Titanic机器学习——如何处理缺失值
Exploratory Data Analysis 探索性数据分析:对数据进行清洗,对数据进行描述(描述统计量,图表),查看数据的分布,比较数据之间的关系,培养对数据的直觉,对数据进行总结等。
Feature Engineering 特征工程是将原始数据“翻译”成模型可理解的形式,是机器学习工作流程中的重要组成部分
在机器学习和模式识别等领域中,一般需要将样本分成独立的三部分训练集(train set),验证集(validation set ) 和测试集(test set)。其中训练集用来估计模型,验证集用来确定网络结构或者控制模型复杂程度的参数,而测试集则检验最终选择最优的模型的性能如何。一个典型的划分是训练集占总样本的50%,而其它各占25%,三部分都是从样本中随机抽取。
Missing Values
许多现实世界中的数据集会因为各种原因而包含缺失值,这些缺失值通常会被留为空白,或是被标记为NaNs或其他占位符。在训练一个包含很多缺失值的数据集时,缺失值的存在会很大程度上影响机器学习模型的表现。
Training Set
Age column missing values: 177
Cabin column missing values: 687
Embarked column missing values: 2
Test Set
Age column missing values: 86
Fare column missing values: 1
Cabin column missing values: 327
作者的解决方案是
年龄方面
使用Pclass组的年龄中位数(因为对年龄和生存指数的的精确度高,同时用乘客类的年龄组比其他特征更合理)
又因为随着客舱级别的增加,乘客的年龄中位数也随之增加,然而女乘客的增加幅度较男乘客略小。所以为了提高精度,在处理缺失值的时候,乘客的性别数据要用作二级分组
Median age of Pclass 1 females: 36.0
Median age of Pclass 1 males: 42.0
Median age of Pclass 2 females: 28.0
Median age of Pclass 2 males: 29.5
Median age of Pclass 3 females: 22.0
Median age of Pclass 3 males: 25.0
Median age of all passengers: 28.0
登船地点
由于缺失值的数量很少(仅2个),作者Google了缺失值对应的乘客的姓名,找到乘客登船地点后,把’S’用fillna填入了缺失的地方
票价
由于缺失值的数量很少(仅1个)作者推理认为票价取决于客舱等级和人数,于是根据缺失值对应的乘客的信息,得出三等舱的单人票价的中位数适合填补缺失值。
舱位(cabin)
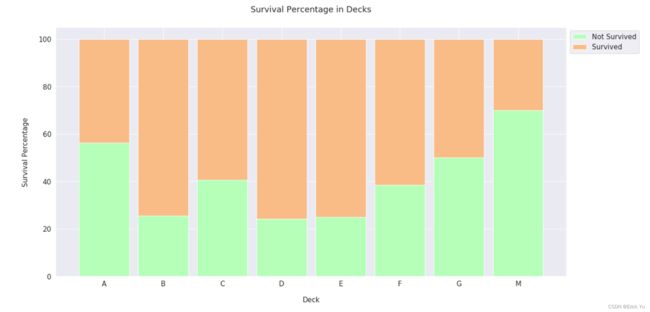
缺失值的数量很大且不能忽略,因为舱位和楼梯间的距离挂钩,直接关系到生存指数。
先通过舱位的首字母找到每级客舱在哪一层甲板,接着统计出每个位置上各个客舱的乘客的占比

其中T甲板只有1位乘客,而T甲板与A甲板最相近,所以把这位乘客归为A组
归到M组的乘客的舱位是缺失值,作者认为无法找出他们的真实甲板,所以把M作为他们所在的甲板
Age column missing values: 0
Embarked column missing values: 0
Fare column missing values: 0
Name column missing values: 0
Parch column missing values: 0
PassengerId column missing values: 0
Pclass column missing values: 0
Sex column missing values: 0
SibSp column missing values: 0
Ticket column missing values: 0
Deck column missing values: 0