分割网络综述——Deep Semantic Segmentation of Natural and Medical Images: A Review
论文阅读之分割网络综述
Deep Semantic Segmentation of Natural and Medical Images: A Review
摘要
图像语义分割主要完成像素级别的密集预测任务,同属于一类的像素组成实例可用于场景识别、理解图像内容等。而在医学图像分析领域,图像分割可用来帮助医生辅助诊断。本文则对目前主流的分割网络及医学图像分割网络从以下方面进行综述:结构优化、损失函数优化、序列模型、弱监督模型、多任务模型,为下一步的研究探索指明方向。
# Section I Introduction
将深度学习应用到医学图像分析领域,尤其是医学图像(如X光、MRI、PET、CT图像)分割备受关注,主流研究方向有解决深层次网络的梯度消失问题、应用压缩技术构建轻量级网络、优化损失函数提升模型性能等。
本文的工作主要有:
(1)对现有的自然凸显分割模型及医学图像分割模型进行综述,涵盖2D及3D图像。
(2)将分割框架总结为以下六类:结构优化、损失函数优化、数据合成、弱监督模型、序列模型、多任务模型。详情参见Fig1.
(3)基于以上总结,为下一步的研究探索指明方向。
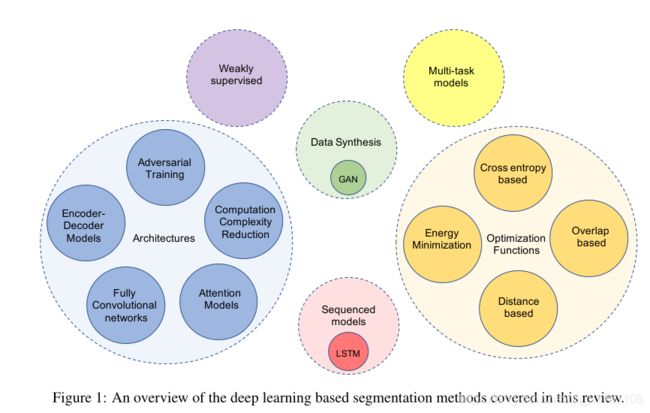
Section II 自然图像分割网络
本节按照先自然图像分割再医学图像分割的顺序对分割网络的结构优化进行综述,主要对网络深度、宽度、连接方式进行优化以及引入新的网络层次等。
Part A 全卷积网络(FCN)
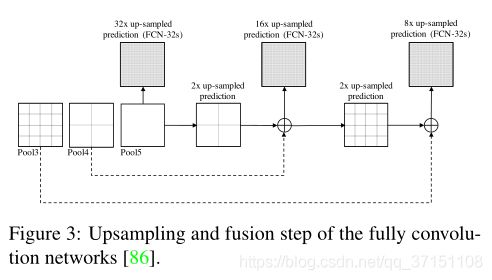
2015年提出的全卷积网络可谓是语义分割模型的开山鼻祖,通过将传统CNN的全连接层替换为上采样/转置卷积,从而使得网络输出不再是概率而是heatmap,从而可以进行像素级别的密集预测。FCN模型入如图所示,在FCN中为了更好的保留空间信息,还将浅层输出融合到上采样中从而获得更精细的像素级分割图谱。

 Part II编解码网络(Encoder-Decoder)
Part II编解码网络(Encoder-Decoder)
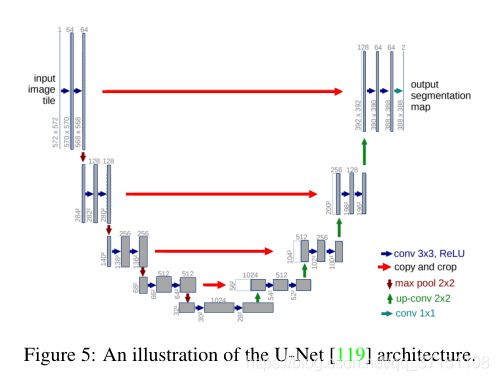
另一类语义分割网络是以SegNet、UNet等为代表的的编解码网络结构,其中编码网络用于特征提取,通常每一个encoder为多层卷积+BN+ReLu的结构,解码网络的作用则是将encoder网络输出的低分辨率特征对应每一层次复原为输入图像分辨率从而进行像素级别的分类即分割。
下图分别展示了SegNet和UNet的网络结构。

可以看到在SegNet中通过最大池化完成的上采样,而FCN中是通过转置卷积完成的。
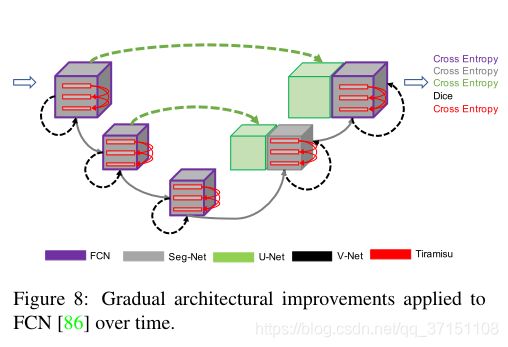
