RoBERTa:一种鲁棒地优化BERT预训练的方法
RoBERTa:一种鲁棒地优化BERT预训练的方法
文章目录
- RoBERTa:一种鲁棒地优化BERT预训练的方法
-
- 前言
- 背景
- 实验
-
- 静态 VS 动态 Masking
- 输入形式与NSP任务
- 更大的batch_size
- 更大的BPE词汇表
- 总结
- 使用
- 最后
前言
本文提出了一种对BERT预训练进行精细调参和调整训练集的方法,用这种方法对BERT进行预训练还能提升性能。
自训练的方法,诸如 ELMo、GPT、BERT、XLM、XLNet 均带来了很大的性能提升,但很难搞懂究竟是方法的哪些方面对模型性能的提升贡献最大。
我们复现了BERT的工作,并对调参和数据集大小的影响进行了细致的评估。
我们对模型进行了如下修改:
- 1、用更大的batch和更多的数据,让模型训练的更久一些;
- 2、去掉了 NSP (Next Sentence Prediction) 这个任务;
- 3、在更长的序列上进行训练;
- 4、动态修改训练数据的MASK机制。
并且我们提出了一个新的数据集 CC-NEWS 。
原文链接:https://arxiv.org/pdf/1907.11692.pdf
Github: https://github.com/pytorch/fairseq
背景
本节主要回顾 BERT 预训练的一些参数设置和训练目标,为引出后面的创新点作铺垫。
BERT 的输入:两个序列拼接到一起,并用两种特殊符号分隔,如:
[ C L S ] , x 1 , . . . , x N , [ S E P ] , y 1 , . . . , y M , [ E O S ] . [CLS], x_1, ..., x_N, [SEP], y_1, ..., y_M, [EOS]. [CLS],x1,...,xN,[SEP],y1,...,yM,[EOS].
其中 N + M < T N+M
BERT 首先是用大规模无标注的数据进行预训练,然后再用有标注的数据在特定任务上进行精调。
BERT 模型结构:L 层Transformer,A 个自注意力机制头,隐层向量维度为 H。
BERT 两个训练目标:
- Masked Language Model (MLM):从输入的序列里里选出15%的token,对其进行 MASK(广义的MASK,即80%替换成 [MASK] 符号,10% 随机替换成词表里的词汇,10% 保持不变)。注意:在BERT最早提出的代码实现上,是最开始对数据就进行了 MASK 替换,然后给模型进行多次迭代训练。
- Next Sentence Prediction (NSP):这是一个二分类任务,就是判断输入的两个句子/片段在原文本中是否为前者的下一个句子。NSP任务是为自然语言推理任务设计的,加入NSP训练目标可以提升下游推理任务性能。
数据集,一共16 GB:
- BookCorpus
- English Wikipedia
实验
关于数据,大量研究探讨了使用更多、更多元(差异性更大)的数据来进行提升BERT的性能。
静态 VS 动态 Masking
本文对于BERT的MASK方式做了修改,如下:
-
reference (BERT 原始的MASK方式) : 在预处理阶段进行MASK替换。
-
static:在预处理阶段,将原始数据拷贝10份,对每个句子都进行MASK,这样同一个句子就有了10种不同的MASK方式。
-
dynamic:每次将序列输入模型前动态地进行MASK,这样每次MASK都不一样。
下面是实验结果对比:
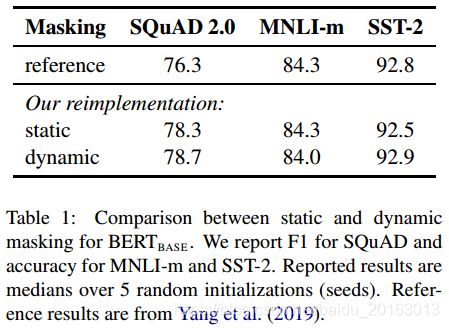
从上面实验结果看出,static与reference的效果差不多,dynamic在性能上稍微有一点提升。本文接下来均采用dynamic的MASK方式。
结论:动态MASK比静态MASK效果好。
输入形式与NSP任务
在原始的BERT训练步骤中,输入模型的两个句子会被简单拼接在一起,它们50%的概率是来自同一文本的相邻句子,50%来自不同的文本,即NSP任务的正负样本比例为1:1。
之前的研究表明,如果去掉NSP任务,BERT模型在QNLI,MNLI和SQuAD 1.1 性能会出现明显的下降。
于是本文对于NSP存在的必要性进行了对比实验:
- Segment-Pair + NSP:原始BERT的做法,采用来自相同或不同的文本片段对+NSP loss的训练方式。这里的文本片段可能会包含多个句子。
- Sentence-Pair + NSP:这里是采用句子对,为了和使用文本片段方式在一个batch内的token数量相同,这里采用了更大的batch size。
- Full-Sentences:去掉了NSP,从一个或多个文档里提取连续的句子,并保持长度不超过512。如果当前文档长度不足512,就从下一个文档继续采集,并在两者分界处加一个 [SEP] 分隔。
- Doc-Sentences:也去掉了NSP,与Full-Sentences模式不一样的就是不跨文档,即单文档。
结果如下:

可以看到,使用句子对(Sentence-Pair)时,模型性能下降了,可能是因为模型学不到长距离依赖,导致测试集中长文本上效果会下降。Doc-Sentences (去掉NSP)相比原始BERT的Segment-Pair (NSP)的性能要好那么一点点;同时也比Full-Sentences好一点点。这说明去掉NSP其实也可以,并且单文档的 效果比多文档好。
结论:去掉NSP训练目标并不会降低BERT性能。
更大的batch_size
**用更大的batch_size进行训练可以提升模型性能吗?可以。**当然这个前提是你的GPU有足够的显存。
实验结果如下:
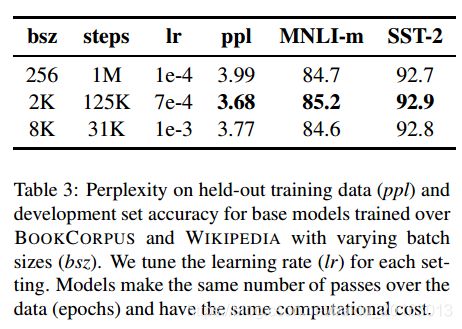
bsz是batch_size,当从256提升到2K时,ppl(MLM 的困惑度,越低说明模型学的越好)降低了,在推理(MNLI-m)和情感分析(SST-2)上性能都提升了。
结论:batch_size可以设得更大(2K、8K),模型性能没什么影响。
更大的BPE词汇表
原始BERT的词汇表大小是30K,本文增加到了50K。
总结
RoBERTa 这篇论文的主要创新点如下:
- 丢弃NSP,效果更好;
- 动态改变MASK策略,把数据复制10份,然后统一进行随机MASK;
- 对学习率的峰值和warm-up更新步数作出调整;
- 在更长的序列上训练:不对序列进行截断,使用全长度序列。
使用
对于RoBERTa的使用,其实和BERT一模一样,把别人预训练好的下载下来,替换原来下载的BERT模型即可。
中文 RoBERTa训练模型可以从这里下载,哈工大的大佬们已经帮我们训练好了,tensorflow、pytorch版的都有:
Github: Chinese-BERT-wwm
最后
本人才疏学浅,以上解读仅供参考,更多精彩内容欢迎关注我的个人公众号 【AI分享者】。