java中常见类型的转换以及方法总结
1.char、String、int类型之间的转换
1.1 char和String的区别
- char是表示的是字符,定义的时候用单引号,只能存储一个字符。例如; char=‘d’.
String表示的是字符串,定义的时候用双引号,可以存储一个或者多个字符。例如:String=“we are neuer”。 - char是基本数据类型,而String是个类,属于引用数据类型。String类可以调用方法,具有面向对象的特征
1.2 String转换为char、int、Integer
- String -> char(i) 使用String.charAt(index)(返回值为char)可以得到String中某一指定位置的char。
- String -> char[ ] 使用String.toCharArray()(返回值为char[ ])可以得到将包含整个String的char数组。这样我们就能够使用从0开始的位置索引来访问string中的任意位置的元素。
- String -> int 使用Integer.parseInt(str) 进行转换,返回str所代表的的int值大小。
- String -> Integer 使用Integer.valueOf(str),返回Integer对象。
1.3 char转换为String、int
char -> int 使用 (int) (char-‘0’) 转换,返回值为int值大小
char -> String :有6种方法,如下:
1. String s = String.valueOf('c'); //效率最高的方法
2. String s = String.valueOf(new char[]'c'}); //将一个char数组转换成String
// Character.toString(char)方法实际上直接返回String.valueOf(char)
3. String s = Character.toString('c');
4. String s = new Character('c').toString();
5. String s = "" + 'c';
/*** 虽然这个方法很简单,但这是效率最低的方法
Java中的String Object的值实际上是不可变的,是一个final的变量。
所以我们每次对String做出任何改变,都是初始化了一个全新的String Object并将原来的变量指向了这个String。
而Java对使用+运算符处理String相加进行了方法重载。
字符串直接相加连接实际上调用了如下方法:
new StringBuilder().append("").append('c').toString();
***/
6. String s = new String(new char[]{'c'});
1.4 Int转换为String、Integer、char
//int型 转 String型
String str1=Integer.toString(in); //使用Integer.toString()
String str2=String.valueOf(in); //使用String.valueOf(int i);返回String
String str3 = "" + in; //少用的方式
//int型 转 char型
char cha=(char)(in+'0');
//int型 转 Integer型
Integer integer=new Integer(in);
1.4 String数组转为int数组
String[] strings = {"1", "2", "3"};
//1. 使用stream流
int[] array = Arrays.asList(strings).stream().mapToInt(Integer::parseInt).toArray();
//2. 或
int[] array = Arrays.stream(strings).mapToInt(Integer::parseInt).toArray();
// 3.对String数组中的每一个str进行操作
