[论文精读] [NeRF] [AAAI 2023] One is All: Bridging the Gap Between Neural Radiance Fields Architectures
![[论文精读] [NeRF] [AAAI 2023] One is All: Bridging the Gap Between Neural Radiance Fields Architectures_第1张图片](http://img.e-com-net.com/image/info8/19afeae134e6465ba209d8d78cac5749.jpg)
One is All: Bridging the Gap Between Neural Radiance Fields Architectures
- Abstract
- Motivations
- Contributions
- Method
-
- Overview
- Preliminaries
-
- NeRF [R1]
- Plenoxels [R2]
- TensoRF [R3]
- INGP [R4]
- PVD: Progressive Volume Distillation
-
- Loss Design
- Density Range Constrain
- Block-wise Distillation
- Experiments
-
- Results
- Ablation Study
- Paper Notes
- References
Abstract
Neural Radiance Fields (NeRF) methods have proved effective as compact, high-quality and versatile representations for 3D scenes, and enable downstream tasks such as editing, retrieval, navigation, etc. Various neural architectures are vying for the core structure of NeRF, including the plain Multi-Layer Perceptron (MLP), sparse tensors, low-rank tensors, hashtables and their compositions. Each of these representations has its particular set of trade-offs. For example, the hashtable-based representations admit faster training and rendering but their lack of clear geometric meaning hampers downstream tasks like spatial-relation-aware editing. In this paper, we propose Progressive Volume Distillation (PVD), a systematic distillation method that allows any-to-any conversions between different architectures, including MLP, sparse or low-rank tensors, hashtables and their compositions. PVD consequently empowers downstream applications to optimally adapt the neural representations for the task at hand in a post hoc fashion. The conversions are fast, as distillation is progressively performed on different levels of volume representations, from shallower to deeper. We also employ special treatment of density to deal with its specific numerical instability problem. Empirical evidence is presented to validate our method on the NeRF-Synthetic, LLFF and TanksAndTemples datasets. For example, with PVD, an MLP-based NeRF model can be distilled from a hashtablebased Instant-NGP model at a 10×∼20× faster speed than being trained the original NeRF from scratch, while achieving a superior level of synthesis quality.
神经辐射场(NERF)方法被证明是一种有效的紧凑、高质量和通用的3D场景表示方法,并支持编辑、检索、导航等下游任务。各种神经体系结构正在争做NERF的核心结构,包括普通的多层感知器(MLP)、稀疏张量、低阶张量、哈希表及其组成。每一种表现形式都有其特定的权衡。例如,基于哈希表的表示允许更快的训练和渲染,但它们缺乏清晰的几何意义,阻碍了下游任务,如空间关系感知编辑。在本文中,我们提出了渐进体积蒸馏(PVD),这是一种系统的蒸馏方法,允许在不同的体系结构之间进行任意到任意的转换,包括MLP、稀疏或低阶张量、哈希表及其组合。因此,PVD使下游应用程序能够以后自组织方式最佳地适应手头任务的神经表示。因为蒸馏是在不同级别的体积表示上逐步进行的,从浅到深,所以转换速度很快。我们还采用了密度的特殊处理来处理其特定的数值不稳定性问题。在NERF合成数据集、LLFF数据集和TanksAndTemples数据集上的实验结果验证了该方法的有效性。例如,利用pvd,可以以比从头开始训练原始nerf快10×∼20倍的速度从基于散列表的即时ngp模型中提取基于mlp的nerf模型,同时实现更高水平的合成质量。
Motivations
Various neural architectures are vying for the core structure of NeRF, including the plain Multi-Layer Perceptron (MLP), sparse tensors, low-rank tensors, hashtables and their compositions
各种神经结构都在争做NERF的核心结构,包括普通的多层感知器(MLP)、稀疏张量、低阶张量、哈希表及其组成。
Due to the diversity of downstream tasks of NVS, there is no single answer as to which representation is the best. The particular choice would depend on the specific application scenarios and the available hardware computation capabilities.
