceedings of the ACL 2004 on Interactive poster and demonstration sessions , page 22. Association for Computational Linguistics.
Dekang Lin and Patrick Pantel. 2001. DIRT: Discovery of Inference Rules from Text . In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’01) , pages 323–328, New York, NY, USA. ACM Press. Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S corrado, and Jeff Dean. 2013. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems , pages 3111–3119.
Mike Mintz, Steven Bills, Rion Snow, and Daniel jurafsky. 2009. Distant supervision for relation extraction without labeled data . In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP , pages 1003–1011, Suntec, Singapore. Association for Computational Linguistics.
Andriy Mnih and Koray Kavukcuoglu. 2013. Learning word embeddings efficiently with noise-contrastive estimation. In Advances in neural information processing systems , pages 2265–2273.
Maximilian Nickel, Lorenzo Rosasco, and Tomaso Poggio. 2016. Holographic embeddings of knowledge graphs . In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence , AAAI’16, pages 1955–1961. AAAI Press.
Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , volume 1, pages 2227–2237.
Sebastian Riedel, Limin Yao, Andrew McCallum, and Benjamin M Marlin. 2013. Relation extraction with matrix factorization and universal schemas. In proceedings of the 2013 Conference of the North american Chapter of the Association for Computational Linguistics: Human Language Technologies , pages 74–84.
Gabriel Stanovsky, Julian Michael, Luke Zettlemoyer, and Ido Dagan. 2018. Supervised open information extraction . In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pages 885– 895, New Orleans, Louisiana. Association for computational Linguistics.
Kristina Toutanova, Danqi Chen, Patrick Pantel, hoifung Poon, Pallavi Choudhury, and Michael Gamon. 2015. Representing text for joint embedding of text and knowledge bases . In Proceedings of the 2015 Conference on Empirical Methods in Natural language Processing , pages 1499–1509, Lisbon, portugal. Association for Computational Linguistics.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information processing Systems , pages 5998–6008.
Patrick Verga and Andrew McCallum. 2016. Row-less universal schema . In Proceedings of the 5th workshop on Automated Knowledge Base Construction , pages 63–68, San Diego, CA. Association for computational Linguistics.
Linlin Wang, Zhu Cao, Gerard de Melo, and Zhiyuan Liu. 2016. Relation classification via multi-level attention cnns . In Proceedings of the 54th Annual Meeting of the Association for Computational linguistics , pages 1298–1307. Association for computational Linguistics.
Daojian Zeng, Kang Liu, Siwei Lai, Guangyou Zhou, and Jun Zhao. 2014. Relation classification via convolutional deep neural network . In Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers , pages 2335–2344. Dublin City University and association for Computational Linguistics.
Dongxu Zhang and Dong Wang. 2015. Relation classification via recurrent neural network . CoRR , abs/1508.01006.
Yuhao Zhang, Victor Zhong, Danqi Chen, Gabor angeli, and Christopher D Manning. 2017. positionaware attention and supervised data improve slot filling. In Proceedings of the 2017 Conference on empirical Methods in Natural Language Processing , pages 35–45.