int[] intarray = new int[strings.length];
int i=0;
for(String str:strings){
intarray[i++]=Integer.parseInt(str);
}
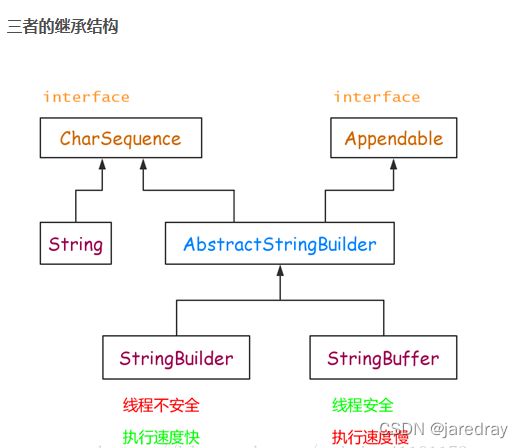
2.String、StringBuffer、StringBuilder的关系
-
当对字符串进行修改的时候,需要使用 StringBuffer 和 StringBuilder 类。
-
与 String 类不同的是,StringBuffer 和 StringBuilder 类的对象能够被多次的修改,并且不产生新的未使用对象。
| String | StringBuffer | StringBuilder |
|---|---|---|
| String的值是不可变的,这就导致每次对String的操作都会生成新的String对象,不仅效率低下,而且浪费大量优先的内存空间 | StringBuffer是可变类,和线程安全的字符串操作类,任何对它指向的字符串的操作都不会产生新的对象。每个StringBuffer对象都有一定的缓冲区容量,当字符串大小没有超过容量时,不会分配新的容量,当字符串大小超过容量时,会自动增加容量 | 可变类,速度更快,线程不安全 |
| 不可变 | 可变 | 可变 |
| / | 线程安全 | 线程不安全 |
| / | 多线程操作字符串 | 单线程操作字符串 |
2.1 String字符串常用操作:
- length():返回字符串长度
- string1.concat(string2):连接字符串string1和string2
- charAt(int index):返回指定索引处的字符
- setCharAt(index,String);将index处的字符替换为String
- endsWith(String s):判断是否以某字符结束
- startsWith(String s):是否以指定前缀开始
- equals(Object s):将字符串与指定对象做比较,是否相等
- indexOf(String s):返回指定字符串在字符串中第一次出现的位置
- split(String s):根据指定的正则表达式匹配拆分字符串,返回字符串数组
- substring(int a,int b):返回从a到b新的字符串
- toCharArray():将字符串转换为字符数组
- trim():去除字符串首尾空格
- contains(char s):判断是否包含指定的字符系列
- isEmpty():判断字符串是否为空
- format(): 用来创建可复用的格式化字符串,而不仅仅是用于一次打印输出。
2.2 StringBuffer字符串/StringBuilder字符串方法:
- append:向序列中追加元素
- reverse:将序列中元素反转
- delete(int start, int end):移除此序列的子字符串中的字符
- deleteCharAt(int a):删除指定下标的字符
- insert(位置,元素):向序列中指定位置插入元素
- replace(int start, int end, String str):用指定的str替换序列中start到end的字符
- capacity():返回当前容量
- int length():返回长度(字符数)
- charAt(int index):返回指定索引处值
- indexOf(String str):返回第一次出现该字符的索引
- int indexOf(String str, int fromIndex):从指定下标开始,返回第一次出现该字符的索引
- int lastIndexOf(String str):返回最右边出现的指定子字符串在此字符串中的索引
- substring(int start, int end):返回一个新的 String,它包含此序列当前所包含的字符子序列
- toString():返回此序列中数据的字符串表示形式
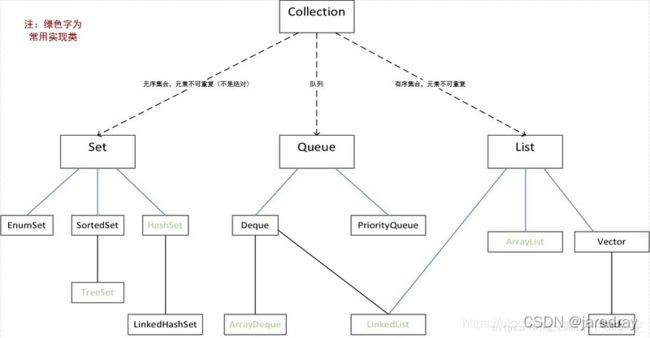
