SOTA模型训练笔记(完善中)
文章目录
- 记录感知SOTA模型训练的过程
- 1. 语义分割
- (1) PolarNet
- (2) Cylinder3D
- 2. 视觉人体姿态识别
- (1)ViTPose
- 3. 点云目标检测
- (1) centerpoint
记录感知SOTA模型训练的过程
1. 语义分割
(1) PolarNet
代码:https://github.com/AbangLZU/PolarSeg.git
https://github.com/edwardzhou130/PolarSeg
安装环境:
按照 requirements.txt
numpy
pytorch
tqdm
yaml
Cython
numba
torch-scatter
dropblock
(Optional) nuscenes-devkit
数据集准备:SemKITTI, 存放顺序如下
在semantic-kitti.yaml中修改dataset的路径,开始训练,
在服务器上选择的batch_size是4,可以用满1块显卡。
训练的模型保存路径等也可以修改。
#开始训练
cd PolarSeg
python train.py --data /path/to/your/dataset
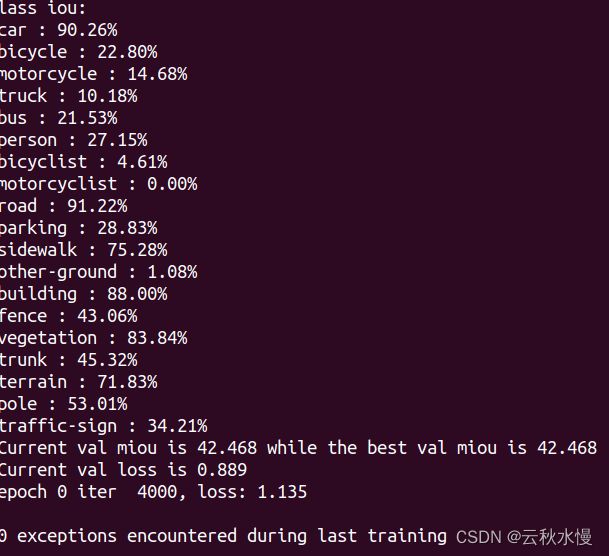
训练第一次:
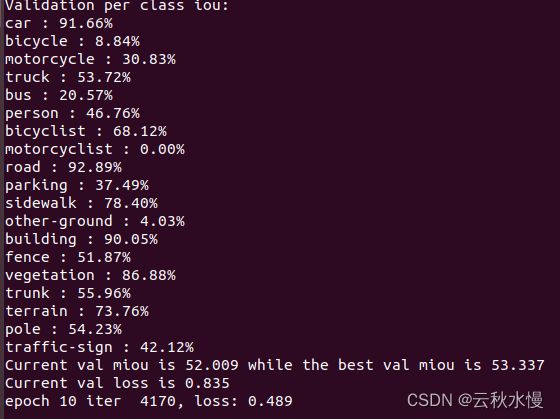
训练第10次:

推理:
python3 test_pretrain.py -d /path/to/your/semantickitti/dataset/ -p SemKITTI_PolarSeg.pt
(2) Cylinder3D
代码:https://github.com/xinge008/Cylinder3D/blob/master/network/segmentator_3d_asymm_spconv.py
安装环境:
Requirements
PyTorch >= 1.2
yaml
Cython
torch-scatter
nuScenes-devkit> (optional for nuScenes)
spconv(cuda113)
数据集准备:SemKITTI, 存放顺序:(同上polarnet)

训练第五次:
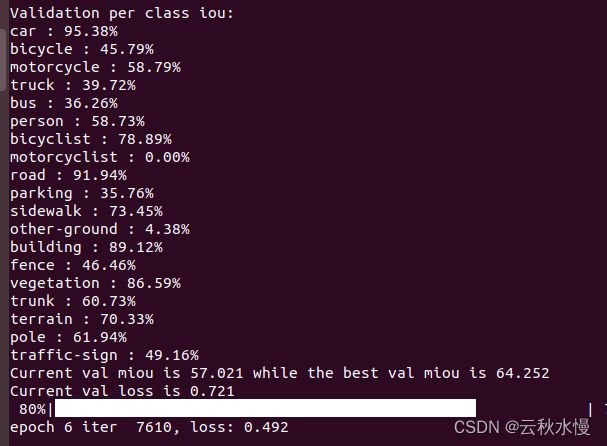
训练第39次:

安装cuda113对应的版本:pip install spconv-cu113
训练时遇到的问题:cuda11.3对应的spconv2比代码里用的spconv1新,很多函数报错。
解决如下:
问题集中在network/segmentator_3d_asymm_spconv.py
import spconv改成import spconv.pytorch as spconvx.features = F.relu(x.features)改成x = x.replace_feature(F.relu(x.features))- 一些卷积函数报错,提示不对应。
新的修改的:segmentator_3d_asymm_spconv_new.py 见 https://download.csdn.net/download/yunqiushuiman/86015877
2. 视觉人体姿态识别
(1)ViTPose
代码:https://github.com/ViTAE-Transformer/ViTPose
安装环境: 按照requirement.txt
build.txt:
numpy
torch>=1.3
mminstall.txt:
mmcv-full>=1.3.8
mmdet>=2.14.0
mmtrack>=0.6.0
runtime.txt:
chumpy
dataclasses;python_version==’3.6’
json_tricks
matplotlib
munkres
numpy
opencv-python
pillow
scripy
torchvision
xtcocotools>=1.8tests.txt:
coverage
flake8
interrogate
isort==4.3.21
pytest
pytest-runner
smplx>=0.1.28
xdoctest>=0.10.0
yapf
数据集准备:
https://github.com/ViTAE-Transformer/ViTPose/blob/main/docs/en/tasks/2d_body_keypoint.md
可以选择COCO/MPII/MPII-TRB/AIC/CrowdPose/OCHuman/MHP,项目代码里有相应的处理脚本
数据集根目录放到MMPOSE/data下
以COCO数据为例,下载2017 Train/Val,并按照如下目录组织结构:
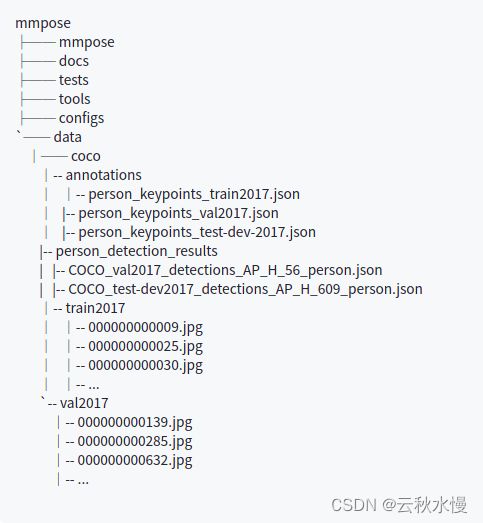
选择想要训练的Model: ViTPose-B/ViTPose-L/ViTPose-H,找到对应的config (下图config) 并修改data_root。(也可修改训练参数)
下载对应的预训练模型(下图Onedrive)
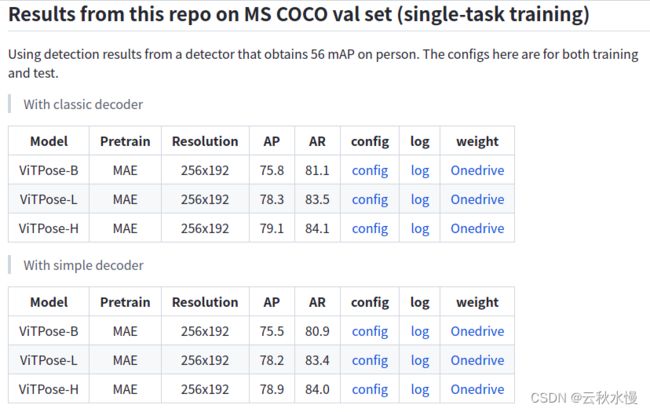
开始训练:
单机训练
bash tools/dist_train.sh <Config文件> <GPU数量> --cfg-options model.pretrained=<预训练模型> --seed 0
多机训练
python -m torch.distributed.launch --nnodes <服务器数量> --node_rank <Rank of Machine> --nproc_per_node <每台服务器的GPU数量> --master_addr <Master IP> --master_port <Master Port> tools/train.py <Config文件> --cfg-options model.pretrained=<预训练模型> --launcher pytorch --seed 0
推理:
bash tools/dist_test.sh <Config 文件> <Checkpoint 文件> <NUM 数量>
3. 点云目标检测
(1) centerpoint
代码: https://github.com/tianweiy/CenterPoint
安装环境:https://github.com/tianweiy/CenterPoint/blob/master/docs/INSTALL.md

本服务器环境是:
cuda113
pytorch:
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=11.3 -c pytorch -c conda-forge
spconv:
pip install spconv-cu113
报错:
error: ‘AT_CHECK’ was not declared in this scope
在编译deform_conv时遇到问题:error: ‘AT_CHECK’ was not declared in this scope错误原因:AT_CHECK is deprecated in torch 1.5 高版本的pytorch不再使用AT_CHECK,而是使用
TORCH_CHECK。
数据集准备:

在Centerpoint/路径下,建data/,然后建立软链接:
mkdir data && cd data
ln -s NUSCENES_DATASET_ROOT nuScenes
Create data:
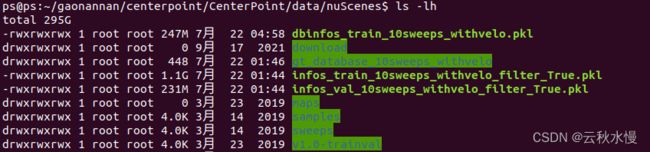
python -m ipdb tools/create_data.py nuscenes _data_prep --root_path=data/nuScenes --version="v1.0-trainval" --nsweeps=10
得到:
CenterPoint的环境配置error大全https://blog.csdn.net/weixin_44398263/article/details/121587115
开始训练:
CONFIG_PATH:要使用哪个模型
python -m torch.distributed.launch --nproc_per_node=4 ./tools/train.py CONFIG_PATH
python -m torch.distributed.launch --nproc_per_node=3 ./tools/train.py ./configs/nusc/voxelnet/nusc_centerpoint_voxelnet_0075voxel_dcn.py
python ./tools/train.py ./configs/nusc/voxelnet/nusc_centerpoint_voxelnet_0075voxel_dcn.py
# python ./tools/train.py CONFIG_PATH
报错:
ERROR: recursion is detected during loading of “cv2” binary> extensions. Check OpenCV installation
解决方法,卸载原来的opencv-python(4.6)
重装了低版本的opencv-python
pip install opencv-python==4.5.1.48