Self-training for end-to-end speech recognition
目录
- ABSTRACT
- 1. INTRODUCTION
- 3. SEMI-SUPERVISED SELF-TRAINING
-
- 3.1. Filtering
- 3.2. Ensembles
- 4. EXPERIMENTS
-
- data
- 4.2. Experimental Setting
- 4.3. Results
-
- 4.3.1 Supervised Baseline
- 4.3.2 Evaluating Beam Search
- 4.3.3 Comparing Ensembles
- 4.3.4. Summary
- 4.4. Analyses
-
- 4.4.1 Importance of Filtering
- 4.4.2. Importance of the LM
- 5. RELATED WORK
- 6. DISCUSSION
ABSTRACT
我们在端到端语音识别的背景下重新进行自我训练。 我们证明利用伪标签进行训练可以通过利用未标记的数据来大大提高基线模型的准确性。 我们方法的关键是用于生成伪标签的强大基线声学和语言模型,健壮且稳定的波束搜索解码器以及用于增加伪标签多样性的新颖合奏方法。 在LibriSpeech语料库上进行的实验表明,使用单一模型进行自我训练,与在100小时标记数据上训练的基线相比,在干净数据上可以产生21%的相对WER改善。 我们还评估了标签过滤方法,以提高伪标签质量。 通过将六个模型集成在一起并结合标签过滤,自我训练可产生26%的相对改进,并弥合基线与使用所有标签训练的oracle模型之间的55.6%的差距。
1. INTRODUCTION
建立自动语音识别(ASR)系统需要大量转录的训练数据。 与混合模型相比,端到端模型的性能似乎会更加严重地降低可用训练数据的数量[1]。 录制大量音频既昂贵又费时,因此需要能够从大量未配对的音频和文本数据中学习更多的算法。 已经提出了许多半监督训练方法来利用这种未配对的数据。 一种这样的方法,自我训练,使用从在小得多的标记数据集上训练的模型生成的噪声标记。
我们在注意序列到序列模型的情况下重新讨论自训练[2,3]。 我们展示了LibriSpeech上的自我培训的相对收益,LibriSpeech是公开可用的阅读语音语料库,无需使用外部培训的语言模型。 使用在大型文本语料库上训练过的LM,自我训练可使WER相对于纯净测试集提高26%,相对于嘈杂测试集提高21%。
我们的自训练算法的三个关键组成部分是:(1)在小的配对数据集上训练的强大基线声学模型;(2)用于序列对序列模型的强大而高效的波束搜索解码器,可有效利用 外部训练的神经语言模型和(3)一种新颖的整体自训练方法,可提高标签的多样性。 我们的基准监督模型仅接受了100个小时的干净数据训练,在干净测试集上的WER为8.06%,这是端到端设置中文献中报道得最好的结果。 结合自我训练,我们的模型在干净的测试集上实现了5.93%的WER,仅比460小时干净的语音中对所有可用标签进行了训练的oracle实验仅差1.7%
我们还评估了两种针对伪标签过滤的方法[4],这些方法是针对序列到序列模型经常遇到的错误而量身定制的,并展示了它们对伪标签和模型质量的影响。 最后,我们对自训练算法的重要组成部分的重要性进行了全面的实证评估。 特别是,我们研究使用的语言模型,过滤功能中的机制以及集合中的模型数量。 在实践中,可用于语言模型训练的文本可能与声学成绩单的分布不匹配。 我们通过观察WER作为用于生成伪标签的语言模型的困惑程度的函数,来洞悉这种潜在的不匹配。