3.List接口类
- List是Java中比较常用的集合类,关于List接口有很多实现类
- List 是一个接口,它继承于Collection的接口。
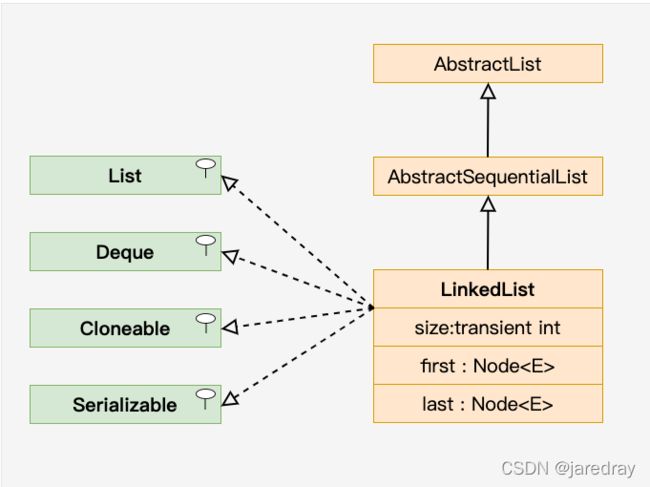
3.1 LinkedList类
- 链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的地址,并且允许所有元素(包括 null)。
- 与 ArrayList 相比,LinkedList 的增加和删除的操作效率更高,而查找和修改的操作效率较低。
以下情况使用 LinkedList :
- 你需要通过循环迭代来访问列表中的某些元素。
- 需要频繁的在列表开头、中间、末尾等位置进行添加和删除元素操作。
/*** 引入 LinkedList 类
LinkedList 继承了 AbstractSequentialList 类。
LinkedList 实现了 Queue 接口,可作为队列使用。
LinkedList 实现了 List 接口,可进行列表的相关操作。
LinkedList 实现了 Deque 接口,可作为队列使用。
LinkedList 实现了 Cloneable 接口,可实现克隆。
LinkedList 实现了 java.io.Serializable 接口,即可支持序列化,能通过序列化去传输。
***/
import java.util.LinkedList;
LinkedList<E> list = new LinkedList<E>(); // 普通创建方法
//或者
LinkedList<E> list = new LinkedList(Collection<? extends E> c); // 使用集合创建链表
常用操作方法:
- padd() / addLast) / offer() / offerLast():在末尾添加元素
- addFirst() / offerFirst():在头部添加元素
- removeFirst():移除头部元素
- remove / removeLast():移除末尾元素
- getFirst():获取头部元素
- get / getLast():获取末尾元素
- poll() :删除并返回第一个元素
- peek():返回第一个元素
- size():返回链表元素个数
更多API方法可查看:https://www.runoob.com/manual/jdk11api/java.base/java/util/LinkedList.html
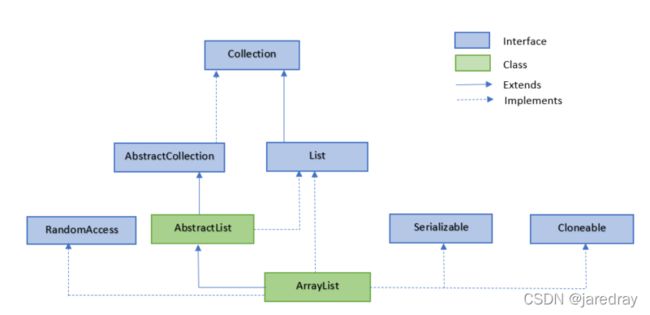
3.2 ArrayList 类
ArrayList 类是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删除元素。ArrayList 继承了 AbstractList ,并实现了 List 接口。ArrayList 是一个数组队列,提供了相关的添加、删除、修改、遍历等功能。
以下情况使用 ArrayList :
- 频繁访问列表中的某一个元素。
- 只需要在列表末尾进行添加和删除元素操作。
// 引入 ArrayList 类
import java.util.ArrayList;
ArrayList<E> objectName =new ArrayList<>(); // 初始化
常用操作方法:
- add():添加元素
- clear():清楚所有元素
- contains():是否包含某个元素
- get():获得某个元素
- indexOf():返回指定值索引
- remove():移除元素
- removeAll():移除所有元素
- size():列表大小
- isEmpty():是否为空
- subList():截取列表
- set():设置值
- sort():排序
- toArray():将 arraylist 转换为数组
- toString():将 arraylist 转换为字符串
- forEach():遍历 arraylist 中每一个元素并执行特定操作