由于新视角合成下游任务的多样性,对于哪种表示法是最好的,并没有单一的答案。具体的选择将取决于特定的应用场景和可用的硬件计算能力。
Instead of focusing on an ideal alternative representation that embraces the advantages of all variants, we propose a method to achieve arbitrary conversions between known NeRF architectures, including MLPs, sparse tensors, low-rank tensors, hash tables and combinations thereof.
我们没有关注包含所有变体优点的理想替代表示,而是提出了一种在已知的NERF体系结构之间实现任意转换的方法,包括MLP、稀疏张量、低阶张量、哈希表及其组合。
Such flexible conversions can obviously bring the following advantages. Firstly, the study would throw insights into the modeling capabilities and limitations of the already rich and ever-growing constellation of architectures of NeRF. Secondly, the possibility of such conversions would free the designer from the burden of pinning down architectures beforehand, as now they can simply adapt a trained model agilely to other architectures to meet the needs of later discovered application scenarios. Last but not least, complementary benefits may be leveraged in cases where teacher and student are of different attributes.
这种灵活的转换显然可以带来以下好处。首先,这项研究将深入了解NERF已经丰富且不断增长的体系结构的建模能力和局限性。其次,这种转换的可能性将使设计人员从预先确定体系结构的负担中解脱出来,因为现在他们只需将经过训练的模型灵活地适应其他体系结构,以满足后来发现的应用场景的需求。最后,在教师和学生具有不同属性的情况下,可以利用互补利益。
Contributions
- We propose PVD, a distillation framework that allows conversions between different NeRF architectures, including the MLP, sparse tensor, low-rank tensor and hash table architectures. To the best of our knowledge, this is the first systematic attempt at such conversions.
- In PVD, we build a block-wise distillation strategy to accelerate the training procedure based on a unified view of different NeRF architectures. We also employ a special treatment of the dynamic density volume range by clipping, which improves the training stability and significantly improves the synthesis quality.
- As concrete examples, we find that distillation from hashtable and VM-decomposition structures often either helps boost student model synthesis quality and consumes less time than training from scratch. A particular beneficial case, where a NeRF student model is distilled from an INGP teacher.
![[论文精读] [NeRF] [AAAI 2023] One is All: Bridging the Gap Between Neural Radiance Fields Architectures_第2张图片](http://img.e-com-net.com/image/info8/481ee5d836444e2388ce311b03779be1.jpg)
Method
Overview
![[论文精读] [NeRF] [AAAI 2023] One is All: Bridging the Gap Between Neural Radiance Fields Architectures_第3张图片](http://img.e-com-net.com/image/info8/8a2003488dc64fbbb4d25e9ebd4a1999.jpg)
With PVD, given one trained NeRF model, different NeRF achitecutres, like sparse tensors, MLP, low-rank tensors and hash tables can be obtained quickly through distillation. The loss in intermediate volume representations (shown as double arrow symbol) like output of φ ∗ 1 φ^1_∗ φ∗1, color and density are used alongside the final rendered RGB volume to accelerate distillation.
对于PVD,只要给定一个训练好的NeRF模型,就可以通过蒸馏快速得到稀疏张量、MLP、低秩张量和哈希表等不同的NeRF结构。中间体积表示(显示为双箭头符号)中的损失,如 φ ∗ 1 φ^1_∗ φ∗1的输出、颜色和密度与最终渲染的RGB一起使用,以加速蒸馏。
Our method aims to achieve mutual conversions between different architectures of Neural Radiance Fields. Since there is an ever-increasing number of such architectures, we will not attempt to achieve these conversions one by one. Rather, we first formulate typical architectures in a unified form and then design a systematic distillation scheme based on the unified view. The architectures we have derived formula include implicit representations like MLP in NeRF, explicit representations like sparse tensors in Plenoxels, and two hybrid representations: hash tables (in INGP) and lowrank tensors (VM-decomposition in TensoRF). Once formulated, any-to-any conversion between these architectures and their compositions is possible.
