数学建模算法学习笔记
数学建模算法学习笔记
作为建模Man学习数学建模时做的笔记
参考文献:
《数学建模姜启源第四版》
网上搜罗来的各种资料,侵删
1.线性预测
levinson durbin算法,自相关什么的,搞不懂
https://max.book118.com/html/2018/1231/8056037133001142.shtm
统计检验量R2(决定系数,接近1为最好)、F(方差统计量,越大越好,R2=1时为无穷,要求远大于临界值,临界值与置信概率α有关,具体查表)、p(p=0.05表示拟合关系有5%是由偶然造成的)、s2(方差)是啥
1.1 简单的线性拟合
- 找出因变量y和所有自变量x
- 分析各个自变量对y的图像,决定影响关系是什么函数,然后将其加起来,得到拟合方程,例如下面这个
y = β 0 + β 1 x 1 + β 2 x 2 + β 3 x 2 2 + ε y = β_0+β_1x_1+β_2x_2+β_3x_2^2+ε y=β0+β1x1+β2x2+β3x22+ε
ε指随机误差(在计算模型参数的时候一般是忽略的,因为如果模型取得好,随机误差是很小的,满足均值为0的正态分布)
- 直接用Matlab求出参数的值
- 检查参数置信区间,如果有包含0的,说明不合理,需要改进
- 使用残差分析,检查每个自变量与残差的图像分布,结合经验找出需要添加的结合项 x i x j x_ix_j xixj,添加到拟合方程中
- 重复以上步骤,直到结果令人满意
- 如果出现不合理的数据,需要去除
1.2 简单的指数拟合
指数规律有以下两种模型
- Michaelis-Menten模型
y = f ( x , β ) = β 1 x β 2 + x y = f(x,β)=\frac{β_1x}{β_2+x} y=f(x,β)=β2+xβ1x
- 指数增长模型
y = f ( x , β ) = β 1 ( 1 − e − β 2 x ) y = f(x,β) = β_1(1-e^{-β_2x}) y=f(x,β)=β1(1−e−β2x)
其实可以用线性化将非线性模型化为线性模型进行处理,但没必要,详见书本P339
定好模型后直接用matlab算就好
对于模型1来说 β 1 β_1 β1指曲线趋近值, β 2 β_2 β2指曲线y一半时对应的x值
此外也可以引入0-1变量建混合模型,例如
y = f ( x , β ) = ( β 1 + γ 1 x 2 ) x 1 ( β 2 + γ 2 x 2 ) + x 1 y = f(x,β) = \frac{(β_1+γ_1x_2)x_1}{(β_2+γ_2x_2)+x_1} y=f(x,β)=(β2+γ2x2)+x1(β1+γ1x2)x1
指数模型的判定看的是标准差,R2和s依然可用
改善可看书本P345
1.3 数据自相关
一般按时间序列进行采样的数据都可能会自相关,即前面的数据会对后面的数据有影响。所以对这类数据,先按正常进程进行建模,然后要对自相关性进行诊断,以此决定是否需要对模型进行改进
自相关在模型中一般在随机误差 ε t ε_t εt中表示,如果存在自相关性,则 ε t ε_t εt可如下表示
ε t = ρ ε t − 1 + u t ε_t = ρε_{t-1}+u_t εt=ρεt−1+ut
- 粗看残差之差
将正常建模的残差之差 e t − e t − 1 e_t-e_{t-1} et−et−1散点图画出,如果能看出是分布于一三象限或者二四象限,则说明具有自相关性
- Durbin-Watson检验(D-W检验)
首先得到残差计算DW统计量
D W = ∑ i = 2 n ( e t − e t − 1 ) 2 ∑ i = 2 n e t 2 DW=\frac{\sum\limits_{i=2}^{n}(e_t-e_{t-1})^2}{\sum\limits_{i=2}^ne_t^2} DW=i=2∑net2i=2∑n(et−et−1)2
当n较大时,可做如下近似
D W ≈ 2 ( 1 − ∑ i = 2 n e t e t − 1 ∑ i = 2 n e t 2 ) DW \approx 2(1-\frac{\sum\limits_{i=2}^ne_te_{t-1}}{\sum\limits_{i=2}^{n}e_t^2}) DW≈2(1−i=2∑net2i=2∑netet−1)
∑ i = 2 n e t e t − 1 ∑ i = 2 n e t 2 \frac{\sum_{i=2}^ne_te_{t-1}}{\sum_{i=2}^{n}e_t^2} ∑i=2net2∑i=2netet−1这个为自相关系数 ρ ρ ρ的估计值 ρ ^ \hatρ ρ^,所以
D W ≈ 2 ( 1 − ρ ^ ) DW \approx 2(1-\hat{ρ}) DW≈2(1−ρ^)
当算出了DW值之后,就要根据样本容量n和模型的变量数K查D-W分布表,得到 d l d_l dl和 d u d_u du的值
https://blog.csdn.net/no1stevewang/article/details/50237049
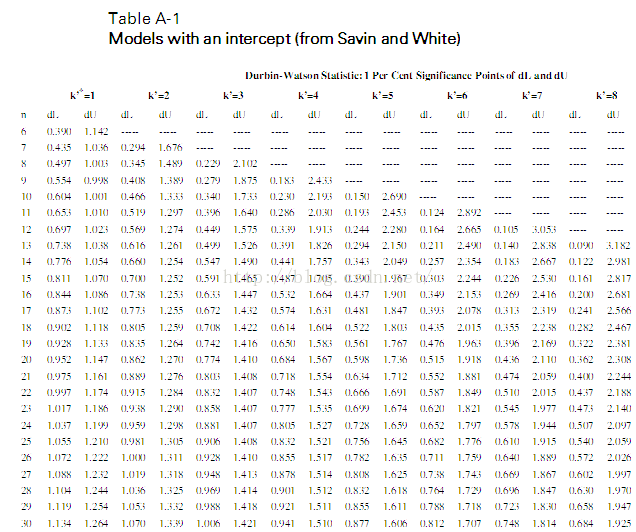
最后根据下图确定 ε t ε_t εt是否自相关

