【论文笔记 - 图像生成 - CVPR2022】Self-supervised Correlation Mining Network for Person Image Generation
Ref: 1.原论文

人物图像生成的目的是对源图像进行非刚性变形,通常需要未对齐的数据对进行训练。 近年来,自监督方法通过将解耦的表征融合在一起进行 self-reconstruction,在这一领域展现出了广阔的前景。 然而,现有的方法存在以下几点问题,
-
解耦后的特征在特征空间中是对齐的,这种自监督方法无法为空间变换提供足够的监督。
-
先前的特征融合方法(如拼接或 MUSTGAN 中的统计信息迁移)是全局操作,很难利用空间相关信息。
-
由于在单姿态尺度内的自我监督训练过程,模型缺乏对不可见区域的先验知识,这就限制了根据半身人体来推算合理的全身人体的能力(测试阶段)。
因此,本文提出了一种自监督相关性挖掘网络(Self-supervised Correlation Mining Network,SCMNet),将分解风格编码器(Decomposed Style Encoder,DSE)和相关挖掘模块(Correlation Mining Module,CMM)两个协同模块集成在一起,在特征空间中重新排列源图像。 具体来说,
-
首先,DSE 在特性级别创建未对齐的对,即提取语义感知的解耦风格特征,与相应的姿态特征组成 unaligned pairs。基于此,源图像本身可以监督空间特征变形。
-
然后,CMM 利用解耦特征对之间的空间相关性,即计算特征对相应位置之间的两两相关性,建立密集的空间相关场。基于此,模型可以通过空间重新排列风格特征的位置,对齐这些解耦特征。
-
最后,一个翻译模块将重新排列的特征转换为真实的结果。
-
同时,为了提高跨尺度姿态变换的保真度,提出了一种基于图的 Body Structure retention(BSR) 损失,在半身人体到全身生成过程中保持合理的身体结构。
方法
Disentangled Feature Encoding
姿态和风格两个分支分别进行编码,
Pose Encoding
常规的下采样编码器,来从姿态骨架 P 中提取特征 F p F_p Fp,由于 F p F_p Fp 是全局编码,其结构本质上与源图像 I 是对齐的,
Decomposed Style Encoding
与全局编码相比,DSE 模块可以根据不同区域将复杂流形中的人物图像 I 嵌入到特征空间中。和以往的一些工作一样,需要用到人体解析图,分为8个部分,然后再分别对每一部分进行编码,最后 concat 所有的特征得到解耦风格特征 F s F_s Fs。
此外,为了消除固定的连接顺序所带来的限制,提出了一个跨通道融合(Cross Channel Fusion,CCF)模块,通过从不同的语义区域中选择所需的语义特征来赋予每个位置丰富的信息。在结构上,CCF 模块设计简洁,由两个 1 × 1 1×1 1×1 卷积块组成。
作者对风格编码器的输出进行了可视化,全局编码器的信号强度分布清晰地反应了结构信息,而 DSE 分布相对平坦,表明结构信息已经退化。

Correlation based Feature Merging
编码过程,得到了解耦的特征 F s F_s Fs 和 F p F_p Fp,将它们分别 reshape 成,
[ F i ( 1 ) , F i ( 2 ) , ⋯ , F i ( h w ) ] ∈ R C × H W \left[F_{i}(1), F_{i}(2), \cdots, F_{i}(h w)\right] \in \mathbb{R}^{C \times H W} [Fi(1),Fi(2),⋯,Fi(hw)]∈RC×HW
其中,i 为 p 或者 s, F i ( j ) F_i(j) Fi(j) 就表示特征图中第 j 个位置的语义信息,
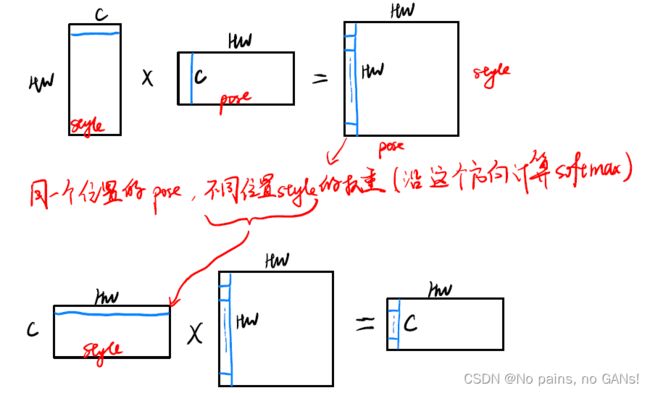
下图中,展示了 CMM 的计算过程,