我们的方法旨在实现不同结构的神经辐射场之间的相互转换。由于此类体系结构的数量不断增加,我们不会尝试逐一实现这些转换。相反,我们首先以统一的形式制定典型的体系结构,然后基于统一的视图设计系统的升华方案。我们推导出的体系结构公式包括NERF中的MLP隐式表示,Plenoxels中的稀疏张量等显式表示,以及两种混合表示:哈希表(INGP)和低阶张量(TensoRF中的VM-分解)。一旦制定,就可以在这些体系结构和它们的组成之间进行任意转换。
Preliminaries
NeRF [R1]

![[论文精读] [NeRF] [AAAI 2023] One is All: Bridging the Gap Between Neural Radiance Fields Architectures_第4张图片](http://img.e-com-net.com/image/info8/ff554e1579c440f2945df30e9c97d1a1.jpg)
Plenoxels [R2]

![[论文精读] [NeRF] [AAAI 2023] One is All: Bridging the Gap Between Neural Radiance Fields Architectures_第5张图片](http://img.e-com-net.com/image/info8/608624bed5f04882888032be07cc56b0.jpg)
TensoRF [R3]

![[论文精读] [NeRF] [AAAI 2023] One is All: Bridging the Gap Between Neural Radiance Fields Architectures_第6张图片](http://img.e-com-net.com/image/info8/85a5d892f1ae4680b71c3296918987b6.jpg)
INGP [R4]
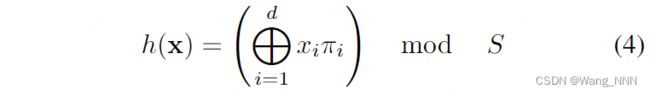
![[论文精读] [NeRF] [AAAI 2023] One is All: Bridging the Gap Between Neural Radiance Fields Architectures_第7张图片](http://img.e-com-net.com/image/info8/0621b9fbb6f3422184d39fab4dcc8daa.jpg)
PVD: Progressive Volume Distillation
Given a trained model, our task is to distill it into other models, possibly with different architectures. In PVD, we design a volume-aligned loss and build a blockwise distillation strategy to accelerate the training procedure based on a unified view of different NeRF architectures. We also employ a special treatment of the dynamic density volume range by clipping, which improves the training stability and significantly improves the synthesis quality.
给定一个经过训练好的模型,我们的任务是将其蒸馏成其他模型,可能具有不同的体系结构。在PVD中,基于不同NERF结构的统一视图,我们设计了体对齐的损失,并构建了块蒸馏策略来加速训练过程。我们还对动态密度体积范围进行了特殊的裁剪处理,提高了训练的稳定性,显著提高了合成质量。
Loss Design
In our method, we not only use the RGB, but also use the density, color and an additional intermediate feature to calculate loss between different structures.
在我们的方法中,我们不仅使用RGB,而且还使用密度、颜色和附加的中间特征来计算不同结构之间的损失。
We observed that the implicit and explicit structures in the hybrid representation are naturally separated and correspond to different learning objectives. Therefore, we consider splitting a model into this similar expression forms so that different parts can be aligned during distillation.
我们观察到,混合表征中的内隐和外显结构是自然分离的,并与不同的学习目标相对应。因此,我们考虑将模型拆分成类似的表达形式,以便在蒸馏过程中不同的部分可以对齐。
Specifically, given a model φ ∗ φ_∗ φ∗, we represent them as a cascade of two modules as follows:
给定一个 φ ∗ φ_∗ φ∗模型,我们将它们表示为两个模块的级联,如下所示:
![]()
The division of each architecture under our unified two-level view. Regarding NeRF, K=4 is used by default in this paper.