 基于编解码结构的还有后来Milletari提出的VNet结构、DenseNet结构等。在VNet中加入了残差连接并且进行的是3D分割;基于DenseNet思想加入密集连接的提拉米苏网络(TiramisuNet);利用空间金字塔模型、空洞卷积完成不同级上下文信息的融合等(空间金字塔模型通过不同规模的filter和池化完成不同层次特征的提取,比如后面网络更容易捕获锋利的边缘,恢复空间信息;而空洞卷积则是通过不同的膨胀率完成不同级别特征的提取)。
基于编解码结构的还有后来Milletari提出的VNet结构、DenseNet结构等。在VNet中加入了残差连接并且进行的是3D分割;基于DenseNet思想加入密集连接的提拉米苏网络(TiramisuNet);利用空间金字塔模型、空洞卷积完成不同级上下文信息的融合等(空间金字塔模型通过不同规模的filter和池化完成不同层次特征的提取,比如后面网络更容易捕获锋利的边缘,恢复空间信息;而空洞卷积则是通过不同的膨胀率完成不同级别特征的提取)。
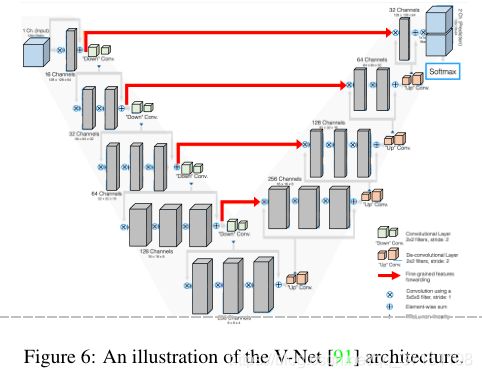
下图可以对比看编解码网络中对连接方式进行的优化,如UNet中通过skip connection(green arrow)完成编码网络信息传递到解码网络,VNet在每一个Block引入残差连接,TitamisuNet则是在每一个Block内部前后卷积层中引入密集连接。
 **Part C网络精简 **
**Part C网络精简 **
思路3是通过张量素描、通道/网络剪枝、稀疏连接等精简网络,降低计算复杂度。
**Part D 注意力网络 **
可以通过在不同层产生的一系列输出或特征图谱中挑选出最具辨别力的部分完成注意力的施加。比如通过global aberage pooling选择显著的特征图、在ResNet中添加额外的注意力模块、还有同时关注空间和通道特征的Dual Atteention网络等。
**Part E 生成对抗网络 **
GoodFellow提出的GANs思想也可以迁移到予以分割网络中,通过输入GT和分割网络的输出结果,从而训练网络输出更贴近真实分割图谱。
Section III医学图像分割网络
医学图像分割网络按照分割的图像类型可分为2D和3D。
Part A 模型压缩
分割网络用于医学领域尤其是临床,不可避免对实时性有着要求,而且处理的图像往往分辨率超高,因此进行网络压缩是十分必要的。目前有通过NAS、group normalization、空洞卷积、权重量化等方案进行模型压缩。
Part B 基于编解码结构的医学图像分割模型优化方案
编解码结构已经展示了在图像分割领域的优异性能,但医学图像分割与自然图像相比仍有很多限制,比如医学图像采集困难因此很难基于大规模的数据集进行训练,从而容易导致网络的过拟合、泛化性差等问题。
按照Section II有以下优化思路:
注意力机制:
做的主要尝试有使用多级注意力提升腹腔MRI图像的分割质量、空洞卷积模块保留细节信息用于3D图像分割
生成对抗网络
在医学图像分割GANs已有用于胰腺CT图、视网膜血管分割、脑肿瘤CT图的研究。
循环神经网络