当我们确定存在自相关性之后,可将 ρ ^ \hat{ρ} ρ^表示如下
ρ ^ = 1 − D W 2 \hat{ρ} = 1-\frac{DW}{2} ρ^=1−2DW
之后做变换(广义差分变换)
y t ∗ = y t − ρ y t − 1 y_t^* = y_t-ρy_{t-1} yt∗=yt−ρyt−1
x t ∗ = x t − ρ x t − 1 x_t^* = x_t-ρx_{t-1} xt∗=xt−ρxt−1
β 0 ∗ = β 0 ( 1 − ρ ) β_0^*=β_0(1-ρ) β0∗=β0(1−ρ)
就能得到新的,已经考虑了自相关的模型如下(一阶自相关模型)
y t ∗ = β 0 ∗ + β 1 x 1 t ∗ + β 2 x 2 t ∗ + μ t y_t^*=β^*_0+β_1x_{1t}^*+β_2x_{2t}^*+μ_t yt∗=β0∗+β1x1t∗+β2x2t∗+μt
μ t μ_t μt是和一般的 ε ε ε一样的随机误差
然后用matlab算这个新的模型就好
算完之后再进行一次自相关性检验,如果还有问题,就再来一遍(可能有其他处理办法)
最后将新模型用上面那个变换换回来,用不带*的符号表示即可
如果DW落在无法确定自相关性的区间,可以设法增加数据量,或者换其他方法
1.4 逐步回归
逐步回归是一种从众多自变量中选取重要变量(对因变量影响大)的方法
matlab有工具可用,原理略
1.5 Y为多分类的情况
例如书本上的冠心病模型,用 π ( x ) \pi(x) π(x)表示在年龄x下患冠心病概率
π ( x ) = P ( Y = 1 ∣ x ) \pi(x)=P(Y=1|x) π(x)=P(Y=1∣x)
因为从图像可得 π ( x ) \pi(x) π(x)类似于S型曲线,所以采用logit(logistic)模型进行拟合
π ( x ) = e β 0 + β 1 x 1 + e β 0 + β 1 x \pi(x) = \frac{e^{β_0+β_1x}}{1+e^{β_0+β_1x}} π(x)=1+eβ0+β1xeβ0+β1x
先写出反函数
l n π ( x ) 1 − π ( x ) = β 0 + β 1 x ln\frac{\pi(x)}{1-\pi(x)}=β_0+β_1x ln1−π(x)π(x)=β0+β1x
左边这一块就是logit模型了 l o g i t ( π ( x ) ) = l n π ( x ) 1 − π ( x ) logit(\pi(x))=ln\frac{\pi(x)}{1-\pi(x)} logit(π(x))=ln1−π(x)π(x),当 π ( x ) \pi(x) π(x)在[0,1]取值时, l o g i t ( π ( x ) ) logit(\pi(x)) logit(π(x))的取值为 ( − ∞ , + ∞ ) (-\infty,+\infty) (−∞,+∞),能弥补线性模型算出来概率超过1的缺点
这个时候,只需要根据数据算出每个x对应的 π ( x ) \pi(x) π(x),再求出两个参数 β 0 β_0 β0和 β 1 β_1 β1即可
扔进matlab算就好
可以考虑在右边加入 x 2 x^2 x2项,可能可以增加准确度,算出来看p值的变化,变小则更好,否则不用加这一项
处理这种问题还有另一种模型,为probit模型,差不多,详见P363
当变量不止一个时,详见P365
2. 数据预处理
- 移动平均滤波:用于减少随机干扰对数据采集的影响