3. SEMI-SUPERVISED SELF-TRAINING
在半监督的情况下,我们有一个未配对的数据集,除了配对的数据集D外,它还由未标记的话语X和文本数据集Y组成。 假设|x|>> n及| Y | ≫ n。
为了进行自我训练,我们首先通过最大化方程式8中的目标,在配对数据集D上引导声学模型PAM。我们还在Y上训练语言模型PLM。然后,我们使用声学模型和语言模型来生成一个 通过求解等式6,为每个未标记的示例X∈X伪标记。这为我们提供了一个伪配对数据集D¯= {(Xi,Y¯i)| Xi∈X}。 然后,我们以目标D和D的均等加权级联训练新的声学模型
3.1. Filtering
伪标记的数据集D′包含嘈杂的转录。 在D的大小(越大越好)和伪标签中的噪声之间取得适当的平衡可以使自训练更有效。 我们设计了一种特定于序列到序列模型的简单的基于启发式的过滤功能。 过滤功能可在保留大部分伪标记的同时,以较高的查全率删除最嘈杂的转录。
众所周知,序列到序列模型在推理上会以两种方式灾难性地失败:(1)注意会循环,导致长输出;(2)模型可以太早预测EOS令牌,从而导致输出过短[10]。
通过删除包含重复超过c次的n-gram的示例,我们对第一个失败情况进行了过滤。 这里的n和c是我们根据标记的开发集调整的超参数。 如第2.1节所述,我们试图通过仅保持EOS概率高于指定阈值的假设来处理第二种失败情况。 但是,有时波束搜索会终止而没有找到以EOS结尾的任何假设。 我们过滤所有这些示例。
此外,对于每个伪标签,我们基于从声学模型分配给标签的条件似然来计算置信度得分。 对于某些伪标记的话语(Xi,Y¯i)∈D¯,我们计算该样本的长度归一化对数似然为
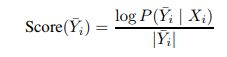
|Y¯i | 是句子中的token数量。 可以将上述过滤方法进行组合和调整
3.2. Ensembles
我们提出并评估了两种方法来集成自启动模型。 我们首先训练通过使用不同种子生成的具有不同初始权重的M模型进行随机初始化
在第一种方法(样本集合)中,我们分别为每个模型生成一个伪标记的数据集Dm。 然后,我们将所有M组伪标签与权重均匀地结合在一起,并在训练过程中优化以下目标
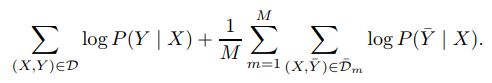
在实现中,我们将一个epoch视为配对数据集D和未配对音频X的完整传递。对于每个X∈X,我们从M个模型之一作为目标统一采样伪标签。
第二种方法是解码集合,在推理过程中根据修改后的目标,使用所有M个模型来生成单个伪标记的数据集

在波束搜索期间,我们在每个步骤中平均所有M个声学模型的得分。 我们获得单个伪标记的数据集D′,并按照等式9中的目标训练模型。
4. EXPERIMENTS
data
所有实验都是在可公开获得的LibriSpeech有声读物语料库上进行的[11]。我们使用“ train-clean100”集作为配对的数据集,该数据集包含大约100个小时的干净语音。未标记的音频数据集由“ trainclean-360”中的话语组成的360小时清晰语音组成。我们报告标准开发人员的结果,并测试干净/其他(嘈杂)设置。
与LibriSpeech一起使用的标准语言模型培训文本是从14,476张公共领域的书中得出的。选择书籍时应确保与开发集和测试集没有重叠[11]。另一方面,训练数据集的转录几乎完全包含在LM训练文本中,这可能导致对自我训练的评估不切实际。为了使学习问题更切合实际,我们从语言模型训练数据中删除了用于生成声学训练数据的所有书籍。这导致从LM训练语料库中删除了997本书。