在我们统一的两级视图下对每个架构的划分。关于NERF,本文默认使用K=4。
![[论文精读] [NeRF] [AAAI 2023] One is All: Bridging the Gap Between Neural Radiance Fields Architectures_第8张图片](http://img.e-com-net.com/image/info8/797d8e656b0247f9bc2b1562da341d97.jpg)
Here * can be either a teacher or a student. For hybrid representations, we directly regard the explicit part as φ ∗ 1 φ^1_∗ φ∗1, and the implicit part as φ ∗ 2 φ^2_∗ φ∗2. While for purely implicit representation, we divide the network into two parts with similar number of layers according to its depth, and denote the former part as φ ∗ 1 φ^1_∗ φ∗1 and the latter part as φ ∗ 2 φ^2_∗ φ∗2. As for the purely explicit representation Plenoxels, we still formulate it into two parts by letting φ ∗ 1 φ^1_∗ φ∗1 be the identity, though it can be transformed without splitting. Based on the splitting, we design volume-aligned losses as follows:
在这里,*可以是老师,也可以是学生。对于混合表示,我们直接将显式部分视为 φ ∗ 1 φ^1_∗ φ∗1,隐含部分为 φ ∗ 2 φ^2_∗ φ∗2。而对于纯隐式表示,我们根据网络的深度将网络分为两个层数相近的部分,将前者称为 φ ∗ 1 φ^1_∗ φ∗1,后者称为 φ ∗ 2 φ^2_∗ φ∗2。对于纯粹的显式表示Plenoxels,我们仍然通过让 φ ∗ 2 φ^2_∗ φ∗2作为恒等映射来将其表示成两部分,尽管它可以不分裂地变换。(模型的具体拆分见上表)。基于拆分,我们设计了如下体对齐损失:
![]()
In essence, the reason for designing this loss is that models in different forms can be mapped to the same space that represents the scene. Our experiments have shown that this volume-aligned loss can accelerate the distillation and improve the quality significantly.
本质上,设计这种损失的原因是不同形式的模型可以映射到表示场景的相同空间。我们的实验表明,这种体对齐损失可以加快蒸馏速度,显著提高产品质量。
在蒸馏过程中的完整损失函数如下:
![]()
where L σ L_σ Lσ , L c L_c Lc, L r g b L_{rgb} Lrgb, denote the density loss, color loss and RGB loss respectively. L 2 L_2 L2 is the mean-squared error (MSE). The last item Lreg represents the regularization term, which depends on the form of the student model. For Plenoxels and VM-decomposition, we add L 1 L_1 L1 sparsity loss and total variation (TV) regularization loss. It should be noted that we only perform density, color, RGB and regularization loss on Plenoxels for its explicit representation.
其中, L σ L_σ Lσ 、 L c L_c Lc、 L r g b L_{rgb} Lrgb分别表示密度损失、颜色损失和RGB损失。 L 2 L_2 L2是均方误差(MSE)。最后一项Lreg表示正则化项,它取决于学生模型的形式。对于Plenoxels和VM-分解,我们增加了 L 1 L_1 L1稀疏性损失和总变分(TV)正则化损失。值得注意的是,我们只对Plenoxels的显式表示进行密度、颜色、RGB和正则化损失。
Density Range Constrain
We found that the loss of density σ is hardly directly optimized. And we impute this problem to its specific numerical instability. That is, the density reflects the light transmittance of a point in the space. Whenσ is greater than or less than a certain value, its physical meaning is consistent (i.e., completely transparent or completely opaque). Therefore the value range of σ can be too wide for a teacher, but in fact, only one interval of the density values play a key role. On the basis of this, we limit the numerical range of σ to [ a , b ] [a, b] [a,b]. Then the L 2 σ L^σ_2 L2σ is calculated as follow:
我们发现,密度损失σ很难直接优化。我们将这个问题归因于它特有的数值不稳定性。也就是说,密度反映了空间中某个点的透射率。当σ大于或小于某个值时,其物理含义是一致的(即完全透明或完全不透明)。因此,σ的取值范围对于教师来说可能太宽了,但实际上,只有一个密度值区间起到了关键作用。在此基础上,我们将σ的数值范围限制在 [ a , b ] [a, b] [a,b]。则 L 2 σ L^σ_2 L2σ计算如下:
![]()
(hotdog场景)σ的数值范围选择:[-2,7]
![[论文精读] [NeRF] [AAAI 2023] One is All: Bridging the Gap Between Neural Radiance Fields Architectures_第9张图片](http://img.e-com-net.com/image/info8/a41a80c7a8b249ceb312504c6186acf0.jpg)
According to our experiments, this restricting has an inappreciable impact on the performance of teacher and bring a tremendous benefit to the distillation.