- lastIndexOf():返回指定元素在 arraylist 中最后一次出现的位置
更多 API 方法可以查看https://www.runoob.com/manual/jdk11api/java.base/java/util/ArrayList.html
3.3 Stack类
栈是Vector的一个子类,它实现了一个标准的后进先出的栈。
注意:Java堆栈Stack类已经过时,Java官方推荐使用Deque替代Stack使用。Deque堆栈操作方法:push()、pop()、peek()。
- 该类和ArrayList非常相似,但是该类是同步的,可以用在多线程的情况,该类允许设置默认的增长长度,默认扩容方式为原来的2倍。
常用操作方法:
- empty() :测试栈是否为空
- peek( ):查看堆栈顶部的对象,但不从堆栈中移除它
- pop( ):移除堆栈顶部的对象,并作为此函数的值返回该对象
- push(Object element):把项压入堆栈顶部
- search(Object element):返回对象在堆栈中的位置,以 1 为基数
4.Queue接口类
- Queue是java中实现队列的接口,它总共只有6个方法,我们一般只用其中3个就可以了。Queue的实现类有LinkedList和PriorityQueue。最常用的实现类是LinkedList。
Queue的6个方法分类:
压入元素(添加):add()、offer()
相同:未超出容量,从队尾压入元素,返回压入的那个元素。
区别:在超出容量时,add()方法会对抛出异常,offer()返回false
弹出元素(删除):remove()、poll()
相同:容量大于0的时候,删除并返回队头被删除的那个元素。
区别:在容量为0的时候,remove()会抛出异常,poll()返回false
获取队头元素(不删除):element()、peek()
相同:容量大于0的时候,都返回队头元素。但是不删除。
区别:容量为0的时候,element()会抛出异常,peek()返回null。
4.1 Deque
- Deque是一个双端队列接口,继承自Queue接口,Deque的实现类是LinkedList、ArrayDeque、LinkedBlockingDeque,其中LinkedList是最常用的。
- 特点
1.插入、删除、获取操作支持两种形式:快速失败和返回null或true/false
2.既具有FIFO特点又具有LIFO特点,即是队列又是栈
3.不推荐插入null元素,null作为特定返回值表示队列为空
4.未定义基于元素相等的equals和hashCode
Deque的三种用途
//普通队列(一端进另一端出):
Queue queue = new LinkedList()或Deque deque = new LinkedList()
//双端队列(两端都可进出)
Deque deque = new LinkedList()
//堆栈
Deque deque = new LinkedList()
常用操作方法:
addFirst(): 向队头插入元素,如果元素为空,则发生NPE(空指针异常)
addLast(): 向队尾插入元素,如果为空,则发生NPE
offerFirst(): 向队头插入元素,如果插入成功返回true,否则返回false
offerLast(): 向队尾插入元素,如果插入成功返回true,否则返回false
removeFirst(): 返回并移除队头元素,如果该元素是null,则发生NoSuchElementException
removeLast(): 返回并移除队尾元素,如果该元素是null,则发生NoSuchElementException
pollFirst(): 返回并移除队头元素,如果队列无元素,则返回null
pollLast(): 返回并移除队尾元素,如果队列无元素,则返回null
getFirst(): 获取队头元素但不移除,如果队列无元素,则发生NoSuchElementException
getLast(): 获取队尾元素但不移除,如果队列无元素,则发生NoSuchElementException