我们采取一些简单的步骤来预处理和规范化用于LM训练的结果文本语料库。首先,我们使用在NLTK [13]中实现的“ punkt”标记器[12]检测句子边界。我们通过将所有内容都转换为小写并删除标点符号(收缩中的撇号除外)来规范化文本(我们将连字符替换为空格)。与原始的LM语料库[11]不同,我们没有采取任何步骤以规范的语言形式替换非标准词。但是,我们发现,在dev clean和其他转录版本上测得,在这个新语料库上训练的LM与在标准文本语料库上训练的LM相比具有类似的困惑。
4.2. Experimental Setting
我们的序列到序列模型由三个一组的九个TDS块组成。在每个组之前,我们应用步幅为2的标准1D卷积,以降低编码器的帧速率。 TDS组分别包含10、14和16个通道,所有通道的内核宽度均为21。所有其他架构细节与[8]相同。我们仅使用“ train-clean-100”作为训练数据,即可预测使用SentencePiece工具包[14]生成的5,000个子词目标。
在优化过程中,我们使用软窗口(σ= 4)预训练三个时期[8]。除了20%的辍学率之外,我们还使用1%的统一目标抽样,10%的标签平滑度[15]和1%的词条抽样[16]来对模型进行正则化,除强制教师外。在训练“ train-clean-100”时,我们使用批处理大小为16的单个GPU。我们使用无动量的SGD进行200个时期,学习速率为5e-2,每40个时期退火两次。 。对于在较大的伪标记数据集上进行的所有实验训练,我们使用8个GPU,每个GPU的批处理大小为16,并以每80个时代2的系数对学习速率进行退火;其架构和参数与“ trainclean-100”基准中的相同。所有实验均在wav2letter ++框架中进行[17]。
在使用声学和语言模型的任何新组合生成伪标签之前,我们在开发集上优化波束搜索超参数,包括语言模型权重和EOS阈值参数(公式7)。我们使用与[19]相同的模型架构和训练方法,在第4.1节中描述的文本数据集上训练了词卷积卷积LM(ConvLM)[18]。在以下实验中,除非另有说明,否则我们将启发式过滤应用于c = 2和n = 4(第3.1节)。
当在包含配对和伪标记数据的数据集上训练模型时,我们从随机初始化开始,然后对组合的数据集进行训练。我们观察到,与从以配对“ train-clean-100”话语训练的模型开始并根据伪标记数据进行微调相比,这会产生更好的结果。虽然这两种技术都能产生改进,但从随机初始化开始始终会更好
4.3. Results
4.3.1 Supervised Baseline
半监督ASR的常见设置是使用LibriSpeech的“ trainclean-100”子集作为标记的数据集[20,21]。 表1显示了我们在“ train-clean-100”的监督基线下得到的WER,以及来自文献的其他一些结果。 林等。 [21]使用基于BiLSTM编码器和基于位置的注意的序列到序列模型。 他们在“ train-clean-100”上训练他们的模型,以此作为反向翻译样式方法的基准。 刘等。 [20]用CTC损失增强了序列到序列模型。 与这两者相比,我们在干净开发和测试集上的基准WER相对降低了30%以上

另一方面,L¨uscher等。 [1]使用[22]中提出的序列到序列模型,据我们所知,当限于“ train-clean-100”时,可以产生最佳的先验结果。 与此相比,我们的TDS基准模型在开发集上具有更好的WER,并且具有相似的测试WER。 我们认为,对于半监督实验,我们的监督基准是一个具有挑战性但实用的起点。 此基准使我们能够更有意义地展示添加其他未标记的音频或文本数据所带来的改进。