根据我们的实验,这种限制对教师的表现有微不足道的影响,并给蒸馏带来了巨大的好处。
We also consider to directly perform the density loss on the exp ( − σ i δ i ) (−σ_iδ_i) (−σiδi), but we found it is an inefficiency way since the gradient of exp are easier to saturate, and it requires computing an exponent that increases the amount of calculation when the block-wise is implemented.
我们也考虑直接对exp ( − σ i δ i ) (−σ_iδ_i) (−σiδi)进行密度损失,但我们发现这种方法效率不高,因为exp的梯度更容易饱和,而且它需要计算指数,从而增加了分块实现时的计算量。
Block-wise Distillation
During volume rendering, most of the computation occurs in MLP forwarding for each sampled point and integrating the output over each ray. Such a heavy process slows down the training and distillation significantly.
在体渲染过程中,大部分计算都发生在对每个采样点的MLP前向传播和对每条光线的输出进行积分。如此繁重的过程大大减慢了训练和蒸馏的速度。
While in our PVD, thanks to the designed of L 2 v L^v_2 L2v , we can implement the block-wise strategy to get rid of this problem. Specifically, we only forward stage1 at the beginning of training, and then run stage2 and stage3 in turn.
而在我们的PVD中,由于 L 2 v L^v_2 L2v的设计,我们可以实现分块策略来解决这个问题。具体地说,我们只在训练开始时转发Stage1,然后依次运行Stage2和Stage3。
Consequently, the student and the teacher do not need to forward the complete network and render RGB in the early stages of training. In our experiment, the conversion from INGP to NeRF can be completed in tens of minutes, which requires several hours in the past.
因此,学生和教师不需要在培训的早期阶段前向传播完整的网络和渲染RGB。在我们的实验中,从INGP到NeRF的转换可以在几十分钟内完成,这在过去需要几个小时。
Experiments
Teacher models 数据集:NeRF-Synthetic dataset, forward-facing dataset (LLFF) and TanksAndTemple dataset
In the distillation stage, we find it sufficient to utilize the teacher to generate fake data as inpseudo-labeling, and not touch any of the training data.
在蒸馏阶段,我们发现利用教师生成伪标记伪数据,并且不接触任何训练数据就足够了。
Results
Our experiments mainly focus on whether the conversion between different models can maintain the performance of the teacher or its own upper limit.