peekFirst(): 获取队头元素但不移除,如果队列无元素,则返回null
peekLast(): 获取队尾元素但不移除,如果队列无元素,则返回null
pop(): 弹出栈中元素,也就是返回并移除队头元素,等价于removeFirst(),如果队列无元素,则发生NoSuchElementException
push(): 向栈中压入元素,也就是向队头增加元素,等价于addFirst(),如果元素为null,则发生NPE,如果栈空间受到限制,则发生IllegalStateException
4.2 ArrayDeque类
ArrayDeque是Deque接口的一个实现,使用了可变数组,所以没有容量上的限制。
同时,ArrayDeque是线程不安全的,在没有外部同步的情况下,不能再多线程环境下使用。
ArrayDeque是Deque的实现类,可以作为栈来使用,效率高于Stack;
也可以作为队列来使用,效率高于LinkedList。
需要注意的是,ArrayDeque不支持null值。
常用操作方法:
- addFirst(E e)在数组前面添加元素
- addLast(E e)在数组后面添加元素
- offerFirst(E e) 在数组前面添加元素,并返回是否添加成功
- offerLast(E e) 在数组后天添加元素,并返回是否添加成功
- removeFirst()删除第一个元素,并返回删除元素的值,如果元素为null,将抛出异常
- pollFirst()删除第一个元素,并返回删除元素的值,如果元素为null,将返回null
- removeLast()删除最后一个元素,并返回删除元素的值,如果为null,将抛出异常
- pollLast()删除最后一个元素,并返回删除元素的值,如果为null,将返回null
- removeFirstOccurrence(Object o) 删除第一次出现的指定元素
- removeLastOccurrence(Object o) 删除最后一次出现的指定元素
- getFirst() 获取第一个元素,如果没有将抛出异常
- getLast() 获取最后一个元素,如果没有将抛出异常
- add(E e) 在队列尾部添加一个元素
- offer(E e) 在队列尾部添加一个元素,并返回是否成功
- remove() 删除队列中第一个元素,并返回该元素的值,如果元素为null,将抛出异常(其实底层调用的是removeFirst())
- poll() 删除队列中第一个元素,并返回该元素的值,如果元素为null,将返回null(其实调用的是pollFirst())
- element() 获取第一个元素,如果没有将抛出异常
- peek() 获取第一个元素,如果返回null
5.Map接口类
参考链接:https://blog.csdn.net/qq_34316768/article/details/99296332
java为数据结构中的映射定义了一个接口java.util.Map,而HashMap Hashtable和TreeMap就是它的实现类。Map是将键映射到值的对象,一个映射不能包含重复的键;每个键最多只能映射一个一个值。
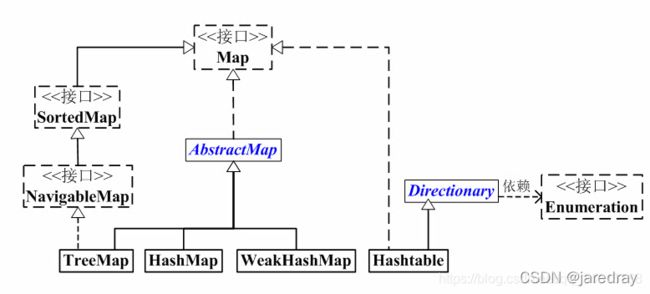
(1) Map 是“键值对”映射的抽象接口。
(2) AbstractMap 实现了Map中的绝大部分函数接口。它减少了“Map的实现类”的重复编码。
(3) SortedMap 有序的“键值对”映射接口。
(4) NavigableMap 是继承于SortedMap的,支持导航函数的接口。
(5) HashMap, Hashtable, TreeMap, WeakHashMap这4个类是“键值对”映射的实现类。它们各有区别!
HashMap 是基于“拉链法”实现的散列表。一般用于单线程程序中。
Hashtable 也是基于“拉链法”实现的散列表。它一般用于多线程程序中。
WeakHashMap 也是基于“拉链法”实现的散列表,它一般也用于单线程程序中。相比HashMap,WeakHashMap中的键是“弱键”,当“弱键”被GC回收时,它对应的键值对也会被从WeakHashMap中删除;而HashMap中的键是强键。