4.3.2 Evaluating Beam Search
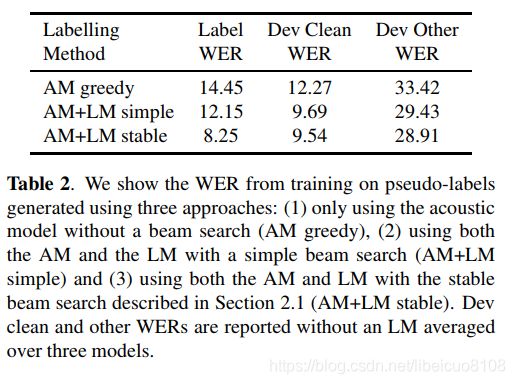
为了研究稳定波束搜索的重要性,我们在另外两个条件下评估了自我训练。 首先,我们与仅从声学模型的贪婪输出生成的伪标签进行比较。 我们在“ train-clean-360”上使用监督的基线模型执行贪婪解码,以生成伪标签。 其次,我们将比较使用语言模型但没有EOS阈值和第2.1节中描述的注意力高度限制的简单波束搜索生成的伪标签。
对于每种设置,我们在表2中训练三个模型并报告平均WER,而没有外部LM。我们还将伪标签与“ train-clean-360”的真实转录进行比较,并计算标签WER作为标签质量。我们可以在表2中看到,在简单的波束搜索中使用LM可以提高伪标签的质量,从而提高训练模型的质量。稳定的波束搜索进一步提高了伪标签质量,以及使用这些标签训练的模型的结果WER。
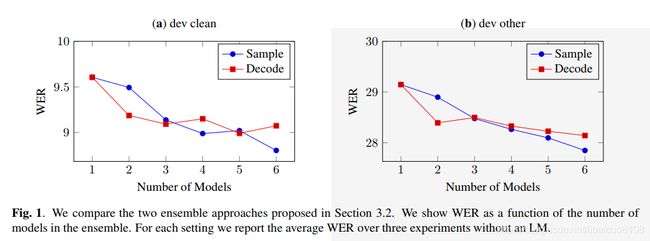
4.3.3 Comparing Ensembles
图1比较了干净开发集和其他开发集上的两种集成方法。 样本集合在两个集合上的WER增益都比解码集合大。 一种可能的解释是,由于样本集合在训练时对同一样本使用了不同的转录本。 这可以防止模型对嘈杂的伪标签过分自信。 通常,合奏中的模型应该倾向于在不正确的抄写上更多地达成一致,并在正确的抄写上更多地达成一致。
4.3.4. Summary
表3总结了在强监督基线,稳定光束搜索和样本集合的情况下我们的最佳结果。 我们还使用LM解码每个模型,以展示自训练方法的全部潜力。
从表3中我们可以看到,与监督基线相比,即使是基本的伪标记方法,在使用LM解码后,干净测试集的相对改进也达到21.2%,其他测试集的相对改进达到20.7%。 通过使用六个模型的样本集成方法,我们看到干净测试集的进一步相对改进为6.6%。
为了了解自我训练的局限性,我们还评估了一个Oracle模型,该模型可以访问“ train-clean-100”和“ train-clean-360”中的真实标签。 表3显示,最佳伪标签模型弥合了仅在“ train-clean100”上训练的监督基线与在干净测试集上测量的oracle模型之间的55.6%的差距。

4.4. Analyses
4.4.1 Importance of Filtering
表4显示了通过基线模型在“ train-clean-360”上生成的伪标签具有各种过滤功能的结果。所有WER结果均为三个模型的平均值,均使用带有ConvLM的相同波束搜索解码过程。我们评估了“无EOS + n-gram”滤波器和声学模型得分阈值,不包括最差的第10个百分点的样本。在干净的环境中,我们观察到“无EOS + n-gram”过滤器可改善干净的和其他显影设备的WER。伪标签的质量使得根据声学模型得分删除最差的十分之一样本可以提高性能,但是按照此标准删除数据的倒数第二十分之多会从训练集中删除太多数据。这些过滤技术的最佳组合首先应用“ no EOS + n-gram”过滤器,然后根据其得分从结果集中删除样本的最低第10个百分点。这样,“干净”开发套件和“其他”开发套件的相对WER分别降低了5%和8%。

4.4.2. Importance of the LM
我们通过使用具有不同困惑度的LM生成的伪标签训练多个模型来检验LM的影响,这些伪标签对开发人员集具有重要意义。 我们通过训练模型的可变数量的步骤来控制LM的困惑。 对于每个伪标签集,我们训练三个模型并报告平均WER,而无需使用LM进行解码。