Recurrent的思想主要利用LSTM等处理序列模型,因为医学扫描图像很多都是时序序列;另一思路是借助recurrent递归思想增加细节信息的提取、长程依赖关系的传递等,如提升UNet的分割性能,之前也有一些花式UNet的阅读。
Section IV损失函数优化
由于损失函数是网络更新的动力,因此分割模型的一种优化思路就是对损失函数进行优化。
交叉熵损失函数(Cross Entropy)
在进行像素级分类时最常用的就是交叉熵损失函数,通过逐像素计算预测值与真实值获得,公式如下:

 优化1:带权重的交叉熵损失函数(WCE)
优化1:带权重的交叉熵损失函数(WCE)
进行医学图像分割一个很显著的特点就是不同类别样本所占比例有较大差异,如视网膜血管分割时前景血管所占原图比例很少,大部分为黑色背景,基于这种高度不均衡的样本训练出的分类器性能可想而知。因此自然而然想到带权重的交叉熵损失函数为不同类别赋予不同权重来减少样本不均衡问题对模型性能的影响。
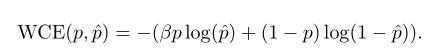 优化2:Focal Loss
优化2:Focal Loss
Focal Loss也是为了解决正负样本不均衡的问题,在cross entropy上作了进一步修改,对比前文的CE发现多了一项:
![]() 从而变成:
从而变成:
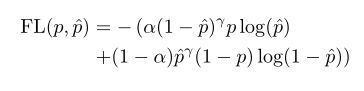 其中alpha比例因子就是用来平衡正负样本所占比重的。
其中alpha比例因子就是用来平衡正负样本所占比重的。
关于Focal Loss的理解可进一步参考:Focal Loss
基于重叠的评价指标
主要有Dice系数(即F1score)、Tversky Loss、指数对数Loss、Lovasz-Softmax Loss、Boundry Loss、Conservertive Loss等。
Dice系数很熟悉,它的计算和IoU交并比比较类似,其他Loss理解不深,还需进一步补充、学习。
Dice Loss/IoU/F1 Score


前文提到,医学图像分割有时面临前景所占很少比例,背景占比很大的情况,因此前人针对此问题进行了一系列优化;
优化3:带正则化项的交叉熵损失
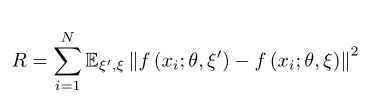
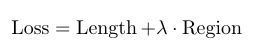
Section V医学图像生成
众所周知CNN模型性能严重依赖于训练的数据量,但鉴于难以获取大规模医学图像数据集,不可避免要对有限的训练数据通过几何变换等进行数据扩增;自从GANs的提出,自然而然想到图像生成的方式来扩充训练数据。目前已有的尝试有:
通过CGAN生成心室的MR图像和CT图像来扩充数据;
EssNet中则是通过CT图合成MR图最终用于CT图的分割;
还有用来合成多器官的X-Ray图像等。
Section VI 弱监督模型
获取像素级别的标注信息费时费力,若能基于未标注的图像或部分标注的图像进行无监督/弱监督的学习更符合实际需求。目前做的尝试有:
通过在损失函数中增加一项对弱监督数据的区分项,在降低计算复杂度的同时还能保持分割精度;
仅使用bounding-box级的监督信息进行训练;