此外还要加权移动滤波

- 快速傅里叶变换(FFT):用于检测得到的数据中是否有高频噪声,以决定是否使用FIR滤波

使用对数坐标图会使现象更明显
- 多分类Y
例如冠心病模型中,Y只有1(患病)和0(不患病)的情况,这个时候很难直接建模。所以可以采用分组法,将每一个年龄段的1的概率作为新的Y进行建模
3. 元胞自动机
暂略,让程序负责
4.模糊综合评价
这是一个比较主观的用于判断一个事物好坏的方法
以下参考:https://www.bilibili.com/video/BV1LK411P7Qv?from=search&seid=11974302579866908995&spm_id_from=333.337.0.0
下面介绍方法的几个概念
- 因素:想要判断方法A好不好,需要找到几个衡量的指标,这些指标叫做因素,集合为因素集
- 评语:评价方法好坏的等级,好,一般,差等等
下面要对因素1进行评价,例如有 α 1 \alpha_1 α1(这里指概率)的人认为方法A有具备这个指标, α 2 \alpha_2 α2的人认为可能有, α 3 \alpha_3 α3的人认为没有,那么可以列出评价矩阵
v 1 = [ α 11 , α 12 , α 13 ] v_1=[\alpha_{11}, \alpha_{12},\alpha_{13}] v1=[α11,α12,α13]
接下来对因素2进行评价,同理得到评价矩阵
v 2 = [ α 21 , α 22 , α 23 ] v_2=[\alpha_{21}, \alpha_{22},\alpha_{23}] v2=[α21,α22,α23]
把这两个拼在一起组成综合评价矩阵
R = [ α 11 α 12 α 13 α 21 α 22 α 23 ] R=\begin{bmatrix} \alpha_{11} &\alpha_{12} &\alpha_{13}\\ \alpha_{21} &\alpha_{22} &\alpha_{23}\\ \end{bmatrix} R=[α11α21α12α22α13α23]
接下来列出因素1和因素2的权重集
A = [ β 1 , β 2 ] A=[\beta_1 ,\beta_2] A=[β1,β2]
(权重和为1)
后面开始计算

得到最终结果
B = [ 0.6 , 0.2 , 0.1 ] B=[0.6,0.2,0.1] B=[0.6,0.2,0.1]
如果相加不为1,同除以和0.9即可
最终得到
B = [ 0.67 , 0.22 , 0.11 ] B=[0.67,0.22,0.11] B=[0.67,0.22,0.11]
取最大的0.67,根据前面指标中概率的排序方式,0.67指的就是评价为好的概率
这时可知为好的概率比较大