python计算平均值画折线图_Python 数据分析测试2 之 求平均值 及 折线图显示
# Time: 2020/07/27
#Author: Xiaohong
# 运行环境: OS: Windows 10
# Python: 3.7
# 功能: 导入4份文件(分别对应4个部位),测算出其中2条生产线, 4个部位的“平均库存时间”,以 折线图 方式 显示
效果如下:
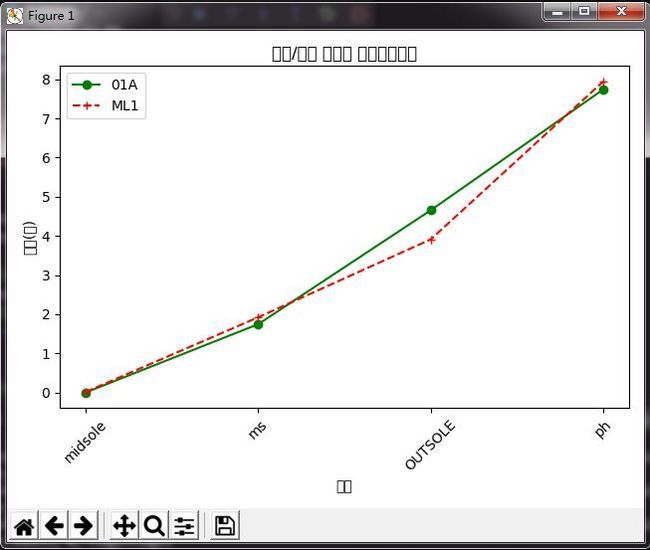
主程序为(Tl_B03.py):
import numpy as np
import os
import matplotlib.pyplot as plt
'''
统计的数据来源:来自4个文件,分别对应4个部位。
其中格式如下:序号、库存时间、Etag、LotNo、部位、Size、入库时间、入库数量、出库时间、出库数量、Ticketid、库别、生产线、单据号
Function: 测算出2条生产线, 4个部位的“平均库存时间”,以 折线图 方式 显示
'''
data_path=r'E:\\vscode_2020\\vstestfxh\\fxh_qt501\\fxh_qt501\\source_file\\lfpis'
data_filenames=['midsole.csv','ms.csv','OUTSOLE.csv','ph.csv']
#结果输出的路径
output_path='./output'
#目录不存在的话,就创建
if not os.path.exists(output_path):
os.makedirs(output_path)
#收集&处理数据
def collect_process_data():
#初始化返回结果
data_arr_list=[]
#遍历要导入文件的列表
for data_filename in data_filenames:
#文件完整路径
data_file=os.path.join(data_path,data_filename)
#通过 numpy 把CSV文件导入到 numpy 数组 data_str 中
# CSV文件 是以,分割,每列均当成是string型,第一行忽略
data_str=np.loadtxt(data_file,delimiter=',',dtype='str',skiprows=1)
#对每列数据 去掉双引号
data_arr= np.core.defchararray.replace(data_str,'"','')
# print(data_arr.shape)
# 写入 结果列表 中
data_arr_list.append(data_arr)
return data_arr_list
#过滤数据
def get_filter_data(data_arr_list,line_type):
#初始化返回结果
mean_in_stock_list=[]
#遍历要处理的数组列表
for data_arr in data_arr_list:
#设定Bool数组,以倒数第二列值判断是否是 line_type
bool_arr= data_arr[:,-2]==line_type
# print(bool_arr)
#得到符合条件的 数组
filter_arr=data_arr[bool_arr]
# print(filter_arr.shape)
#对第二列的值,当成float型,且求平均值
mean_in_stock=np.mean(filter_arr[:,1].astype('float'))
# 写入 结果列表 中
mean_in_stock_list.append(mean_in_stock)
return mean_in_stock_list
#保存&展示结果
def save_show_result(data_list1,data_list2):
#保存结果到 result.csv 中
# 遍历结果列表
for idx in range(len(data_list1)):
#取出各自对应值
list1=data_list1[idx]
list2=data_list2[idx]
#print 结果
print('{}文件中,01A 平均库存时间:{:.4f},ML1 平均库存时间:{:.4f}'.format(data_filenames[idx],list1,list2))
#把结果 转置(transpose) 后 保存到 numpy 数组中
mean_in_stock_arr=np.array([data_list1,data_list2]).transpose()
#保存结果到 result.csv 中
#以,分割 标题为 01A,ML1, 保留4位小数,comments='' 是指标题不带#
np.savetxt('./result.csv',mean_in_stock_arr,delimiter=',',header='01A,ML1',fmt='%.4f',comments='')
#用 matplotlib 库中的 pyplot 来画出 图形
plt.figure()
#以数组data_list1,来画出 折线图,折线颜色 green,折线一直线显示, 数值处以o标记, 折线标签为01A
plt.plot(data_list1,color='g',linestyle='-',marker='o',label='01A')
#以数组data_list2,来画出 折线图,折线颜色 RED,折线一虚线显示, 数值处以+标记, 折线标签为ML1
plt.plot(data_list2,color='r',linestyle='--',marker='+',label='ML1')
#图形标题
plt.title('底部/贴底 各部位 平均库存时间')
# X 坐标轴的标识
plt.xticks(range(0,4),['midsole','ms','OUTSOLE','ph'],rotation=45)
# X 坐标轴的标题
plt.xlabel('部位')
# Y 坐标轴的标题
plt.ylabel('时间(天)')
# 要显示图例,且位置为 系统自行判断的最佳位置
plt.legend(loc='best')
# 合理显示 整个图形的 Layout,若无该配置,可能部分要素会被遮盖,无法显示
plt.tight_layout()
#保存图片结果到result_plot.png
plt.savefig(os.path.join(output_path,'./result_plot.png'))
#显示图形
plt.show()
#主程序
def main():
data_arr_list=collect_process_data()
data_ML1_list=get_filter_data(data_arr_list,'LF ML1')
data_01A_list=get_filter_data(data_arr_list,'LF 01A')
print(data_ML1_list)
print(data_01A_list)
save_show_result(data_01A_list,data_ML1_list)
#程式调用入口
if __name__=='__main__':
main()