仅使用image-level的信息输出分割结果mask;
借助ADMM,教师-学生模型等进行域迁移达到弱监督学习的效果。
Section VII 多任务模型
同时学习多个任务,并且每一个任务都保持一定精度的多任务学习更符合实际应用。目前的研究进展有: 通过将不同loss联合在一起同时完成building和aerial的分割; VGG16+global average pooling+FCN同时完成病人检测+皮肤分割任务; 改进的UNet模型同时完成胸部CT分割及分类任务; Mask R-CNN是基于Faster R-CNN借助图像label和bbox完成mask的预测。 在医学图像分割的多任务主要完成多类别的分割任务、不同组织、器官的标注等。
Summary
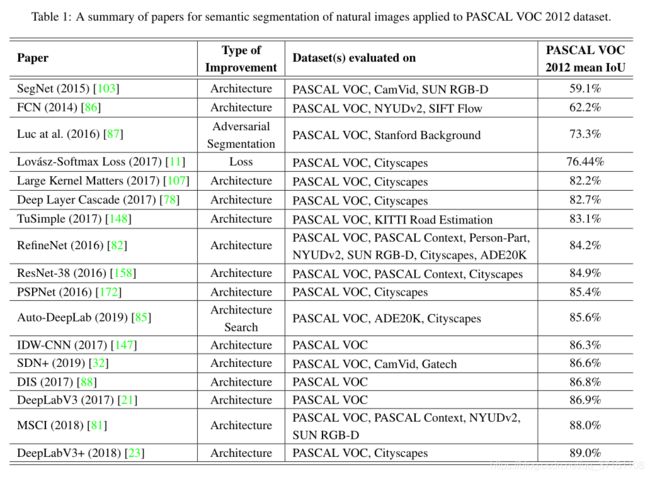
Table 1总结了典型的分割网络及其优化,主要的测试数据集为PASCAL VOC 2012,评价指标为IoU。
 通过以上综述也可以看出医学图像分割的一些限制或者说难点问题:
通过以上综述也可以看出医学图像分割的一些限制或者说难点问题:
(1)医学图像大多维度很高,不适合直接塞到GPU里,通常需要切片、切patch等操作,这就导致无法有效利用空间信息;
(2)由于医学成像系统的独特性,经常产生一些和自然图像不一样的噪声,处理起来比较麻烦,有的甚至不好去除;
(3)医学图像难以获取大型数据集,因此半监督、弱监督网络更具临床应用价值;
(4)借助先验知识辅助分割更适合用于医学图像分割。
Potential Directions
UNet Architecture
在医学图像分割领域主流的分割模型还是基于编解码结构结合skip connection的UNet系列框架,skip connection可以有效解决梯度消失和前层信息传递的问题;结合空间金字塔、空洞卷积等可进一步控制前层信息的传递特性。
Sequence Models
医学图像分割由于涉及到大量3D图像因此不可避免要借助时序模型辅助处理,但在切slice过程中不可避免会损失空间几何特征,未来需进一步探索如何序列处理volumetric数据。
Loss Functions
传统的loss有基于重叠的、基于距离的损失函数,需要解决的是如何在深层网络中消除梯度消失问题;
以及像NAS一样如何自动搜索最佳的损失函数。
其他的一些方向还有:
Non-Medical pre-trained model多模态分割模型。由于医学图像种类繁多,如MRI,PET,CT,X-Ray以及每种都不好获取,很难找到一种one-for-all的有效的分割模型,因此考虑是否可以借助一些非医学图像类的预训练模型辅助医学分割模型的学习。
大型开源数据集。争取开源更多的大规模2D/3D医学图像分割数据集,医学数据集实在是太宝贵了啊。
Reinforcement Learning像条件随机场(CRF)这种将增强学习应用到医学图像分割中;借助少量标签数据和大量无标注的弱监督模型。
FP Analysis对一些模型假阳性分类失败的原因分析。
以上。