【深度学习笔记整理-4.1】如何避免过拟合?
其实神经网络训练的过程就是一个欠拟合与过拟合拉锯的过程,一方面,我们希望我们的网络可以比较好的拟合训练数据,另一方面,我们又不希望它学习的那么好,以至于最终只是记忆住了全部答案。
解决过拟合的问题非常重要,一般有如下四种方法:
1.增加训练数据数量
模型的训练数据越多,泛化能力自然也越好。这是因为更多的数据可以给我们找到更一般的模式。如果无法获取更多数据,次优解决方法是调节模型允许存储的信息量,或对模型允许存储的信息加以约束。如果一个网络只能记住几个模式,那么优化过程会迫使模型集中学习最重要的模式,这样更可能得到良好的泛化。这就是方法二:
2.减小网络大小
正如文章开头所说,过大的网络模型虽然在训练集上效果很好,但是它有可能仅仅只是记住了全部的答案,如果我们减少了网络参数的数量,其记忆资源有限,无法轻松学到输入值到目标值的映射,就必须学会对目标具有很强预测能力的压缩表示,但是我们也要给足够的参数以防欠拟合,选择一个折中的结果作为我们网络的大小。
网络的大小是超参数,目前无法通过计算得出,比较好的方法是先从小的神经网络开始,然后逐步扩大网络,在扩大网络的过程中要监视网络大小对效果的影响,当网络增加到一定程度,大小对验证集的影响不那么大了以后,我们就停止扩大我们的神经网络。
3.添加权重正则化
我们应该听过奥卡姆剃刀原理:如果一件事情有两种解释,那么最可能正确的解释就是最简单的那个,即假设更少的那个。这个原理也适用于神经网络学到的模型:给定一些训练数据和一种网络架构,很多组权重值(即很多模型)都可以解释这些数据。简单模型比复杂模型更不容易过拟合。
这里的简单模型是指参数值分布的熵更小的模型(所谓的熵更小,指的是参数值的分布不会有大的波动,比较规则)或参数更少的模型。因此,一种常见的降低过拟合的方法就是强制让模型权重只能取较小的值,从而限制模型的复杂度,这使得权重值的分布更加规则,这种方法叫作权重正则化。
这种正则化是向损失函数中添加与较大权重值相关的损失,有以下两种形式:
①L1正则化
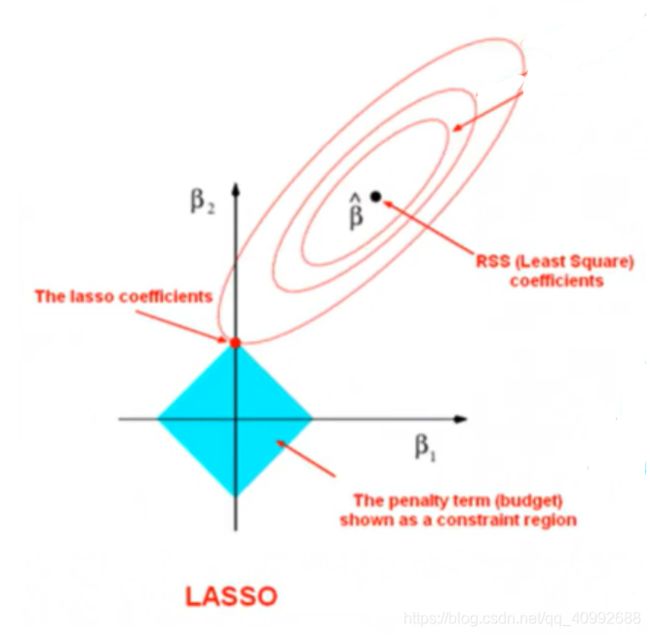
l1正则化会在损失函数中添加权重系数的绝对值之和,回归问题使用l1也被称之为Lasso回归,其从某方面理解就是在梯度下降的过程中将参数限制在了一个边缘尖锐的空间中(二维空间中就是个矩形),在这个空间中离损失最低点的权重参数往往在边缘顶点,导致部分权重参数的值是0,也就是所谓的“稀疏性”。
使用l1的好处在于,一方面由于它的特性可以帮助我们筛选出有用的特征,另一方面其鲁棒性较好,损失函数在一定程度的变化范围内不会影响到权重系数最优点的改变,但是坏处在于,当损失函数变化超过一定限度,最优权重系数会有非常大的变化。
①L2正则化
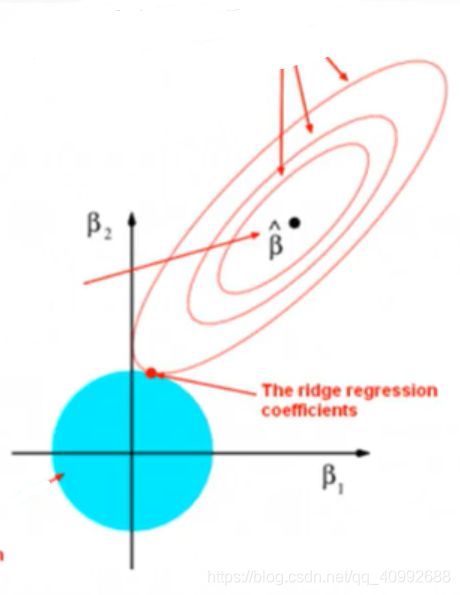
l2正则化会在损失函数中添加权重系数的平方之和,回归问题使用l2也被称之为Ridge回归(岭回归),其在梯度下降的过程中将参数限制在了一个边缘平滑的空间中(二维空间中就是个圆形),不同于l1回归,使用了l2的最优点各维度往往都不是0,也就没有所谓的稀疏性。
keras代码如下:
from keras import regularizers,models,layers
network = models.Squential()
network.add(layers.Dense(64,activation='relu',kernel_regularizer=regularizers.l2(0.001),input_shape=(10000,)))
#括号中设定lambda的值
network.add(layers.Dense(32,activation='relu',kernel_regularizer=regularizers.l2(0.001)))
network.add(layers.Dense(1,activation='sigmoid'))
有些情况我们若想l1,l2正则都使用,可以使用l1_l2(l1=a,l2=b)即可。
4.dropout
dropout会在每一次参数迭代的过程中每一层随机删除一定比率的神经元。其同样会减少神经网络的大小,但是被删除的神经元可能会在下一次的迭代中被利用到,在每一次迭代的过程中,会生成不同的神经网络模型,有点类似模型的集成。

dropout作为一层单独存在,其实现起来比较简单,本质就是将层输出乘上一个随机生成的0,1向量,如50%的dropout代码如下:
layer_out *= np.randint(0,high=2,size=layer_out.shape)训练时删除了一半的神经元,迫使每一层神经元的输出变为原来的2倍,但是测试时我们是不会删除神经元的,就要将每一层的输出变为原来的一半。
layer_out *= 0.5当然,我们也可以不这么麻烦,直接在训练集输出的参数除以2即可,测试集就不用动了。
layer_out *= np.randint(0,high=2,size=layer_out.shape)
layer_out *= 0.5在keras中,增加dropout层非常容易
net_work.add(layers.Dropout(0.5))