这是第一次提出不同表示之间的转换方法,因此没有任何可比的基线。实验主要集中在不同模式之间的转换是否能够保持教师的成绩或其自身的上限。
我们的方法对于转换是非常有效的。当一个模型转换成另一种形式时,它的性能与从头开始训练模型的结果或教师的结果相差不大,充分表明基于辐射场的常见表示可以相互转换。此外,我们的PVD在相同结构之间的蒸馏中表现出优异的近乎无损的性能。
![[论文精读] [NeRF] [AAAI 2023] One is All: Bridging the Gap Between Neural Radiance Fields Architectures_第10张图片](http://img.e-com-net.com/image/info8/07f8d8bc18b94c2fb2faecaa10d59642.jpg)
Max(diff1,diff2)的值非常接近0,这意味着通过蒸馏得到的模型可以接近老师或从头训练的性能。我们的方法最大限度地将知识从老师迁移到学生。
![[论文精读] [NeRF] [AAAI 2023] One is All: Bridging the Gap Between Neural Radiance Fields Architectures_第11张图片](http://img.e-com-net.com/image/info8/60dec16903d54b26a789e377fa2c440c.jpg)
该方法既保证了合成质量,又保证了场景深度信息的准确性。
![[论文精读] [NeRF] [AAAI 2023] One is All: Bridging the Gap Between Neural Radiance Fields Architectures_第12张图片](http://img.e-com-net.com/image/info8/01d2fb53e17946eb868af38d30f4c773.jpg)
在另外两个数据集上的结果也证明了结果的有效性。并且通过我们的蒸馏得到的模型比它在TanksAndTemples数据集上的原始实现性能更好。这主要是因为我们的PVD方法为学生提供了更多的先验信息,使培训更加有效,充分提高了学生的表达能力。
![[论文精读] [NeRF] [AAAI 2023] One is All: Bridging the Gap Between Neural Radiance Fields Architectures_第13张图片](http://img.e-com-net.com/image/info8/0bb0c57d23704f1f8cbe78b95c599b16.jpg)
我们的方法获得NeRF模型的速度明显快于从头训练。(教师是基于VM分解的表示法)
![[论文精读] [NeRF] [AAAI 2023] One is All: Bridging the Gap Between Neural Radiance Fields Architectures_第14张图片](http://img.e-com-net.com/image/info8/62b9ba94115a4664a35978dc4bb3f540.jpg)
Ablation Study
消融研究证明了我们方法中每个组件对性能的影响程度。我们在NeRF-Synthetic数据集上实现了从VM分解到MLP的转换。可以看出,
- 我们设计的中间特征损失带来了0.9dB PSNR的改善。
- 不受密度值限制时性能会大幅下降。
- 在没有使用分块策略的情况下进行了蒸馏,在相同的训练时间预算下,它的性能很差。
![[论文精读] [NeRF] [AAAI 2023] One is All: Bridging the Gap Between Neural Radiance Fields Architectures_第15张图片](http://img.e-com-net.com/image/info8/cfe70a39084649f5a1329920f2482a17.jpg)
Paper Notes
- What problem is addressed in the paper?
ANS: Any-to-any conversions between different neural architectures. - Is it a new problem? If so, why does it matter? If not, why does it still matter?
ANS: Yes. This is the first systematic attempt at such conversions. - What is the key to the solution? What is the main contribution?
ANS:
(1) A distillation framework that allows conversions between different NeRF architectures.
(2) Block-wise distillation strategy to accelerate the training procedure based on a unified view of different NeRF architectures.
(3) Dynamic density volume range for training stability. - How the experiments sufficiently support the claims?
ANS: Effective for conversions, and with nearly nondestructive performance in distillation. - What can we learn from ablation studies?
ANS:
(1) Volume-aligned loss brings improvement.
(2) Drop sharply without the restriction on the value of density.
(3) Poor performance under the same budget of training time without block-wise distillation. - Potential fundamental flaws; how this work can be improved?
ANS:
(1) The performance of student models is generally upper-bounded by the performances of teacher models.
(2) As both teacher and student models need be active during training, memory and computation cost will be duly increased.
References
Paper: https://arxiv.org/abs/2211.15977
Project Page: https://sk-fun.fun/PVD
Code: https://github.com/megvii-research/AAAI2023-PVD
Related works
[R1] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
[R2] Plenoxels: Radiance Fields without Neural Networks
[R3] TensoRF: Tensorial Radiance Fields
[R4] Instant Neural Graphics Primitives with a Multiresolution Hash Encoding