TreeMap 是有序的散列表,它是通过红黑树实现的。它一般用于单线程中存储有序的映射。
( 拉链法又叫链地址法,Java中的HashMap在存储数据的时候就是用的拉链法来实现的,拉链发就是把具有相同散列地址的关键字(同义词)值放在同一个单链表中,称为同义词链表。)
常用操作方法:
- clear() 删除 hashMap 中的所有键/值对
- clone() 复制一份 hashMap
- isEmpty() 判断 hashMap 是否为空
- size() 计算 hashMap 中键/值对的数量
- put() 将键/值对添加到 hashMap 中
- putAll() 将所有键/值对添加到 hashMap 中
- putIfAbsent() 如果 hashMap 中不存在指定的键,则将指定的键/值对插入到 hashMap 中。
- remove() 删除 hashMap 中指定键 key 的映射关系
- containsKey() 检查 hashMap 中是否存在指定的 key 对应的映射关系。
- containsValue() 检查 hashMap 中是否存在指定的 value 对应的映射关系。
- replace() 替换 hashMap 中是指定的 key 对应的 value。
- replaceAll() 将 hashMap 中的所有映射关系替换成给定的函数所执行的结果。
- get() 获取指定 key 对应对 value
- getOrDefault() 获取指定 key 对应对 value,如果找不到 key ,则返回设置的默认值
- forEach() 对 hashMap 中的每个映射执行指定的操作。
- entrySet() 返回 hashMap 中所有映射项的集合集合视图。
- keySet() 返回 hashMap 中所有 key 组成的集合视图。
- values() 返回 hashMap 中存在的所有 value 值。
- merge() 添加键值对到 hashMap 中
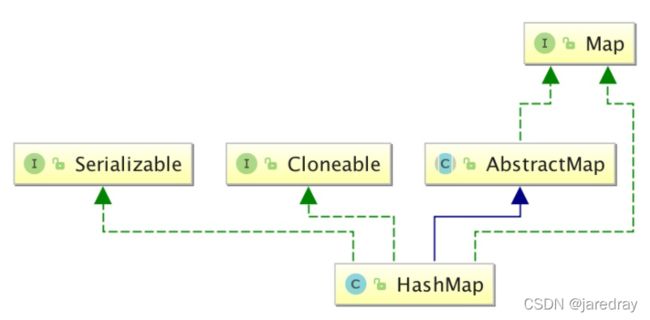
5.1 HashMap类
- Hashmap 是一个最常用的Map,它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快的访问速度。
- HashMap最多只允许一条记录的键为Null;允许多条记录的值为Null;HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap;可能会导致数据的不一致。
- 如果需要同步,可以用Collections的synchronizedMap方法使HashMap具有同步的能力.
- 用链表或者红黑树实现HashMap
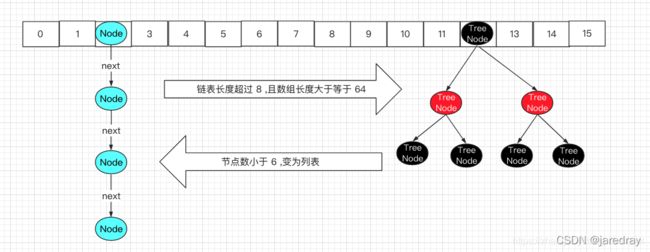
- HashMap:数组+链表+红黑树
5.2 Hashtable类
它和HashMap类很相似,但是它支持同步。
像HashMap一样,Hashtable在哈希表中存储键/值对。当使用一个哈希表,要指定用作键的对象,以及要链接到该键的值。
该键经过哈希处理,所得到的散列码被用作存储在该表中值的索引。
Hashtable 与 HashMap类似,但是主要有6点不同。
1.HashTable的方法是同步的,HashMap未经同步,所以在多线程场合要手动同步HashMap这个区别就像Vector和ArrayList一样。
2.HashTable不允许null值,key和value都不可以,HashMap允许null值,key和value都可以。HashMap允许key值只能由一个null值,因为hashmap如果key值相同,新的key, value将替代旧的。
3.HashTable有一个contains(Object value)功能和containsValue(Object value)功能一样。
4.HashTable使用Enumeration,HashMap使用Iterator。
5.HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