具体来说,每个位置的 F s ( i ) F_s(i) Fs(i) 作为 query 来检索相关的 F p ( j ) F_p(j) Fp(j)(作为key),也就是说要与每个位置的 F p F_p Fp 来计算相关性,通过矩阵来描述的话,就是 ( F s ) T × F p (F_s)^T \times F_p (Fs)T×Fp 得到 H W × H W HW \times HW HW×HW 的密集空间关系矩阵 C,那么就可以重新分配风格特征 value 了。
C i j = exp ( s i j ) ∑ i = 1 h w exp ( s i j ) s i j = F ˉ s ( i ) F ˉ p ( j ) ∥ F ˉ s ( i ) ∥ ∥ F ˉ p ( j ) ∥ \begin{aligned} C_{i j} &=\frac{\exp \left(s_{i j}\right)}{\sum_{i=1}^{h w} \exp \left(s_{i j}\right)} \\ s_{i j} &=\frac{\bar{F}_{s}(i) \bar{F}_{p}(j)}{\left\|\bar{F}_{s}(i)\right\|\left\|\bar{F}_{p}(j)\right\|} \end{aligned} Cijsij=∑i=1hwexp(sij)exp(sij)=∥∥Fˉs(i)∥∥∥∥Fˉp(j)∥∥Fˉs(i)Fˉp(j)
对 F s F_s Fs 中所有位置的特征计算加权平均和,重新排列特征,也就是上图中 Weighted Summation 操作,
F s ∗ ( i ) = ∑ j = 1 h w c i j F s ( j ) , i ∈ [ 1 , h w ] F_{s}^{*}(i)=\sum_{j=1}^{h w} c_{i j} F_{s}(j), i \in[1, h w] Fs∗(i)=∑j=1hwcijFs(j),i∈[1,hw]
(
没有代码,个人推测
矩阵的每列代表同一个位置的 pose 编码与不同位置 style 编码的相似度,沿列计算 softmax,那么每一列就是一组不同位置 style 的权重,
计算耦合结果时, F s × C F_s \times C Fs×C,那么结果中的每一列就是风格的加权和,
下图所示,
)
Aligned Feature Translation
采用了 U-net 的网络结构,更好的保护结构信息。
Objective Functions
L total = α a d v L a d v + α r e c L rec + α perc L perc + α style L style + α graph L g r a p h \mathcal{L}_{\text {total }} =\alpha_{a d v} \mathcal{L}_{a d v}+\alpha_{r e c} \mathcal{L}_{\text {rec }}+\alpha_{\text {perc }} \mathcal{L}_{\text {perc }} +\alpha_{\text {style }} \mathcal{L}_{\text {style }}+\alpha_{\text {graph }} \mathcal{L}_{g r a p h} Ltotal =αadvLadv+αrecLrec +αperc Lperc +αstyle Lstyle +αgraph Lgraph
除了常规的损失函数外,作者还设计了 Body Structure Retaining 损失,通过约束身体各部位之间的语义关系来赋予不可见区域的先验知识。如下图所示,

作者设计了一个图生成器来建立语义关系,使用预训练的 VGG 网络和区域平均池化层得到图 M,其中节点表示每个区域的风格,连接线表示区域之间的相似性。
由于训练过程是自监督的,模型在进行姿态变换时,无法对未知区域进行合理的推测。应用 BSR 损失进行训练,使输出的人物图像保持合理的结构,有利于半身到全身的转化。
L g r a p h = ∥ M ( I , S ) − M ( I ^ , S ) ∥ 1 \mathcal{L}_{g r a p h}=\|\mathbb{M}(I, S)-\mathbb{M}(\hat{I}, S)\|_{1} Lgraph=∥M(I,S)−M(I^,S)∥1
(就是说,作者认为各个人体部分的语义是有一定的关系的,在重构的过程中,希望模型能够学习到利用这个关系,这样在测试的时候,就可以利用这个关系来推测不可见区域的信息)