在图2中,我们显示了通过对具有不同LM困惑度的伪标签进行自我训练而减少了WER。 我们可以看到一个明显的趋势,即当LM困惑度降低时,开发集上的WER也会降低。 换句话说,更好的LM可以为自训练提供更好的模型性能。 在表2中,我们表明不使用任何语言模型来生成伪标签(AM Greedy),在dev clean上的WER为12.27,在其他dev上的WER为33.42。 与图2相比,很明显,即使使用更高的困惑度的LM也可以提高自我训练的效率。 我们看到LM困惑度的上限为180,其中伪标签的质量开始比没有外部LM时可获得的伪劣,从而导致自训练的模型性能变差。

5. RELATED WORK
自我训练已应用于自然语言处理中的任务,包括单词义消歧[2],名词识别[23]和解析[3],以及计算机视觉中的任务(例如对象检测[24、25]和图像)分类[26]。在自动语音识别中,自训练式方法已在基于对齐的混合语音系统中取得了一些成功。先前的工作主要集中在不同的数据过滤方法上,以提高伪标签的质量。基于置信度的过滤[27、28、29]和基于 agreement based
selection[30],它们也利用了来自多个系统的输出,并且数据选择过程可以在从帧到发声[31、32]的不同级别上进行。在混合数据系统中使用伪标签还可以改善大规模数据集的WER [33],而在另一种情况下,在没有发布未配对音频的情况下进行培训时,无需外部LM的学生-教师方法也可以改善[34]。 。然而,在这两种情况下,非公开数据的使用都使得方法的再现和直接比较变得困难。因此,这项工作的一个目标是提供一种可重现的配方,以改善带有伪标签的ASR性能,同时提供一种标准的,可公开获得的基准,自动语音识别中的其他半监督方法可以与之相比。最近提出的端到端语音识别的半监督方法已经应用了类似于反向翻译的技术[35]。这些使用不成对的文本来生成合成数据集,但是直接针对隐藏状态表示而不是声学特征[21]。或者,可以通过将未配对的音频和文本嵌入到共享表示中来使用它们[36]。在具有端到端模型的半监督ASR中,先前的工作往往是基于弱或微调的监督基线模型构建的,这是半监督学习普遍存在的普遍问题[37]。相比之下,我们将自我训练的模型与经过良好调整的基准模型进行比较,该模型优于在相同数据集上训练的先前结果
6. DISCUSSION
我们已经证明,通过利用大量未标记的数据集,自我训练可以在强大的基线模型上为端到端系统带来实质性的改进。自我训练已经在其他应用领域中得到了很好的研究,但是尚未在深度神经网络的端到端语音识别中进行过仔细的研究。我们假设这些模型的鲁棒性与在配对数据集上训练的强大基线模型相结合,可以使自训练更加有效。此外,我们表明,针对序列序列模型遇到的错误类型量身定制的过滤机制以及基线模型的集成可以进一步提高自训练的准确性。
这项研究的局限性在于我们进行实验的数据集LibriSpeech完全由朗读语音组成。这不是一个完全实用的设置,因为用于训练语言模型的书籍的分布与声学训练数据中的转录的分布非常匹配。我们会非常小心地删除两个数据集之间的确切重叠,以使问题设置更加实际。但是,未来的工作应该检查噪声更大,匹配程度较差的未标记语音和文本。
改进半监督学习方法的主轴之一是数据规模。我们期望通过不断扩大未标记的音频和文本语料库的规模,自我培训可以在LibriSpeech和其他地方带来更大的进步。除了演示LibriSpeech上自我训练的有效性外,我们还建立了一个强大的基线模型和可重现的半监督学习环境,可以评估新方法和现有方法。我们希望这有助于加速语音识别这一研究领域的发展