6.哈希值的使用不同,HashTable直接使用对象的hashCode。
- Hashtable支持contains(Object value)方法,而且重写了toString()方法;
- 而HashMap不支持contains(Object value)方法,没有重写toString()方法。
5.3 TreeMap类
TreeMap是SortedMap的实现类,是一个红黑树的数据结构,每个key-value对作为红黑树的一个节点。TreeMap存储key-value对时,需要根据key对节点进行排序。
- TreeMap能够把它保存的记录根据键排序,默认是按升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。
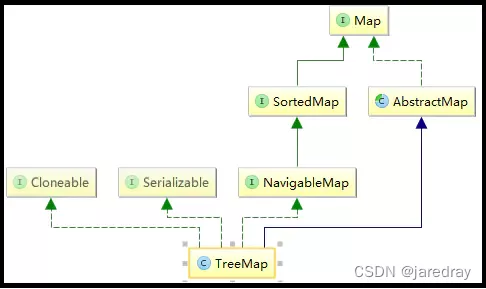
TreeMap: 红黑树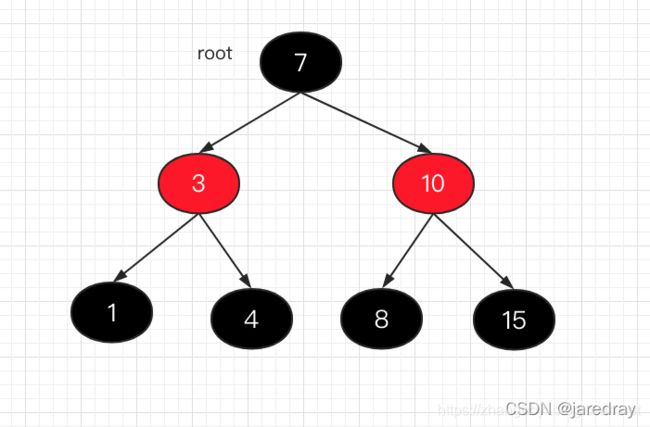
6.Set接口类
Set集合类似于一个罐子,程序可以依次把多个对象“丢进”Set集合,而Set集合通常不能记住元素的添加顺序。实际上Set就是Collection只是行为略有不同(Set不允许包含重复元素)。
Set集合不允许包含相同的元素,如果试图把两个相同元素加入同一个Set集合中,则添加操作失败,add()方法返回false,且新元素不会被加入
Conllection——>Set——>TreeSet和HashSet
常用操作方法
- add(Object obj):向Set集合中添加元素,添加成功返回true,否则返回false。
- size():返回Set集合中的元素个数。
- remove(Object obj): 删除Set集合中的元素,删除成功返回true,否则返回false。
- isEmpty():如果Set不包含元素,则返回 true ,否则返回false。
- clear(): 移除此Set中的所有元素。
- iterator():返回在此Set中的元素上进行迭代的迭代器。
- contains(Object o):如果Set包含指定的元素,则返回 true,否则返回false。
6.1 HashSet类
HashSet是Set接口的典型实现,大多数时候使用Set集合时就是使用这个实现类。HashSet按Hash算法来存储集合中的元素,因此具有很好的存取和查找性能。底层数据结构是哈希表。
HashSet具有以下特点:
- 不能保证元素的排列顺序,顺序可能与添加顺序不同,顺序也可能发生变化;
- HashSet不是同步的;
- 集合元素值可以是null;
6.2 LinkedHashSet类
- LinkedHashSet集合也是根据元素的hashCode值来决定元素的存储位置,但它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的,也就是说当遍历集合LinkedHashSet集合里的元素时,集合将会按元素的添加顺序来访问集合里的元素。
- 输出集合里的元素时,元素顺序总是与添加顺序一致。但是LinkedHashSet依然是HashSet,因此它不允许集合重复。
6.3 TreeSet类
- TreeSet是SortedSet接口的实现类,TreeSet可以确保集合元素处于排序状态。
- TreeSet内部实现的是红黑树,默认整形排序为从小到大。
- TreeMap内部对元素的操作复杂度为O(logn)
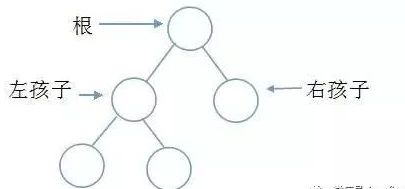
TreeSet的底层是这样的一个二叉树(如上图所示)
当我们存储的第一个元素的时候,会把第一个元素存在“根”的位置,存储第二个元素的时候,TreeSet 底层会调用 compareTo() 方法:
1)如果 compareTo()的返回结果为 0 则这两个元素是一样的,就不会存储,
2)如果返回负数,则第二个元素比第一个元素小,把第二个元素存储在左孩子的位置。
3)如果返回正数,则第二个元素比第一个元素大,把第二个元素存储在右孩子的位置。
以此类推~